Quick Start With Apache Livy
Learn how to get started with Apache Livy, a project in the process of being incubated by Apache that interacts with Apache Spark through a REST interface.
Join the DZone community and get the full member experience.
Join For FreeApache Livy is a project currently in the process of being incubated by the Apache Software Foundation. It is a service to interact with Apache Spark through a REST interface. It enables both submissions of Spark jobs or snippets of Spark code. The following features are supported:
Jobs can be submitted as pre-compiled jars, snippets of code, or via Java/Scala client API.
Interactive Scala, Python, and R shells.
Support for Spark 2.x and Spark1.x, Scala 2.10, and 2.11.
Doesn't require any change to Spark code.
Allows for long-running Spark Contexts that can be used for multiple Spark jobs by multiple clients.
Multiple Spark Contexts can be managed simultaneously — they run on the cluster instead of the Livy Server in order to have good fault tolerance and concurrency.
Possibility to share cached RDDs or DataFrames across multiple jobs and clients.
Secure authenticated communication.
The following image, taken from the official website, shows what happens when submitting Spark jobs/code through the Livy REST APIs:
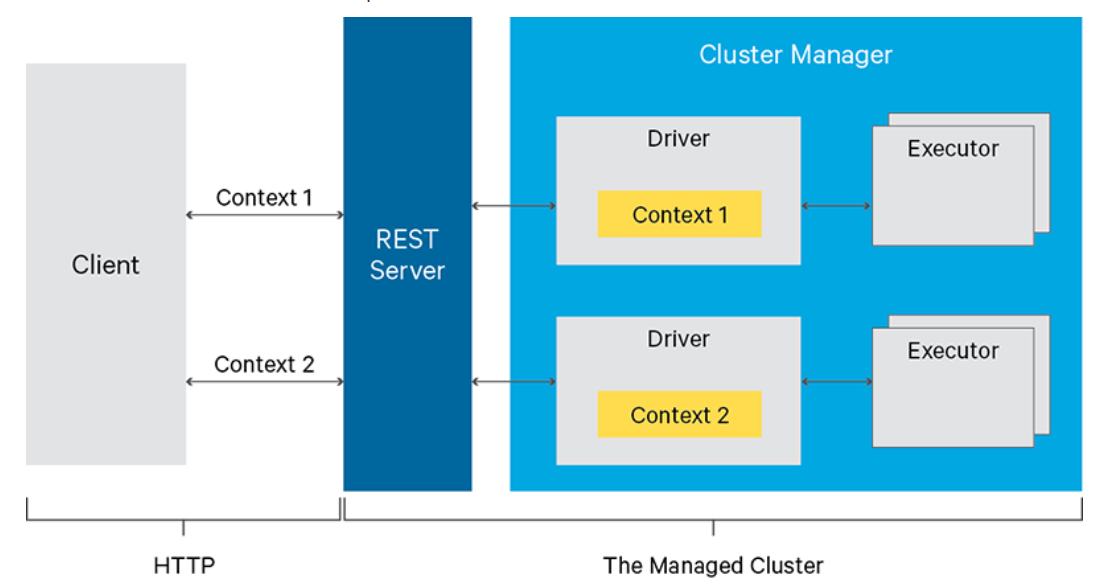
This article provides details on how to start a Livy server and submit PySpark code.
Prerequisites
The prerequisites to start a Livy server are the following:
The
JAVA_HOMEenv variable set to a JDK/JRE 8 installation.A running Spark cluster.
Starting the Livy Server
Download the latest version (0.4.0-incubating at the time this article is written) from the official website and extract the archive content (it is a ZIP file). Then setup the SPARK_HOME env variable to the Spark location in the server (for simplicity here, I am assuming that the cluster is in the same machine as for the Livy server, but through the Livy configuration files, the connection can be done to a remote Spark cluster — wherever it is). By default, Livy writes its logs into the $LIVY_HOME/logs location; you need to manually create this directory. Finally, you can start the server:
$LIVY_HOME/bin/livy-serverVerify that the server is running by connecting to its web UI, which uses port 8998 by default http://<livy_host>:8998/ui.
