RAG Done Right: When to Use SQL, Search, and Vector Retrieval and How To Combine Them
RAG failures stem from retrieval, not models. Replace one-size-fits-all vector search with a decision framework, hybrid flow, and guardrails for reliable systems.
Join the DZone community and get the full member experience.
Join For FreeIn this article, I will attempt to explain why retrieval-agumented generation (RAG) fails when retrieval is treated as a one-size-fits-all approach.
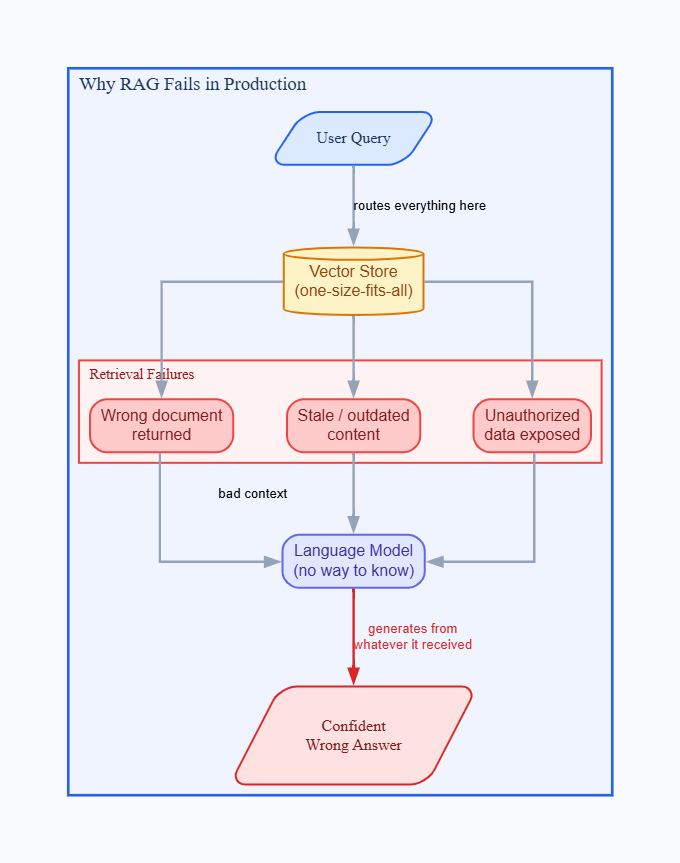
For example, the internal AI assistant looks great at demo time. Vector database ingesting overnight, GPT-4-class model, clean stakeholder presentation. The team ships.
Now it's time to ask real questions.
- A sales representative asks for a contract renewal date and gets a confident paragraph from the wrong client's document.
- A compliance officer asks about the current data retention policy and gets the 2021 version, no disclaimer. A developer can query the data that their role cannot access. The assistant answers anyway.
This isn't the model's fault. It generated exactly what it was built to generate: a confident/fluent answer from whatever the retrieval layer handed it. The retrieval layer got the wrong document, stale, and unauthorized data. The model had no way to know.
RAG quality isn't a model problem. It is a retrieval architecture problem. Most teams discover this after moving to production.
The root cause is almost always the same: applying a single retrieval method to everything. Vector search is the usual default, not because it is wrong, but because it was treated as the universal answer. The result is a system that is excellent at semantic similarity but genuinely poor at exact lookups, fresh data, and access control.
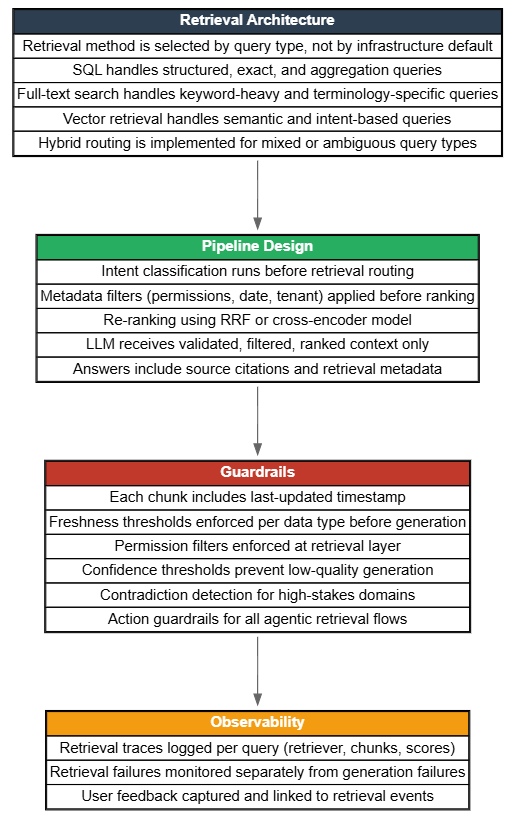
Production RAG needs a retrieval decision framework (RDF), not a retrieval default. The method must match the shape of the question. In enterprise systems, this routing must also account for live data sources and governed access, not just static indexes.
