Query Databases Using Java Streams
In this article, you will learn how you can write pure Java applications that are able to work with data from an existing database.
Join the DZone community and get the full member experience.
Join For FreeQuery Databases Using Java Streams
In this article, you will learn how you can write pure Java applications that are able to work with data from an existing database without writing a single line of SQL (or similar languages like HQL) and without spending hours putting everything together. After your application is ready, you will learn how to accelerate latency performance with a factor of more than 1,000 using in-JVM-acceleration by adding just two lines of code.
Throughout this article, we will use Speedment, which is a Java stream ORM that can generate code directly from a database schema and that can automatically render Java Streams directly to SQL, allowing you to write code in pure Java.
You will also discover that data access performance can increase significantly by means of an in-JVM-memory technology where Streams are run directly from RAM.
Example Database
We will use an example database from MySQL named Sakila. It has tables called Film, Actor, Category, and so on and can be downloaded for free here.
Step 1: Connect to Your Database
We will start to configure the pom.xml file by using the Speedment Initializer that you can find here. Press "download," and you will get project folder with a Main.java file generated automatically.
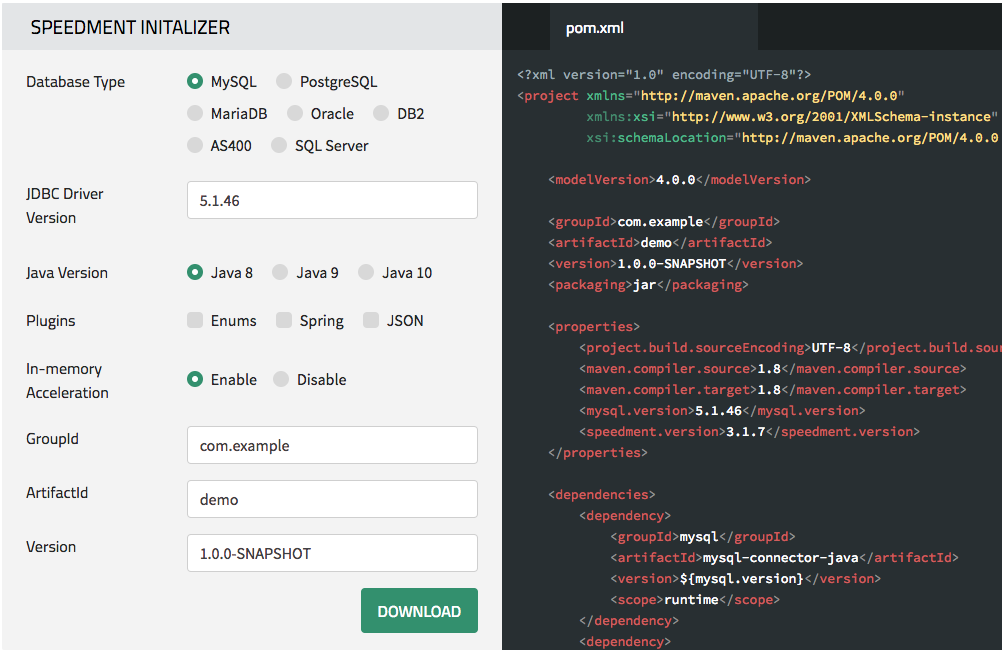
Next, unpack the project folder zip file, open a command line, and go to the unpacked folder (where the pom.xml file located).
