From RAG to RAG + RAV: A Practical Pipeline for Factual LLM Responses
RAG reduces hallucinations, RAV verifies each claim, and together they yield far more trustworthy LLM answers with optional corrections for accuracy.
Join the DZone community and get the full member experience.
Join For FreeRecently, I've been working on a project where getting the factual data right was absolutely critical. I’ll be honest, when I first wired up a retrieval-augmented generation (RAG) system, I thought I was mostly done with hallucinations. I had:
- A vector DB full of documents
- A decent embedding model
- A prompt that said "answer only using the context above."
And yet I still got answers that looked grounded but contained subtle factual errors: wrong years, swapped names, invented details that weren't in any source.
That’s what pushed me to build a second stage on top of RAG: retrieval-augmented verification (RAV). Now my pipeline looks like this:
RAG → LLM → RAV → correction (optional) → final answer
RAG tries to prevent hallucinations. RAV tries to detect and correct them, like taking a second opinion on the model's answer and feeding that back as constructive criticism.
I even gave RAV its own tools: a knowledge base, Wikipedia, and internet access, so it could independently double-check claims.
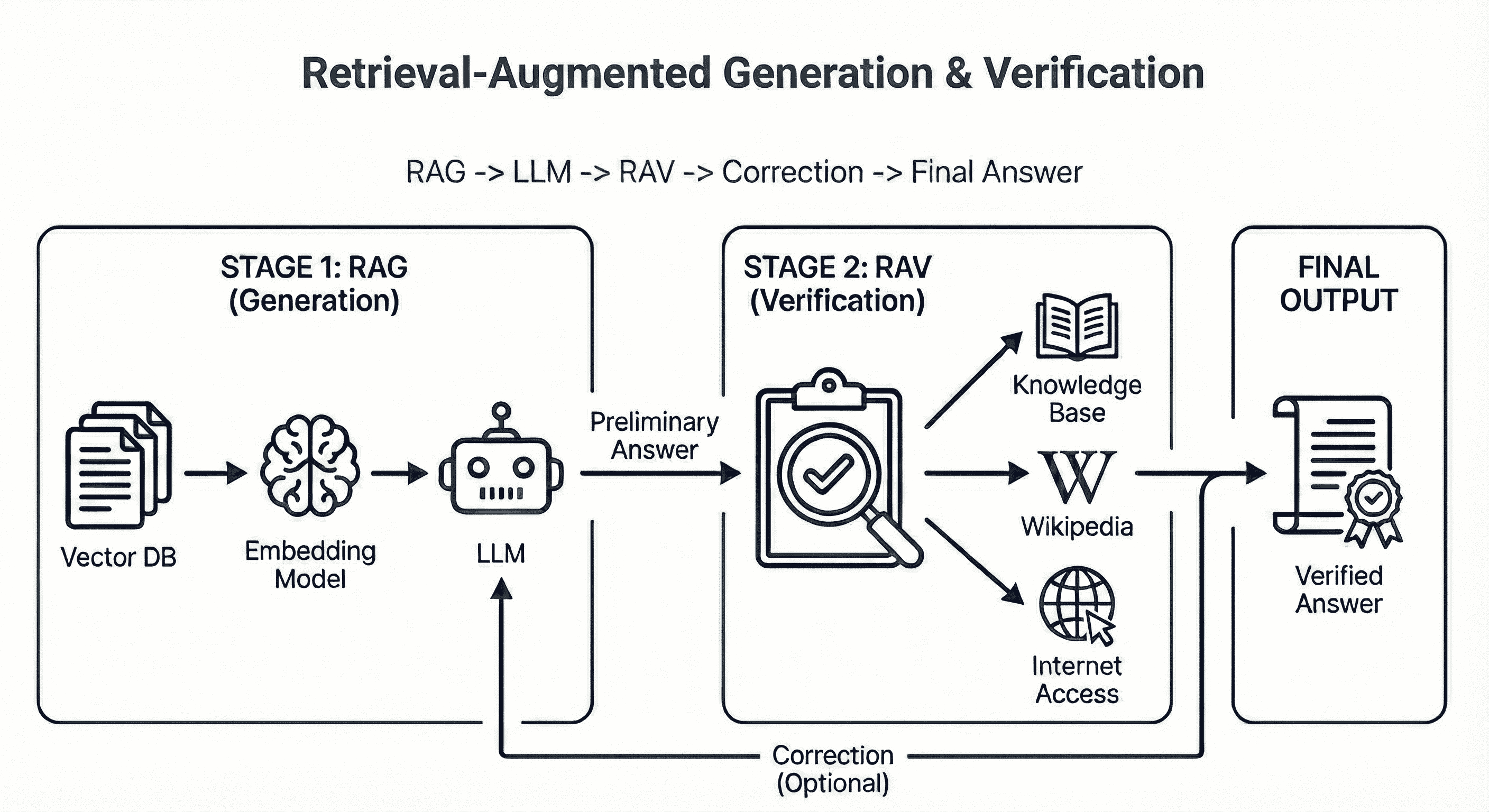
This article walks through how that pipeline works and what I learned along the way.
Why RAG Alone Wasn’t Enough
My original setup was a pretty standard RAG system:
- Take the user question.
- Retrieve relevant chunks from a vector DB (docs, wiki pages, notes, etc.).
- Feed those chunks into the LLM with instructions like "only answer using this context."
- Return the answer.
It felt solid. But when I started spot-checking answers, a few patterns showed up:
- The model filled gaps when the context was incomplete.
- It merged similar facts ("2018" and "2020" became “2019").
- It generalized beyond the context in ways that sounded reasonable but weren't actually supported.
The deeper issue: RAG only helps before generation. Once the model has produced text, I have no systematic way of asking:
"How much of this answer is actually backed by the knowledge base?"
So I decided to treat the LLM’s response as untrusted output and run a second stage that verifies it.
Step 1: RAG — Building the Baseline
I kept my RAG component relatively standard:
- Vector DB (e.g., FAISS/Milvus/pgvector) with:
- Title, text, metadata (source, date, domain).
- Retriever with:
- Top-k similarity search
- Optional keyword filters (e.g., only "docs", only "API references")
- Prompt template something like:
- "You are an assistant answering questions using the provided context. If the context does not contain the answer, say 'I don't know.' Do not invent facts. Context: …"
This alone improved things a lot compared to a raw LLM. But the remaining hallucinations are what RAV was built to catch.
Step 2: RAV — Extracting Factual Claims
The first challenge in RAV is to turn free text into units you can verify. In my pipeline, I don't start with another LLM call for this. I use a simple, deterministic NLP pass with spaCy. The idea is:
- Split the answer into sentences.
- Treat any sentence that mentions named entities (people, orgs, locations, dates, events) or numbers (years, counts, percentages, etc.) as a potential factual claim.
- Pass only those sentences into the verification step.
Here's the actual code I use right now:
import nltk
import spacy
nlp = spacy.load("en_core_web_sm")
def extract_claims(text: str):
doc = nlp(text)
claims = []
for sent in doc.sents:
has_entity = any(
ent.label_ in ["PERSON", "ORG", "GPE", "DATE", "EVENT"]
for ent in sent.ents
)
has_number = any(token.like_num for token in sent)
if has_entity or has_number:
claims.append(sent.text.strip())
return claimsExample:
Answer snippet: "The POLAR system was introduced at MobiCom 2023 and is primarily used for fine-grained RFID localization in crowded environments."
This will treat the entire sentence as a factual claim because it contains an event (MobiCom) and a date/number (2023). This approach has a few nice properties:
- It's cheap and fast — just one spaCy pass.
- It doesn't rely on another LLM, which keeps the verification pipeline more deterministic.
- It errs slightly on the side of over-including sentences, which is fine because the verification step will later decide which claims are actually supported or not.
You can always refine the heuristics later (add more entity types, filter out generic sentences, split long sentences into multiple claims), but this simple rule already works well as a first pass in my RAG+RAV pipeline.
Step 3: RAV — Retrieving Evidence Per Claim
For each claim, I run a mini-RAG process:
- Use the claim (or a rewritten query) as the search query.
- Retrieve top-k chunks from:
- My vector DB
- Wikipedia or the open web, via tools I wired into the system
def retrieve_evidence(claim: str) -> list[Document]:
# 1) Search internal KB
kb_docs = kb_retriever.search(claim, top_k=5)
# 2) Fallback: Wikipedia / web
wiki_docs = wikipedia_tool.search_and_fetch(claim, top_k=3)
return kb_docs + wiki_docsGiving RAV internet access was surprisingly helpful. It’s like telling a fact-checker: "If our internal docs don't answer this, go check Wikipedia or search the web."
Step 4: RAV — Scoring Each Claim (Verified/Uncertain/Hallucinated)
Once I had a list of claims and some evidence for each one, the next question was: "Does this evidence actually support the claim, or is the model making things up?"
I realized there are two main ways to do this:
- Invoke another LLM to read the claim + evidence and decide if it’s supported or not.
- Use cosine similarity between the claim and the retrieved content, and apply simple thresholds.
Both are valid, and which one you choose really depends on the complexity of the use case.
Option 1: LLM-as-Verifier (More Expressive, More Uncertainty)
You can absolutely ask a verifier model: "Given this claim and this evidence, is the claim supported, contradicted, or unknown?"
This is powerful for very nuanced domains (legal reasoning, multi-step logic, conflicting sources, etc.). But there’s a catch: you’re introducing another LLM, which means:
- Another surface for hallucinations
- More latency and cost
- More things to test and monitor
For a system whose whole point is to reduce hallucinations, I wasn't super excited about adding another generative model into the loop unless I really had to.
Option 2: Cosine Similarity (Simpler, More Deterministic)
For my project, I started with a much simpler approach, and it turned out to be good enough:
- Embed the claim and each evidence chunk.
- Compute cosine similarity between the claim embedding and each chunk embedding
- Use thresholds to decide:
- High similarity → SUPPORTED
- Medium similarity → UNCERTAIN
- Low similarity → UNSUPPORTED / likely hallucinated
This keeps the verification step:
- Cheap (one embedding model, no extra LLM calls)
- Deterministic-ish (same input → same score)
- Conceptually simple to reason about
from sentence_transformers import SentenceTransformer, util
embedder = SentenceTransformer("all-MiniLM-L6-v2")
def score_claim_cosine(claim, evidence_docs, support_thresh=0.65, unsure_thresh=0.45):
texts = [claim] + [doc.text for doc in evidence_docs]
embeddings = embedder.encode(texts, convert_to_tensor=True)
claim_emb = embeddings[0]
doc_embs = embeddings[1:]
sims = util.cos_sim(claim_emb, doc_embs)[0] # similarities to each doc
max_sim = float(sims.max())
if max_sim >= support_thresh:
label = "SUPPORTED"
elif max_sim >= unsure_thresh:
label = "UNCERTAIN"
else:
label = "UNSUPPORTED"
return {
"label": label,
"confidence": max_sim, # treat similarity as a crude confidence
}My general rule of thumb is:
Start with cosine similarity. If that doesn’t give you acceptable factuality, then consider an LLM-based verifier.
Step 5: Correction — Feeding Back Constructive Criticism
The final piece is what to do when RAV flags issues. I didn’t want to throw away the entire answer, because often, most of it is correct and just one or two claims are off. So my correction loop looks like this:
- Gather all claims with:
label != SUPPORTED- Or
confidence < 0.6(tunable)
- Build a feedback prompt:
"Here is your previous answer.
The following claims seem unsupported or contradicted by our sources:
– Claim 1: …
– Claim 2: …Please revise ONLY the parts of the answer that depend on these claims.
Keep all other correct information.
If the information is truly unknown, explicitly say that it is unknown." -
Ask the LLM to produce a revised answer.
The result is very much like a human second draft: wrong parts softened or removed, correct parts preserved, and uncertainty surfaced instead of being hidden.
Trade-Offs and Practical Considerations
A few lessons from actually running this in practice:
- Latency and cost:
- RAV adds extra model calls and retrieval steps.
- For high-risk domains, the trade-off is worth it. For low-risk casual chat, probably not.
- Knowledge base quality matters:
- If your knowledge base is outdated or noisy, RAV can't magically fix that.
- It will faithfully verify against bad data.
- Extraction granularity:
- Too many tiny claims → slower, noisier.
- Too few coarse claims → subtle errors slip through.
- Threshold tuning:
- Picking the "hallucination score" threshold is a product decision:
- High threshold → more trust, fewer corrections.
- Lower threshold → more corrections, more conservative answers.
- Picking the "hallucination score" threshold is a product decision:
When I Reach for RAG+RAV Now
I don’t apply this pipeline everywhere. I use RAG+RAV when the factual correctness really matters, and users need to trust the system. For lighter use-cases, plain RAG is usually good enough.
But when I care about factuality, I now default to:
RAG for prevention, RAV for verification, and a correction loop to tie it together.
It is the closest I've gotten so far to treating an LLM as a careful assistant that checks its own work before speaking with confidence.
Learned something new? Tap that like button and pass it on!
Opinions expressed by DZone contributors are their own.
Comments