The Retrieval Decision Framework
Different questions have different shapes. A question asking for a specific number has a different retrieval need than a question asking for a concept. A question about current pricing is basically different from a question about industry sentiment. The framework below maps query shape to retrieval method. Apply it at the routing layer, before any retriever is called.
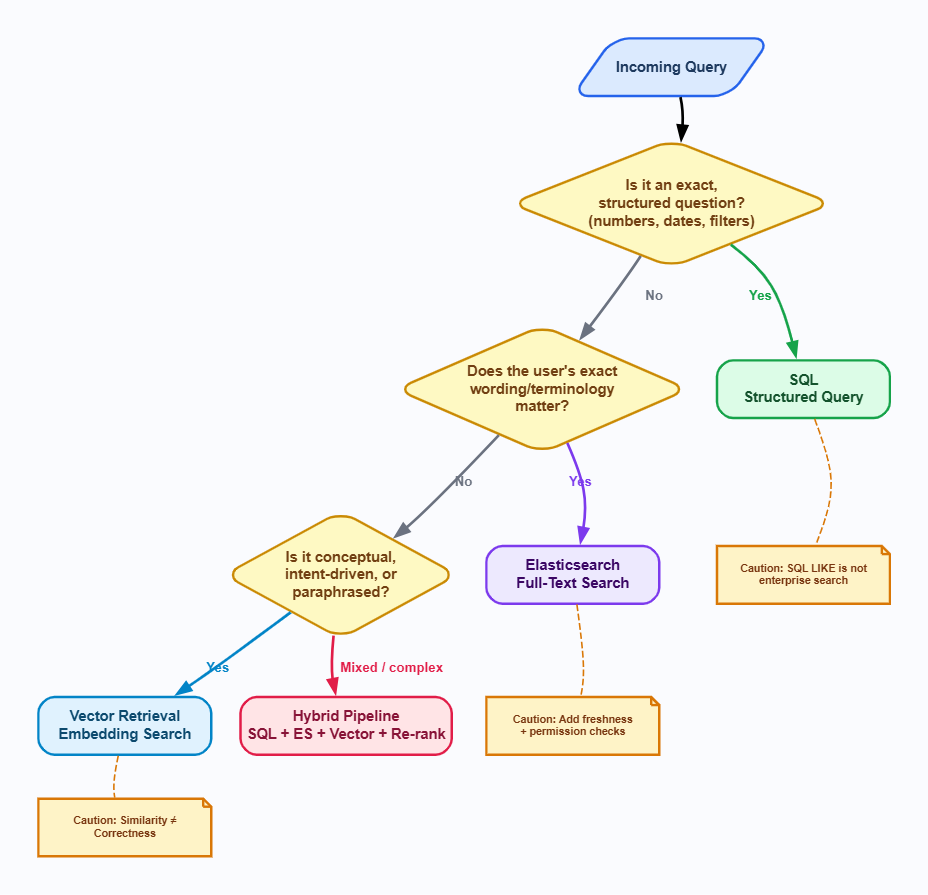
Figure 2: Retrieval decision framework: As a routing flowchart. Follow the query from top to bottom.
Use SQL When the Question Needs Exact, Current, Structured Data
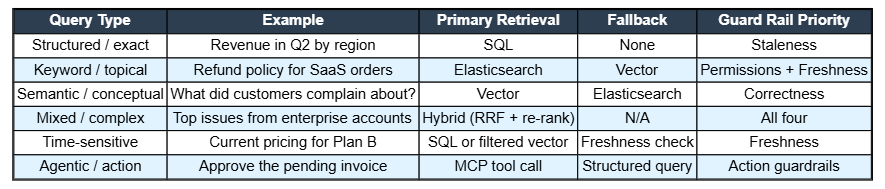
SQL is the correct retrieval path when the answer is deterministic and lives in structured, relational data. Aggregations, date ranges, filters, joins, and exact record lookups are all SQL territory.
- "What was total revenue in Quarter2, broken down by product line?"
- "Show me all open support tickets for accounts on an enterprise contract."
- "Which customers have not logged in for > 90 days?"
These questions have a single correct answer. It lives in a table. No amount of semantic reasoning improves on a well-written query. The answer is right or wrong, and the only path to the right is the structured source of truth. SQL also wins decisively on freshness as relational databases reflect the current state at query time. A vector index reflects the state at the last indexing run. For any question where recency matters, SQL is the safer default. There is no staleness threat because there is no index lag.
Caution: Do NOT use SQL LIKE searches as a default enterprise search strategy. LIKE performs full table scans, ignores language variation and word boundaries, and collapses under load on large datasets. If your team is considering using LIKE as an alternative to comprehensive text searches, it indicates the need to invest in a dedicated search framework, rather than stretching SQL beyond its intended limits.
Use Keyword/Full-Text Search When the User's Wording Matters
Elasticsearch and other full-text search engines are often overlooked but play an important role. They are useful when the exact words a user uses are important, when you need to find a lot of information in a collection of documents, or when you want to filter results based on extra information while also matching text.
- "What is our refund policy for international SaaS orders?"
- "Find all documentation mentioning deprecation of the v2 API."
- "Show me onboarding guides tagged for enterprise customers."
BM25 is the ranking method used by most keyword search engines. It shows documents that include the exact words the user typed. It also supports features like boosting certain fields, scoring based on how recent a document is, and using filters for metadata. These features are either missing or not well done in vector stores.
Elasticsearch is not just a backup option or an old technology waiting to be replaced by newer methods. Its tools for analyzing text, special tokenizers, and the ability to weigh different fields give teams better control over retrieving information than systems based on embeddings. Teams that switch entirely from keyword search to vector retrieval often revert to keyword search after noticing problems with accuracy in their results.
Caution: Before providing search results to a language model, ensure they are fresh, authorized for the user, and from a trustworthy source, as these checks should occur prior to generation.
Use Vector Retrieval When Intent Matters More Than Exact Words
Dense vector retrieval with text embeddings is ideal when user intent is prioritized over exact phrasing, as it effectively manages synonyms, paraphrasing, cross-lingual queries, and conceptual questions.
- "What have customers been most unhappy about this quarter?"
- "Summarize the main themes from last month's support escalations."
- "Are there any known issues with database connection timeouts?"
None of these questions has a specific keyword, as they can be phrased in various ways; vector retrieval effectively captures intent through embedding models that match semantically similar content. Selecting the right embedding model is crucial, especially for domain-specific contexts like legal or medical fields, as fine-tuned embeddings significantly improve retrieval performance compared to general-purpose models.
Caution: Vector similarity is not the same as correctness. Just because a chunk has a cosine similarity score of 0.87 doesn't mean it's accurate, up to date, or relevant to your question. High similarity indicates the text is conceptually related, but it doesn't guarantee the information is true, up to date, or verified. Always validate any retrieved context before sharing it with a language model.
How To Combine SQL, Search, and Vectors in a Hybrid RAG Flow
Most production queries do not cleanly fit into a single retrieval category. "What are the top issues affecting enterprise accounts over the last 30 days?" requires structured filtering (enterprise accounts, 30-day window), keyword retrieval (ticket descriptions, issue categories), and semantic grouping (clustering similar complaints). No single retriever handles all three well.
The solution is a hybrid pipeline with explicit routing logic, using a recommended 7-step flow.
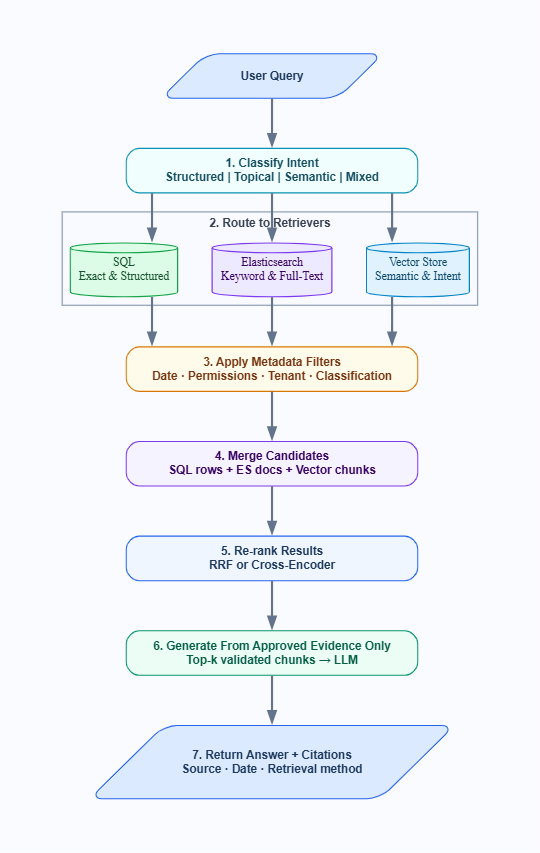
Figure 3: The hybrid RAG pipeline from query classification through to cited answer generation.
Step 1: Classify the User Intent
Before routing to any retriever, classify the query. A lightweight classifier, either a fine-tuned model or a structured prompt to a fast LLM, categorizes the question as structured, topical, semantic, or mixed. This classification drives every decision downstream. Skipping it means routing blindly.
Step 2: Route to the Right Retriever First
Send the query to its primary retriever based on classification. Structured queries go to SQL. Keyword and topical queries go to Elasticsearch. Conceptual queries go to the vector store. Mixed queries run multiple retrievers in parallel. Routing isn't a performance optimization, but it is a correctness decision.
Step 3: Apply Metadata Filters Before Ranking
Before scoring or merging results, apply hard filters for date range, document type, access permissions, tenant ID, and document classification. Filtering before ranking is more efficient and, more importantly, prevents unauthorized or irrelevant documents from entering the candidate pool in the first place. A document that should not be seen must never reach the ranker.
Step 4: Merge Candidates From Multiple Retrieval Paths
When multiple retrievers run in parallel, collect all candidates into a single unified pool. You now have SQL rows, keyword-matched documents, and vector-retrieved chunks alongside each other. The next step determines how to rank them together.
Step 5: Re-Rank Results
Once you have gathered results from different search paths, you need to re-rank them to see which ones actually answer the user’s question best. The most practical way to do this is using Reciprocal Rank Fusion (RRF).
It is a great default because it is simple and doesn't require complex math to compare results across systems, such as SQL and vector stores. It works on a straightforward principle: if two different search tools agree that a document is the #1 result, that document gets a much higher score than one only found by a single tool.
For high-stakes queries where precision is critical, you can use a cross-encoder re-ranker (a high-precision AI model used in search and RAG systems to reorder top candidate results by directly comparing a query and a document together ). This is even more accurate than RRF, though it does add a bit more processing time (latency).
Step 6: Generate Only From Approved Evidence
Pass only the top-ranked, filtered, validated chunks to the language model. Instruct the model explicitly to answer only from the provided context and to acknowledge when the context does not support a confident answer. It is a hard architectural constraint (NOT a prompt-engineering trick) on what the model is permitted to generate from.
Step 7: Return Citations, Sources, or Traceable Evidence
Every generated answer must be traceable/auditable to a specific retrieved source. Surface the document title, last updated date, source system, and retrieval method. Citation is the way by which users can verify the answer and catch retrieval failures before they become decisions.
Guardrails Against Stale, Incorrect, or Unauthorized Answers
Guardrails aren't an afterthought; they're built into the design from the beginning. A RAG pipeline lacking these guardrails is just a confident hallucination generator with some documents. The 4 guardrail categories listed below are essential for enterprise use.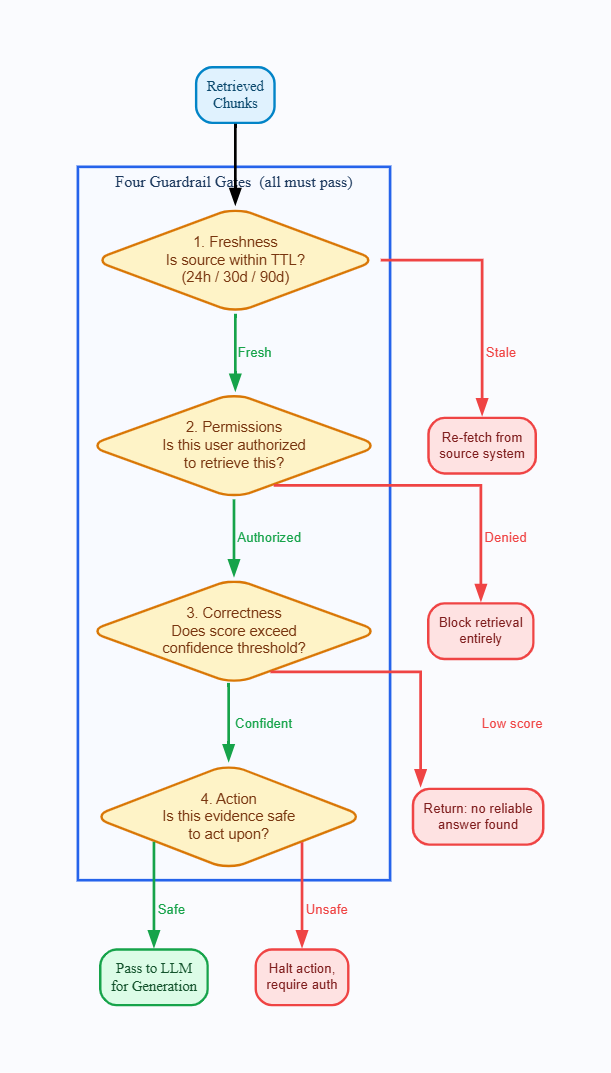
Figure 4: The four guardrail gates every retrieved chunk must pass before reaching the language model.
1. Freshness Guardrails
Every chunk in your retrieval index must carry a last-updated timestamp. Before passing retrieved content to the language model, verify that the source document falls within an acceptable freshness window for the query type. Pricing data might have a TTL of 24 hours. Legal and compliance policies might require freshness within 30 days. Internal knowledge base articles might tolerate 90 days.
If the retrieved document is stale, do not silently use it. Either return a warning, trigger a live re-fetch from the source system, or respond with an honest acknowledgment that current data is unavailable. Confident answers from outdated sources are one of the most dangerous failure modes in enterprise RAG, precisely because they are indistinguishable from correct answers.
2. Permission Guardrails
Every retrieval call must enforce the access permissions of the requesting user. Filter by tenant, role, team, document classification, and any other access control dimension your organization uses, before any document enters the candidate pool.
Permissions must be enforced at the retrieval layer, not the presentation layer. Retrieving a document and then deciding not to display it is already a failure. The document was read, processed, and potentially influenced generation before being suppressed. In enterprise environments with role-based access control, this means passing user context explicitly into every retrieval call and applying permission filters as a hard pre-ranking step.
3. Correctness Guardrails
If the top retrieved chunk scores below a defined confidence threshold, the pipeline must not generate an answer from it. Returning "I could not find a reliable answer to this question" is a better result than generating a fluent, authoritative answer from a marginally relevant chunk. One undermines confidence. The other undermines trust, which is harder to rebuild.
When retrieved chunks from different sources contradict each other, flag the contradiction explicitly rather than allowing the language model to silently pick a side. Contradiction detection is particularly critical in regulated industries where two versions of the same policy can have entirely different legal implications.
4. Action Guardrails
In agentic workflows, retrieval frequently precedes action. An agent reads a list of pending approvals and then processes them. An agent reads contract terms and then initiates a workflow. Action guardrails ensure the agent can't act on retrieved information that is stale, ambiguous, out of scope, or unauthorized.
Every action taken by an agentic system must be traceable to a specific retrieval event, piece of evidence, and user authorization. If that chain cannot be formed, the action must not proceed. This is where retrieval governance and operational risk management will join together.
Where MCP and Enterprise Integration Fit
In a document Q&A system, retrieval works like this: the user asks a question, the system finds relevant information, and the model generates an answer. This setup works well for knowledge bases and basic assistants. However, in agentic systems, retrieval goes a step further. The agent doesn’t just search for info; it uses tools to pull data from live systems, kick off business workflows, query external APIs, and act on the user's behalf. This complexity requires stricter guardrails.
The Model Context Protocol (MCP) is emerging as the go-to standard for these tool-integrated retrievals. It offers agents a reliable way to access structured tools across platforms such as databases, CRMs, and calendar APIs, enabling the language model to effectively reason about interactions. Every MCP tool call operates as a read action, adhering to the same four guardrails mentioned earlier.
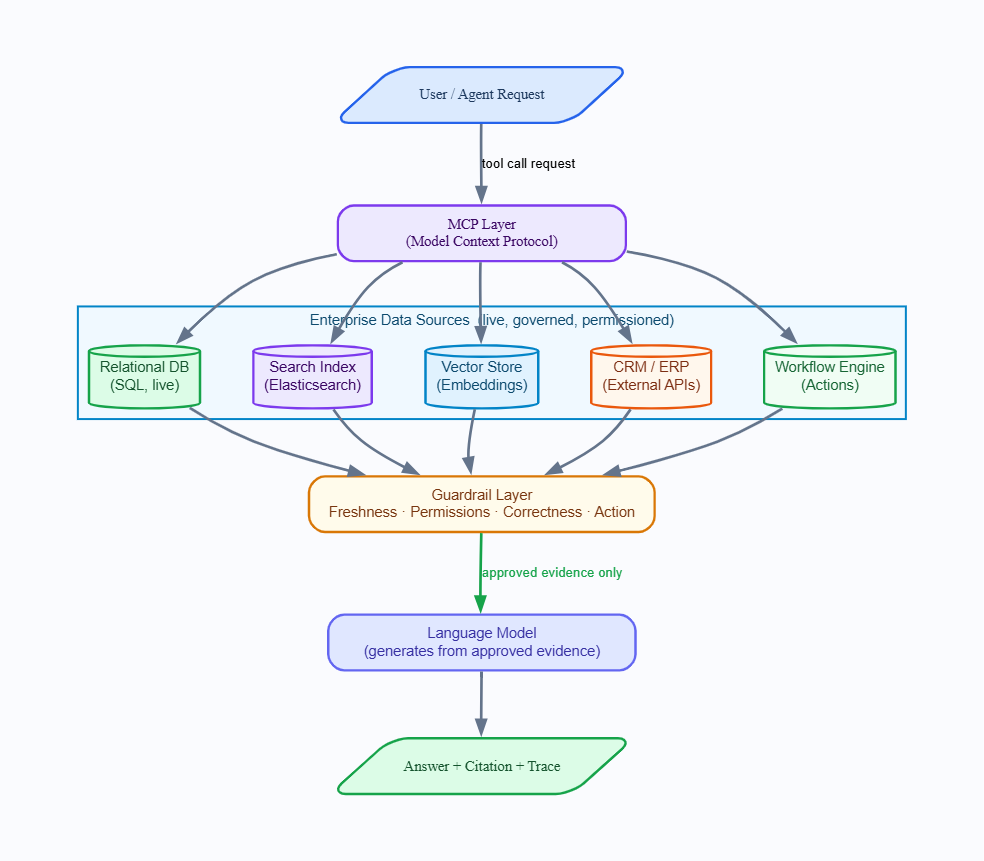 Figure 5: How MCP connects an agent to live enterprise data sources through a governed guardrail layer.
Figure 5: How MCP connects an agent to live enterprise data sources through a governed guardrail layer.
Enterprise platforms like OutSystems, which offer an AI workbench for creating governed AI apps from enterprise data, perfectly fit this space. The retrieval architecture choices discussed here aren't just theoretical; they decide if an enterprise AI feature is reliable in real-world use or just looks good in demos.
When retrieval pulls from live enterprise systems through controlled tool calls, it’s easier to keep the data fresh. There's no risk of stale indexes since data is fetched directly from the source when needed. This leads to a cleaner architecture with more predictable and auditable outcomes.
Implementation Checklist for Production RAG
Before marking any RAG feature as production-ready, every item in this checklist should be confirmed.
Conclusion: RAG Architecture Is Retrieval Governance
The biggest mistake in enterprise RAG is treating retrieval like a solved problem. It works in demos but fails with real data. You need an architecture that matches the tool to the question's "shape." Use SQL for numbers, search for exact terms, and vectors for conceptual meaning.
It’s really about governance. You must enforce permissions and check data freshness before anything reaches the model. Follow the 7-step flow: classify the query, route it, filter metadata, merge, and re-rank for precision. Always generate answers from approved evidence and provide citations for transparency.
Quick Reference: Retrieval Decision Framework
Opinions expressed by DZone contributors are their own.
Comments