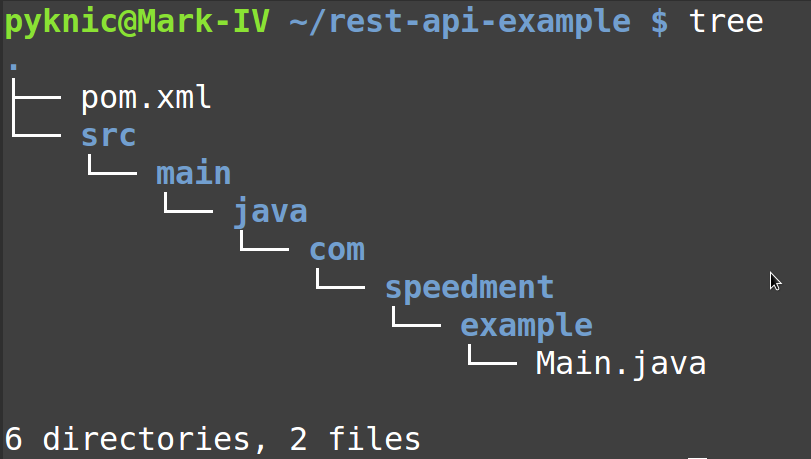
Then, enter the following command:
mvn speedment:toolThis will launch the Speedment tool and prompt you for a license key. Select "Start Free," and you will get a license automatically and for free. Now you can connect to the database and get started:

Step 2: Generate Code
Once the schema data has been loaded from the database, the complete Java domain model can be generated by pressing the "Generate" button.
This will only take a second or two.
Step 3: Write the Application Code
Together with the domain model in step 2, a builder for the Speedment instance was automatically generated. Open the Main.java file and replace the code in the main() method with this snippet:
SakilaApplication app = new SakilaApplicationBuilder()
.withPassword("sakila-password") // Replace with your own password
.build();Next, we will write an application that will print out all films. Admittedly, it's a small application, but we will improve it over the course of this article.
// Obtains a FilmManager that allows us to
// work with the "film" table
FilmManager films = app.getOrThrow(FilmManager.class);
// Create a stream of all films and print
// each and every film
films.stream()
.forEach(System.out::println);Isn't that simple?
When run, the Java stream will be automatically rendered to SQL under the hood. In order to actually see the SQL code rendered, modify our application builder and enable logging using the STREAM log type:
SakilaApplication app = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withLogging(ApplicationBuilder.LogType.STREAM)
.build();This is how the SQL code looks like when you run the application:
SELECT
`film_id`,`title`,`description`,`release_year`,
`language_id`,`original_language_id`,`rental_duration`,`rental_rate`,
`length`,`replacement_cost`,`rating`,`special_features`,`last_update`
FROM
`sakila`.`film`,
values:[]The SQL code rendered might differ depending on the database type you have selected (e.g. MySQL, MariaDB, PostgreSQL, Oracle, MS SQL Server, DB2, AS400 etc.). These variations are automatic.
The code above will produce the following output (shortened for brevity):
FilmImpl { filmId = 1, title = ACADEMY DINOSAUR, ..., length = 86, ... }
FilmImpl { filmId = 2, title = ACE GOLDFINGER, ..., length = 48, ...}
FilmImpl { filmId = 3, title = ADAPTATION HOLES, ..., length = 50, ...}
...Step 4: Using Filters
Speedment streams support all Stream operations including filters. Suppose we want to filter out only those films that are longer than 60 minutes. This can be accomplished by adding this line of code to our application:
films.stream()
.filter(Film.LENGTH.greaterThan(60))
.forEach(System.out::println);Rendered SQL:
SELECT
`film_id`,`title`,`description`,`release_year`,
`language_id`,`original_language_id`,`rental_duration`,`rental_rate`,
`length`,`replacement_cost`,`rating`,`special_features`,
`last_update`
FROM
`sakila`.`film`
WHERE
(`length` > ?),
values:[60]Generated output:
FilmImpl { filmId = 1, title = ACADEMY DINOSAUR, ..., length = 86, ... }
FilmImpl { filmId = 4, title = AFFAIR PREJUDICE, ..., length = 117, ...}
FilmImpl { filmId = 5, title = AFRICAN EGG, ... length = 130, ...}Filters can be combined to create more complex expressions as depicted hereunder:
films.stream()
.filter(
Film.LENGTH.greaterThan(60).or(Film.LENGTH.lessThan(30))
)
.forEach(System.out::println);This will return all films that are either shorter than 30 minutes or longer than one hour. Check your log files and you will see that also this Stream is rendered to SQL.
Step 5: Define the Order of the Elements
By default, the order in which elements appear in a stream is undefined. To define a specific order, you apply a sorted() operation to a stream like this:
films.stream()
.filter(Film.LENGTH.greaterThan(60))
.sorted(Film.TITLE)
.forEach(System.out::println);Rendered SQL:
SELECT
`film_id`,`title`,`description`,`release_year`,
`language_id`,`original_language_id`,`rental_duration`,`rental_rate`,
`length`,`replacement_cost`,`rating`,`special_features`,
`last_update`
FROM
`sakila`.`film`
WHERE
(`length` > ?)