Using the REST APIs With Python
Livy offers REST APIs to start interactive sessions and submit Spark code the same way you can do with a Spark shell or a PySpark shell. The examples in this post are in Python. Let's create an interactive session through a POST request first:
curl -X POST --data '{"kind": "pyspark"}' -H "Content-Type: application/json" localhost:8998/sessionsThe kind attribute specifies which kind of language we want to use (pyspark is for Python). Other possible values for it are spark (for Scala) or sparkr (for R). If the request has been successful, the JSON response content contains the id of the open session:
{"id":0,"appId":null,"owner":null,"proxyUser":null,"state":"starting","kind":"pyspark","appInfo":{"driverLogUrl":null,"sparkUiUrl":null},"log":["stdout: ","\nstderr: "]}You can double-check through the web UI:
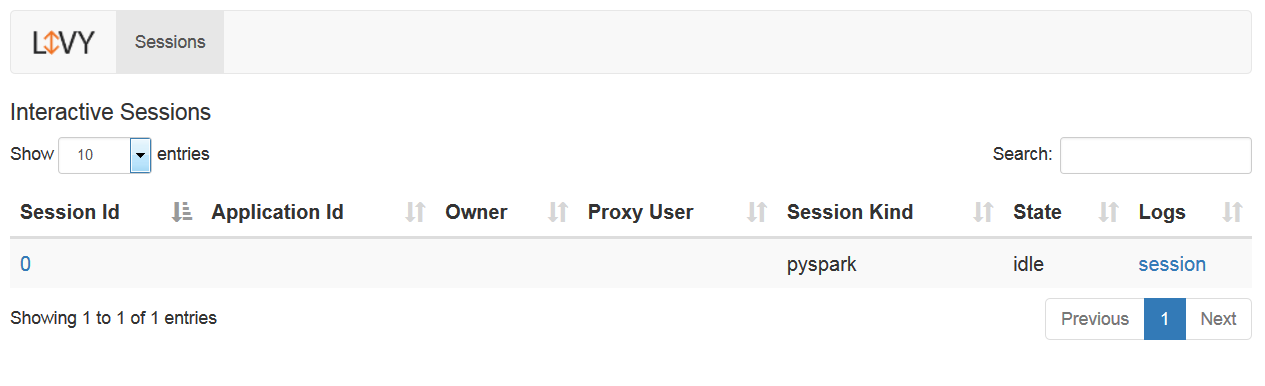
You can check the status of a given session any time through the REST API:
curl localhost:8998/sessions/ | python -m json.tool Let's execute a code statement:
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d '{"code":"2 + 2"}'
The code attribute contains the Python code you want to execute. The response of this POST request contains the id of the statement and its execution status:
{"id":0,"code":"2 + 2","state":"waiting","output":null,"progress":0.0}To check if a statement has been completed and get the result:
curl localhost:8998/sessions/0/statements/0If a statement has been completed, the result of the execution is returned as part of the response (data attribute):
{"id":0,"code":"2 + 2","state":"available","output":{"status":"ok","execution_count":0,"data":{"text/plain":"4"}},"progress":1.0}This information is available through the web UI, as well:
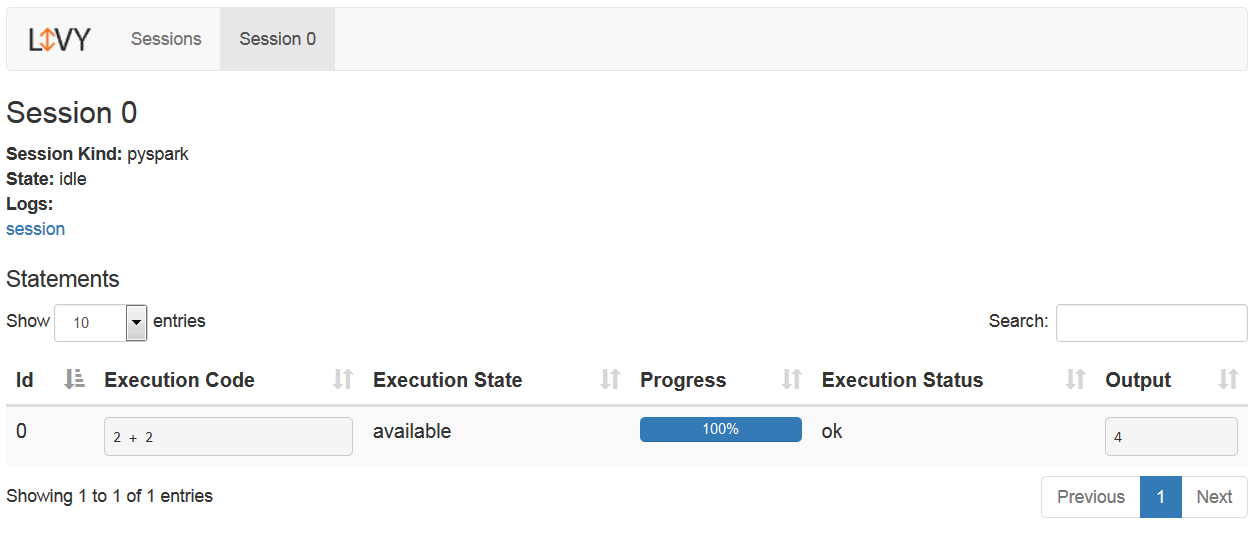
The same way, you can submit any PySpark code:
curl localhost:8998/sessions/0/statements -X POST -H 'Content-Type: application/json' -d'{"code":"sc.parallelize([1, 2, 3, 4, 5]).count()"}' 
When you're done, you can close the session:
curl localhost:8998/sessions/0 -X DELETE And that's it!
Opinions expressed by DZone contributors are their own.
Comments