RAG Architectures AI Builders Should Understand
Learn how retrieval, filtering, generation, and operations work together to deliver current, private, and verifiable answers instead of fluent guesses.
Join the DZone community and get the full member experience.
Join For FreeLarge language models are exceptionally good at producing fluent text. They are not, by default, good at staying current, respecting boundaries of private knowledge, or documenting the sources of an answer. That gap is exactly where most AI products fail: the demo looks impressive, but the system is not trustworthy when users rely on it.
Retrieval-augmented generation (RAG) closes the gap by designing an evidence path. Instead of letting the model “reason from memory,” you route the request through retrieval, enforce access rules, collect supporting sources, and then ask the model to answer from those sources with citations. In practice, RAG is less about prompting and more about engineering: a data pipeline, a contract, and an operational loop.
What RAG Means in Practice
At its simplest, RAG is two steps: retrieval finds evidence, and generation writes an answer constrained by that evidence.
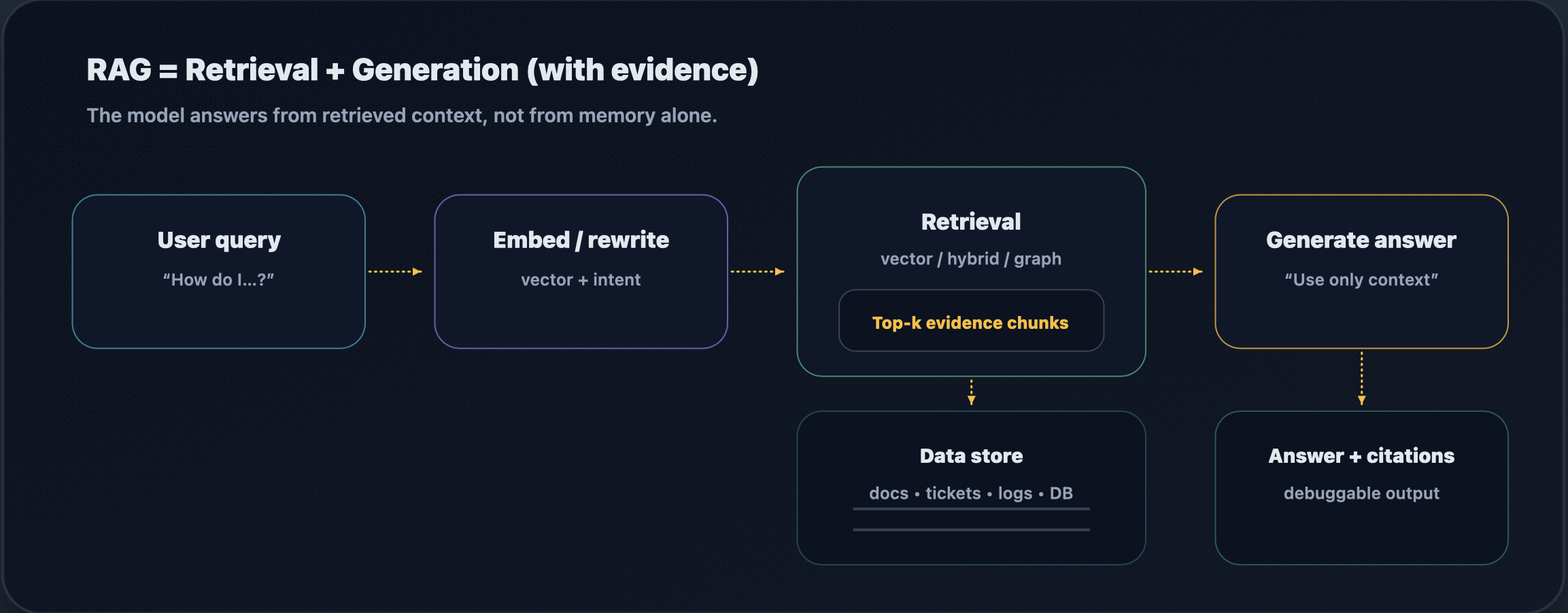
When you build RAG, you are designing the request path end-to-end: the system receives a question (often with conversation state and permissions), retrieves candidate evidence (chunks, entities, tickets, tables, logs), assembles context (dedupe, rank, filter, format, budget tokens), and produces an answer that is auditable (citations, traces, and metrics). That audit trail is the difference between “it answered” and “we can explain why it answered.”
Why RAG Is An Architecture (Not a Feature)
RAG exists because two things are true at the same time:
Retrieval is brittle. If you retrieve the wrong evidence, the answer will be wrong. If you retrieve a mixture of relevant and irrelevant chunks, the model often averages them into a plausible but incorrect response.
Generation is persuasive. Even with strong evidence, models can overgeneralize, skip qualifiers, or invent bridging statements. You need a prompting-and-citation contract that constrains behavior, plus guardrails to handle “no evidence” and “low confidence” cases.
Sound RAG systems solve both problems: high-recall, high-precision retrieval and grounded, scoped, testable generation.
Why Builders Use RAG
Training data ages quickly. Your product data, policies, tickets, and runbooks change daily. RAG is how you ship AI when answers must be current, private, and verifiable. It also creates trust at scale because you can inspect what was retrieved, from where, under which access rules, and how strongly the system believed each source was relevant.
A Practical Mental Model: The Parts That Decide Quality
Most RAG failures are predictable. The most significant levers are (1) how you chunk and label content (structure boundaries and metadata matter as much as size), (2) whether embeddings fit the domain and how you handle drift, (3) how you retrieve (vector, hybrid, multi-vector, or graph traversal), and (4) how you filter and rerank (precision gates). Once you have candidates, the remaining work is context assembly (dedupe, diversity, ordering, token budgeting), a generator contract (citations, refusal rules, “use only sources”), and operations (observability, evaluation, regression prevention, re-indexing, and security).
Core RAG Patterns
RAG is not one architecture. It is a family of patterns trading off latency, cost, control, and correctness. The best approach depends on what “failure” means in your product: a harmless mistake in a consumer chatbot is very different from a mistake in compliance, production troubleshooting, or internal decision-making.
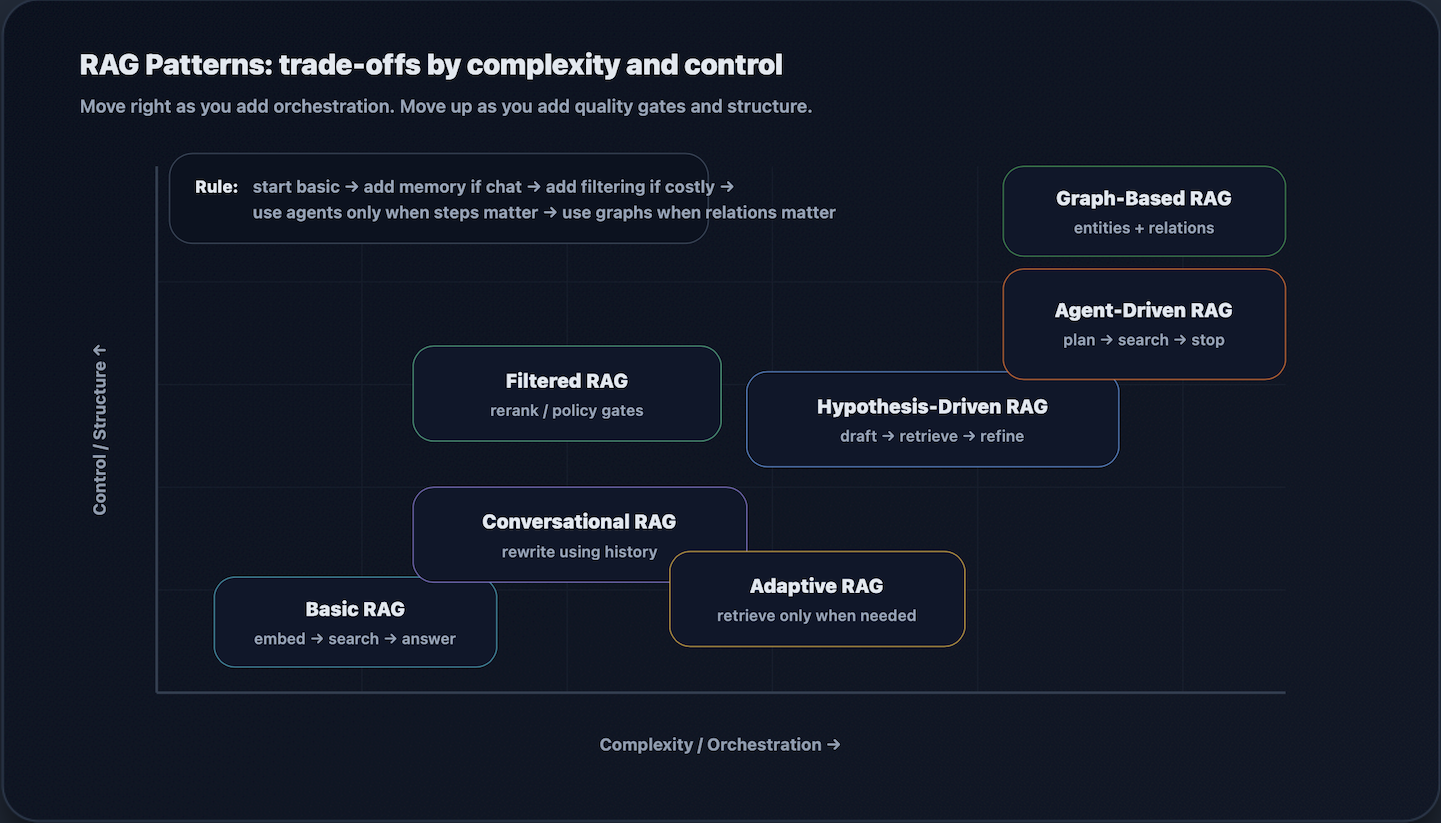
Pattern Comparison
| PATTERN | USE WHEN | CORE MOVE | EXTRA COMPONENTS | TYPICAL COST/LATENCY |
|---|---|---|---|---|
| Basic RAG | Single-shot Q&A, docs, FAQ | embed → top-k | chunking + vector index | low |
| Conversational RAG | Follow-ups depend on history | rewrite → retrieve | question rewriter | low–medium |
| Filtered RAG | Mistakes are expensive | retrieve → rerank/filter | reranker/filters | medium |
| Adaptive RAG | Retrieval sometimes hurts | route: no-retrieve vs retrieve | router + thresholds | low–medium |
| Hypothesis-Driven RAG | Queries are vague | draft → retrieve → refine | draft step + guardrails | medium |
| Agent-Driven RAG | Multi-step work matters | plan → retrieve → verify | planner + tools + stop rules | high |
| Graph-Based RAG | Relations drive meaning | traverse → explain | entity graph + traversal | medium–high |
Basic RAG
Basic RAG is the default starting point: embed the question, retrieve top-k chunks, assemble context, and generate with citations. It is the fastest to ship and the easiest to debug because the pipeline is simple and the failure modes are visible.
In practice, basic RAG breaks in three common ways. First, chunk mismatch: the answer spans multiple chunks, but you only retrieve one. Second, semantic near-miss: embeddings retrieve something “related” rather than “answering.” Third, context dilution: top-k includes noise, and the model blends it into the response. The most useful early metrics are straightforward: does the top 3 contain the correct source, does the answer cite at least one relevant chunk, and do you correctly refuse when evidence is missing?
Conversational RAG
Conversational RAG is basic RAG plus one critical step: rewrite the user’s message into a standalone retrieval query based on the chat history. Many follow-ups are not retrievable as written (for example: “what about rate limits?”, “does that apply to enterprise?”, “ok, and what should I do next?”). A rewrite turns pronouns and context into explicit terms: product names, constraints, IDs, and the specific decision being discussed.
The key is to treat rewriting as a retrieval tool, not a stylistic improvement. Keep the user’s intent and scope, but make the query searchable. The primary failure mode is rewrite drift: the rewritten query subtly changes the question. The fix is operational, not theoretical: log the raw question and the rewrite, evaluate both, and keep a rollback path when the rewriter behaves badly.
Filtered RAG
Filtered RAG assumes retrieval returns a mixture of good and bad evidence and adds a quality gate before generation. Instead of trusting the first top-k, you typically retrieve broader (for recall), rerank (for precision), apply policy and access controls, and only then generate from the remaining evidence.

This pattern is the default choice when errors are expensive, or the corpus is messy (e.g., duplicates, contradictory documents, or comments mixed with canonical policies). The subtle risk is over-filtering: you can end up with empty evidence. Your generator must treat “no evidence” as a first-class outcome, either refusing, asking a clarifying question, or escalating to a human workflow depending on product needs.
Adaptive RAG
Adaptive RAG asks a pragmatic question: should we retrieve at all? Some tasks are self-contained (summarizing pasted text, rewriting, formatting). Retrieval adds cost and noise. Adaptive systems route requests to “no retrieval,” “shallow retrieval,” or “deep retrieval,” often starting with simple rules and later transitioning to a learned router.
A reliable starting approach is to encode a small set of defensible heuristics: if the user pasted content, skip retrieval; if the question references private topics or internal entities, retrieve; if the system’s confidence is low, retrieve deeper and rerank. The win is cost control without sacrificing correctness for queries that actually require external evidence.
Hypothesis-Driven RAG
Hypothesis-driven RAG is designed for vague queries. It drafts a provisional interpretation (“this might be about X”), uses that draft to extract missing specifics, retrieves with a sharper query, and then produces a final, cited answer. This tends to work well when users do not know the proper vocabulary or when the domain is messy and intent matters more than keywords.
The risk is bias: the draft can steer retrieval in the wrong direction. A practical mitigation is to retrieve using both the original user query and the draft-derived query, then merge and dedupe evidence before generation.
Agent-Driven RAG
Agent-driven RAG treats retrieval as a plan rather than a single search. The system decomposes the task, issues multiple retrieval calls, reads the results, verifies gaps, and stops when sufficient evidence is obtained. This is powerful for multi-step analysis (compare options and recommend), troubleshooting (diagnose, propose a fix, and validate), and research with branching paths.
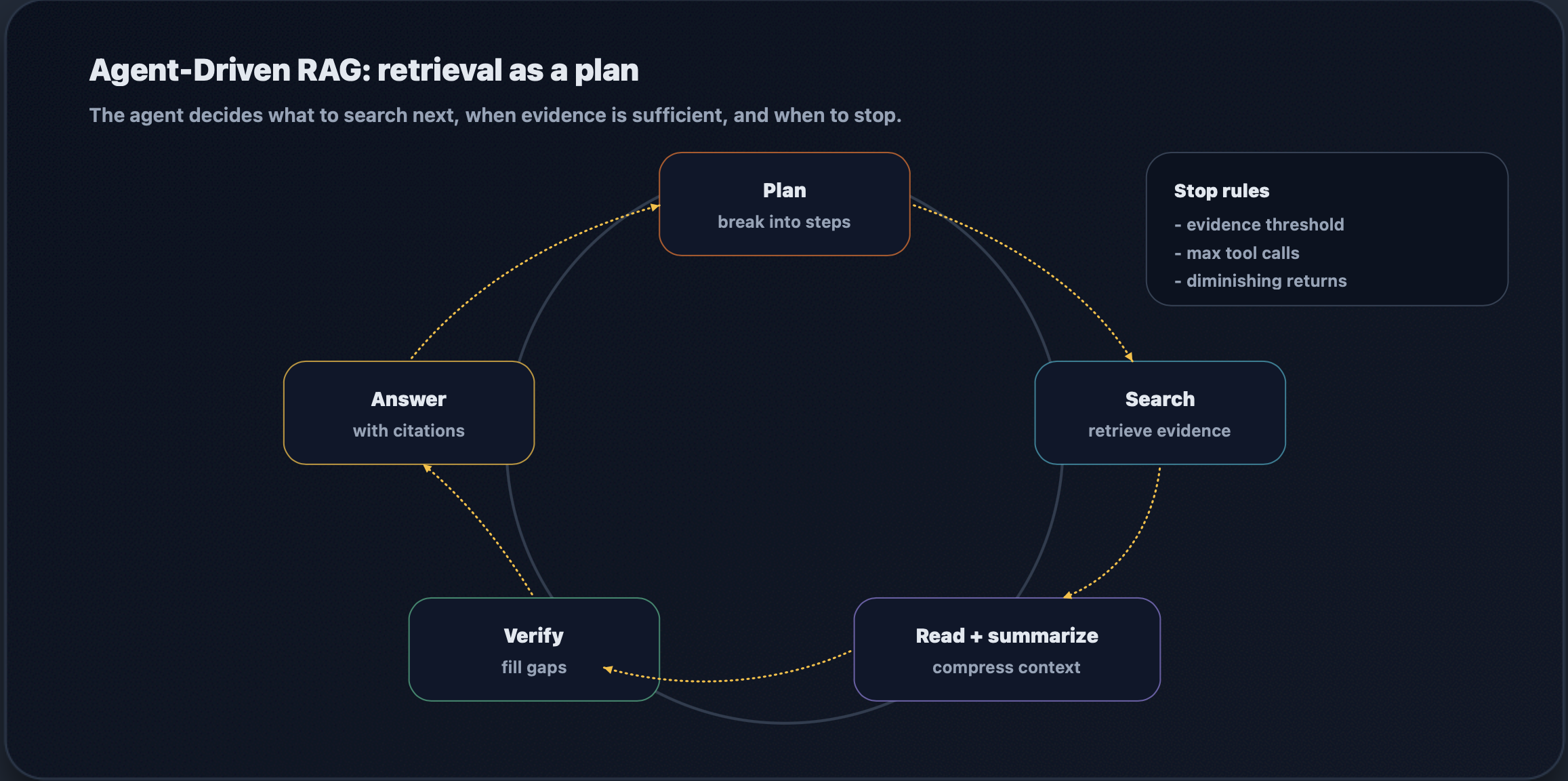
The most significant engineering requirement here is a stop condition. Without a clear budget and diminishing-returns check, agents spiral into cost. Production systems use explicit ceilings (max tool calls, max tokens, max latency) plus an evidence threshold (“new evidence is no longer changing the answer”) to end the loop predictably.
Graph-Based RAG
Graph-based RAG is suitable for domains where relationships carry meaning, such as ownership, dependencies, citations, policy applicability, and lineage. Instead of retrieving only by similarity, you retrieve by traversal: identify starting entities, walk edges (depends_on, owned_by, authored_by, cites), and collect a subgraph as evidence. The output is often stronger because the system can explain why a source is relevant, rather than merely that it is similar.
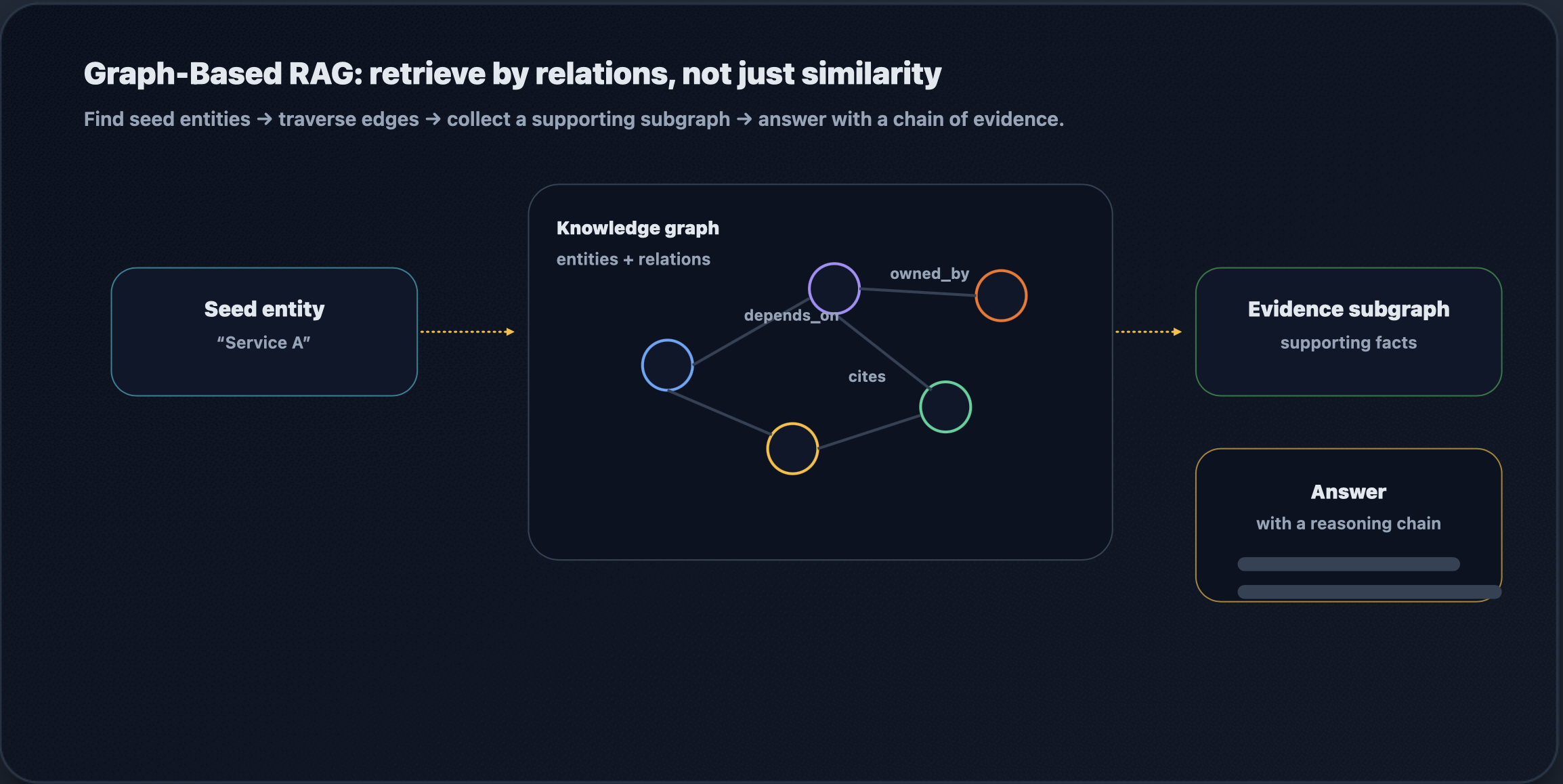
The operational risk is freshness and coverage. Graphs can encode bias and incompleteness. If edges are missing or stale, the reasoning chain breaks. You should monitor the graph update lag and validate coverage for the entity types that users ask about the most.
How to Pick the Right Pattern
Start with basic RAG and make it measurable. Add conversational rewriting only when follow-ups are standard. Add reranking and filtering when mistakes are expensive, or the corpus is noisy. Use adaptive routing when you have mixed workloads and need to control cost. Choose hypothesis-driven retrieval when queries are vague and ambiguous. Use agents when multi-step work is the product, not an implementation detail. Use graphs when relationships must be explained, and a similarity search alone can’t answer “why.”

Operational Reality: What Makes RAG Boring and Reliable
Most “RAG improvements” are operational. A working demo is not a working system. The difference is disciplined data preparation, evaluation, and observability.
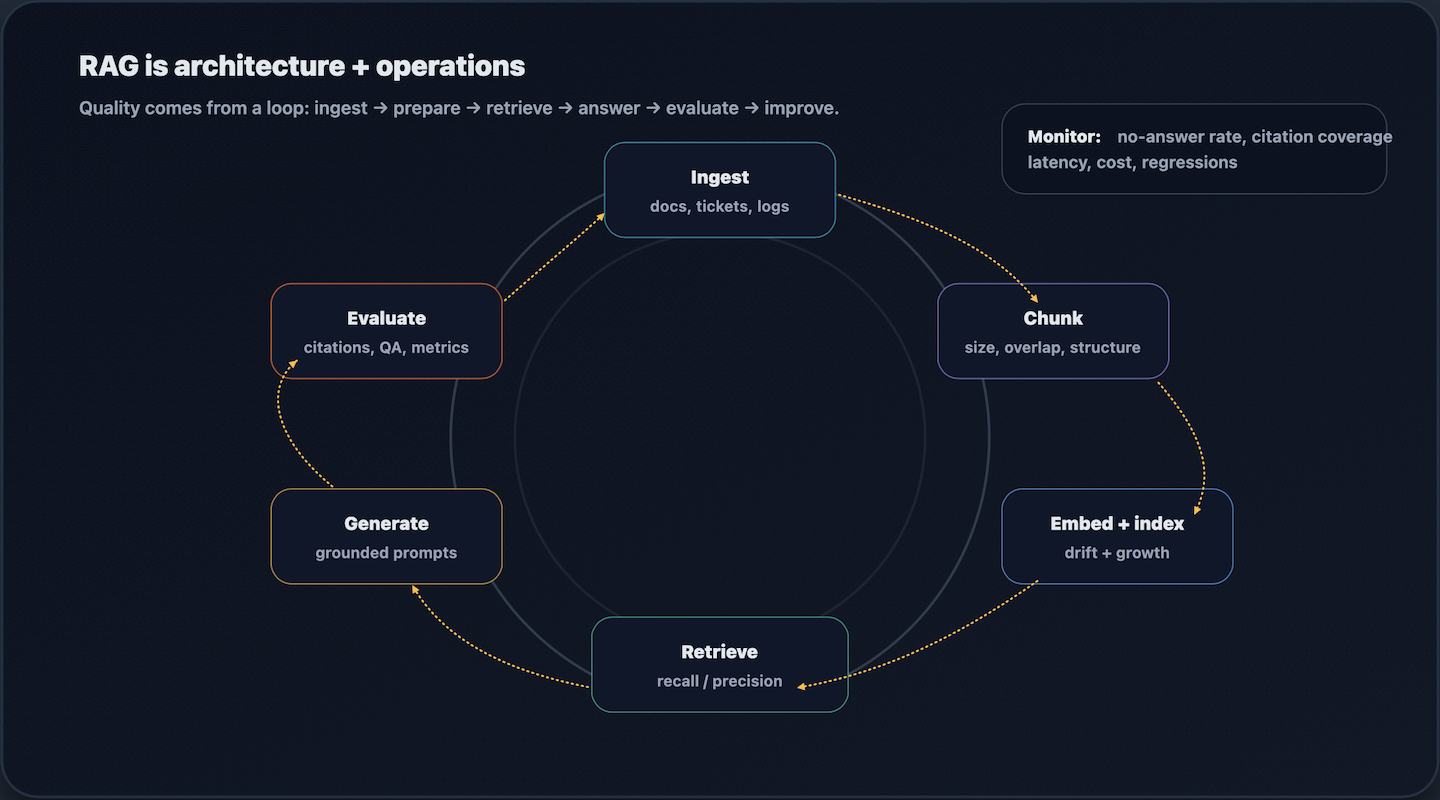
Treat operations as part of the architecture. The checklist below helps keep RAG systems stable as the corpus, traffic, and product expectations grow.
- Chunking and metadata: Tune chunk size and overlap per document type, preserve structure (headings, tables, code blocks), and retain metadata boundaries (source, version, ownership, access labels) so retrieval can be filtered and audited.
- Embedding drift and versioning: Drift is inevitable. Choose a re-embedding strategy (versioned embeddings, rolling updates, or periodic rebuilds) and record embedding/model versions in metadata so you can reproduce results and manage migrations.
- Index health: As the corpus grows, indexing latency and recall can change. Monitor both continuously and retune index parameters over time rather than treating them as “set and forget.”