ORDER BY
`length` ASC,
values:[60]Generated output:
FilmImpl { filmId = 77, title = BIRDS PERDITION,..., length = 61,...}
FilmImpl { filmId = 106, title = BULWORTH COMMANDMENTS,..., length = 61,}
FilmImpl { filmId = 114, title = CAMELOT VACATION,..., length = 61,..}
...You can also compose multiple sorters to define the primary order, the secondary order and so on.
films.stream()
.filter(Film.LENGTH.greaterThan(60))
.sorted(Film.LENGTH.thenComparing(Film.TITLE.reversed()))
.forEach(System.out::println);This will sort the film elements by LENGTH order (ascending) and then by TITLE order (descending). You can compose any number of fields.
NB: If you are composing two or more fields in ascending order, you should use the field's method.comparator(). I.e. sorted(Film.LENGTH.thenComparing(Film.TITLE.comparator())) rather than just sorted(Film.LENGTH.thenComparing(Film.TITLE))
Step 6: Page and Avoid Large Object Chunks
Often, one wants to page results to avoid working with unnecessary large object chunks. Assuming we want to see 50 elements per page, we could write the following generic method:
private static final int PAGE_SIZE = 50;
public static <T> Stream<T> page(
Manager<T> manager,
Predicate<? super T> predicate,
Comparator<? super T> comparator,
int pageNo
) {
return manager.stream()
.filter(predicate)
.sorted(comparator)
.skip(pageNo * PAGE_SIZE)
.limit(PAGE_SIZE);
}This utility method can page ANY table using ANY filter and sort it in ANY order.
For example, calling:
page(films, Film.LENGTH.greaterThan(60), Film.TITLE, 3)will return a stream of films that are longer than 60 minutes and that are sorted by title showing the third page (i.e. skipping 150 films and showing the following 50 films).
Rendered SQL:
SELECT
`film_id`,`title`,`description`,`release_year`,
`language_id`,`original_language_id`,`rental_duration`,`rental_rate`,
`length`,`replacement_cost`,`rating`,`special_features`,
`last_update`
FROM
`sakila`.`film`
WHERE
(`length` > ?)
ORDER BY
`title` ASC
LIMIT ? OFFSET ?,
values:[60, 50, 150]Generated output:
FilmImpl { filmId = 165, title = COLDBLOODED DARLING, ... length = 70,...}
FilmImpl { filmId = 166, title = COLOR PHILADELPHIA, ..., length = 149... }
FilmImpl { filmId = 167, title = COMA HEAD, ... length = 109,...}
...Again, if we had used another database type, the SQL code would differ slightly.
Step 7: In-JVM-Memory Acceleration
Since you used the standard configuration in the Initializer, In-JVM-memory acceleration was enabled in your pom.xml file. To activate acceleration in your application, you just modify your initialization code like this:
SakilaApplication app = new SakilaApplicationBuilder()
.withPassword("sakila-password")
.withBundle(InMemoryBundle.class)
.build();
// Load data from the database into an in-memory snapshot
app.getOrThrow(DataStoreComponent.class).load();Now, instead of rendering SQL-queries, table streams will be served directly from RAM. Filtering, sorting, and skipping will also be accelerated by in-memory indexes. Both in-memory tables and indexes are stored off-heap so they will not contribute to Garbage Collection complexity.
On my laptop (Mac Book Pro, 15-inch, Mid 2015, 16 GB, i7 2.2 GHz), the query latency was reduced by a factor over 1,000 for streams where I counted films that matched a filter and on sorted streams compared to running against a standard installation of a MySQL database (Version 5.7.16) running on my local machine.
Summary
In this article, you have learned how easy it is to query existing databases using pure Java streams. You have also seen how you can accelerate access to your data using in-JVM-memory stream technology. Both the Sakila database and Speedment is free to download and use, so try it out for yourself.
Published at DZone with permission of Per-Åke Minborg. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments