RAG Applications with Vertex AI
Explore the possibilities of building custom RAG applications for greater control and flexibility with Vertex AI APIs, vector stores, and LangChain frameworks.
Join the DZone community and get the full member experience.
Join For FreeMost organizations experimenting with generative AI face a common bottleneck: their LLMs can chat nicely, but they do not consistently know the company’s own data. A customer wants to know a policy clause, or an engineer asks a question about a system diagram, and the model makes something up or simply provides an ambiguous, incomplete response.
This won’t work in industries such as healthcare, financial services, or insurance where accuracy is critical. What we want is the creative power of LLMs, but also the ability to reliably know our organization’s stuff. Here, we will explore how Retrieval-Augmented Generation (RAG) gives us those solutions.
Why should we use RAG?
Usually, LLMs predict the next likely word or sequence based on vast amounts of training data. However, the context of their knowledge will be frozen in time, based on the data available when they were trained. They also won’t have specific knowledge of data related to your particular business or use case.
When LLMs are used As-Is, straight out of the box, they lack access to:
- Up-to-date documentation
- Proprietary business information and internal documents
- Trusted sources for accurate citation
With the help of RAG, we can improve the reliability of LLMs by providing access to external data. This improves accuracy and timeliness.
Prerequisites
Access to Google Cloud Platform with the following services:
- Vertex AI
- Ranking API
- Document API
- Check Grounding API
- Vertex Vector Search
- Gemini 2.0 Flash
LangChain on Vertex AI:
As we already knew, LangChain relies on LLMs to reason. And it connects a language model to sources of context, such as prompts and contextual content.
Vertex AI is a fully managed AI platform developed by Google for building, training, and deploying ML models.
Vertex AI models are integrated with the LangChain Python SDK, which includes integrations for text, generating documents, summaries, answers, chat, and embeddings.
RAG Solution with Vertex AI and LangChain
Let’s explore the RAG solution using Vertex AI and LangChain, leveraging various APIs offered by GCP. Vertex AI offers flexible standalone APIs to help create our own solutions:
Ranking API:
- This API re-ranks initial search results based on how relevant they are to a query
- It helps to develop and deploy agents faster
- Provides context-aware semantic ranking that improves accuracy over embeddings or keyword search
Because of the above-mentioned features/advantages, Ranking API works well with Vertex AI Search to reorder responses before returning them to the user.
Check Grounding API:
- It helps in determining how grounded a given piece of text is in a given set of reference texts
- It can generate supporting citations from the reference text to indicate where the given text is supported by the reference texts
- It can assess the groundedness of responses from a RAG system
- Grounding requires that every claim in the answer candidate must be supported by one or more of the given facts. Here's an example:
- Tesla was founded by Elon Musk in 2003
- Although the founding year is correct, the founder’s information is incorrect here. So, this indicates that the whole claim is considered ungrounded
- In this version of the Check Grounding API, a sentence is considered a single claim
- The API also generates citations that show where the given text and reference texts disagree
- The citations generated by the API would help distinguish a hallucinated claim in the response from grounded claims
Vertex AI Search:
- Vertex AI Search is a managed service of Google Cloud Platform to build and deploy custom search engines supported by Generative AI. We can index, query, and search websites, structured data, databases, various storage systems, etc. This helps various developers to leverage AI, Semantic search, Embeddings, and RAG to create high-quality search experiences.
Document Layout AI Parser:
- Like every document parser, the layout parser also extracts document contents like texts, lists to analyze document layouts and creates context-aware chunks
- It can be integrated with other OCR tools for document (PDFs, images) extraction
Architecture
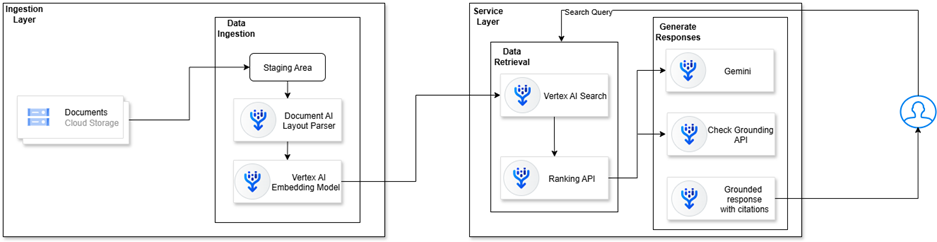
The architecture has two layers: Ingestion and Service. The ingestion layer shows how the documents are retrieved from Google Cloud Storage and processed into the staging area to process chunks of data using the Document AI Layout Parser and the Vertex AI Embedding model for semantic search.
The service layer shows how the data is retrieved and reranked as per the available artifacts and ground checks, and eventually provides the best possible responses with corresponding citations.
Ingestion Layer
In this layer, documents are read by machines, making them searchable and enabling appropriate reasoning.
Block 1: Cloud storage for Documents storage
Every AI-based pipeline starts with documents such as manuals, healthcare benefits, contracts, etc. Hence, Google Cloud Storage acts as a storage and staging area before the actual process begins
Block 2: Document AI Layout parser
Although raw documents are sources of truth, they are not helpful for machine learning. So, Google’s Document AI layout parser can easily extract information from the source files, keeping the extracted data that looks original, like tables, headers. It works best when documents already have a clear format
Block 3: Vertex AI Embedding to transform contents as Chunks
As LLMs cannot handle large documents in a single request, they must be broken into small chunks that can be sent in a single request. If the chunk is too small, this results in loss of context. If the chunk is too large, it might overflow the context model window, resulting in a failure or a truncated response from the model.
When dealing with chunks of text, this requires representation in a way that machines can semantically search, which is where Vertex text-embedding models come into play (e.g., text-embedding-004).
An embedding is just a vector of numbers that encodes the meaning of a piece of text. Each pair of texts lies close to the other when represented in vector space if they have similar meanings. Hence, the searchable dataset looks like: each chunk, embedding, and metadata (e.g., source doc ID + page number).
Service Layer:
After the data is ingested, indexed, and ready, the serving layer responds to live user queries. This is where the RAG plays an important role.
Block 1: Vertex Vector Search for Database Retrieval
When a user presents the query (i.e., “Does Plan X cover an MRI?”) this data is first embedded. Then it searches your index using Vertex Vector Search. This results top-k most relevant chunks. These chunks are not keyword matching, but based on semantic similarity - thus, “MRI scan” matches “magnetic resonance imaging.”
Block 2: Re-rank with Vertex AI Ranking API
Raw retrieval is not ideal; hence, the ranking step: the chunks are rescored using components of the context to determine the most relevant chunk to the user query.
This is invaluable when maintaining thousands of documents that are similar or have slight variations.
Block 3: Generating Answer with Gemini
And this gets us to the LLM. The top chunks will be repurposed with the original user query. This context is sent as input to Vertex Gemini 1.5 Pro. A sample prompt would be as such:
“Using the following context, respond per the user request; if the answer is no in the context, stick with do not know, again, the context is…. Query:”
Gemini will give a confidence level response, but as suggested above, you must rely on your selected chunks and don’t rely on their pretraining.
Block 4: Validation of Grounding
We will add reliability by passing the answer to the Vertex Check Grounding API. The API ensures that the user's generated answers are accurate within the context that they provided. If it is way off, we can eliminate, truncate, or repeat to reformulate.
Block 5: Answers with citations
In the end, you have a fascicle. Ideally, with source citations back to the corresponding provenance, so we can continue to trust, and compliance, believe it or not, always occurs because each user is labeled as trustable back to the originating source, and compliance can be maintained.
Conclusion
RAG is not just a trend. It's the foundational architecture that will allow generative AI to be viable in a real enterprise. With Vertex AI, there's no need to rebuild everything: the full suite of managed services exists for each step - document parsing, embedding, vector search, ranking, generation, and grounding.
Using the architecture above as an example, you could go from raw documents in cloud storage to grounded, citation-ready responses in a conversational interface. The real magic is in combining the ingestion and serving layers, and using the right APIs at the right times.
Enterprises that do this will be propelled beyond exploratory chatbot projects, into trusted AI assistants - systems that employees and customers can rely on to answer their most pressing questions.
Opinions expressed by DZone contributors are their own.
Comments