- Evaluation and regressions: Maintain a fixed, curated evaluation set (queries, expected sources, and “should refuse” cases). Run regression evals after any change to chunking, embeddings, retrieval parameters, or reranking.
- Quality telemetry: Track citation coverage, empty-retrieval rate, reranker hit rate, and refusal quality so you can detect quality declines before users do.
- Security and access control: Enforce access control at retrieval time (not after generation) so unauthorized context never enters the prompt.
- End-to-end tracing: Log the whole trace from query → retrieved ids → scores → final context → answer so incidents are debuggable and improvements are measurable.
Conclusion
RAG shifts AI from storyteller to assistant by making evidence, permissions, and evaluation part of the product. The pattern you choose sets the tradeoffs you will live with: basic RAG optimizes for speed and debuggability, reranking and filtering by precision when stakes are higher, adaptive routing controls cost on mixed workloads, agents unlock multi-step work at the price of orchestration, and graphs add relational explainability when similarity alone is not enough.
Whatever you choose, reliability stems from operational discipline: structure-aware chunking, versioned embeddings, measurable retrieval quality, correctness of refusal, and end-to-end tracing from query to sources to answer. Please start with the simplest architecture that meets the requirements, make it observable and testable, and add complexity only when it yields a clear, repeatable improvement in outcomes.
References
www.neurondb.ai – Project Homepage
https://github.com/neurondb – Source code repo
Published at DZone with permission of Damil Shahzad. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments