Integrating Retrieval-Augmented Generation (RAG) With Agentic AI: Harnessing Elasticsearch Vector Databases for Enterprise AI Systems
A practical overview of using retrieval-augmented generation and agentic AI with Elasticsearch to build reliable, enterprise-ready LLM systems.
Join the DZone community and get the full member experience.
Join For FreeLarge language models (LLMs) have changed how we think about automation and managing knowledge. They show strong skills in synthesis tasks. However, using them in crucial business areas like FinTech and healthcare reveals their underlying limitations.
It is clear that while LLMs can generate language well, they lack the structural strength needed to serve as reliable knowledge systems or to act as independent, responsible decision-makers in real-world situations.
Enterprises don’t just want chatbots; they want intelligent agents that can:
- Interpret domain-specific data
- Make decisions aligned with business rules
- Maintain context across multi-step workflows
- Produce accurate, traceable, and compliant outputs
Plain LLMs cannot meet these expectations. They hallucinate. They don’t “know” your enterprise. And they lack long-term memory. Agentic AI — LLM-powered agents that plan, reason, and act — depend heavily on trustworthy knowledge and persistent state.
This is exactly where retrieval-augmented generation (RAG) and Elasticsearch-based vector databases intersect. RAG grounds model responses in real enterprise data. Elasticsearch provides scalable, low-latency vector search and hybrid retrieval. Agentic AI orchestrates everything into autonomous behavior.
This article presents a clear, practical blueprint for integrating RAG with agentic AI using Elasticsearch vector databases, complete with architectural patterns, a Python implementation, and actionable design guidance for real-world enterprise environments.
The Enterprise AI Gap: Problem Statement
Hallucination Is a First-Class Risk
LLMs generate text by predicting the next token rather than verifying facts. This leads to hallucinations, outputs that appear plausible but are objectively incorrect.
In a consumer Q&A setting, such errors may be merely inconvenient. In an enterprise environment, however, they can be harmful:
- Incorrect regulatory or compliance guidance
- Misinterpretation of policies or procedures
- Inaccurate financial or healthcare recommendations
- Misleading analysis for internal stakeholders
It is not feasible to build reliable, production-grade AI systems on a model that confidently produces information without underlying verification.
No Native Access to Enterprise Knowledge
Out of the box, an LLM:
- Doesn’t know your products or services
- Can’t see your internal documentation, playbooks, or policies
- Can’t query your databases, APIs, or knowledge bases
- Can’t automatically incorporate daily changes in the business
Fine-tuning helps only partially and is expensive, slow, and brittle. Enterprises need a way for LLMs to retrieve the latest truth from their own systems.
No Long-Term Memory for Multi-Step Tasks
Agentic workflows, like onboarding, troubleshooting, or case resolution, require:
- Remembering prior steps and decisions
- Reusing context across multiple interactions
- Building a “picture” of the user or case over time
LLMs have a context window, not true memory. Once the token limit is reached or the session ends, the model “forgets” everything.
Lack of Explainability and Traceability
In regulated and high-stakes environments, leaders ask:
- Where did this answer come from?
- Which policy or document supports this recommendation?
Plain LLMs cannot show their work. Without retrieval, there are no citations, no links to documents, no audit-friendly trails.
Scaling Retrieval Across Millions of Documents
Even if you attach a search layer, traditional keyword search (BM25, full-text) is not enough. Enterprises need:
- Semantic search to understand meaning, not just keywords
- Low-latency vector search at scale
- Hybrid retrieval that combines dense and sparse signals
- Robust indexing pipelines that can ingest varied content
This is where vector databases and Elasticsearch’s modern vector capabilities become essential.
What is Retrieval-Augmented Generation (RAG) and Why Does It Matter?
RAG addresses the main weaknesses of LLMs by injecting fresh, relevant, and authoritative context into every response. RAG operates as an intermediary layer between organizational data and a language model.
The process typically involves:
- Encode documents as vector embeddings.
- At query time, embed the user question.
- Retrieve the most relevant chunks from a vector store (e.g., Elasticsearch).
- Pass the retrieved context + question into the LLM.
- The LLM becomes a reasoning engine over your data, instead of a hallucinating storyteller.
RAG enables:
- Hallucination reduction through fact-grounding
- Immediate updates, no model retraining needed
- Explainable answers with citations and traceability
- Domain-specific accuracy using internal knowledge
- Enterprise safety and compliance controls
- Long-term memory when prior decisions are stored as embeddings
RAG is the backbone of trustworthy, production-ready enterprise AI.
Why Elasticsearch as a Vector Database for Agentic AI?
Elasticsearch has evolved from a search engine into a powerful vector search and hybrid retrieval platform. For enterprise RAG and agents, it offers many advantages.
Vector Search at Scale
Elasticsearch supports:
- Dense vector fields
- Approximate Nearest Neighbor (ANN) algorithms
- Similarity metrics like cosine and dot product
This enables fast, scalable semantic retrieval across millions of documents.
Hybrid Retrieval (Dense + Sparse)
Best-in-class RAG often uses hybrid search:
- BM25 / keyword signals → precision for explicit terms (IDs, codes, field names)
- Vector similarity → semantic understanding of meaning
This enables quick, scalable semantic retrieval across millions of documents.
Enterprise Security and Governance
For real-world deployments, Elasticsearch offers:
- Role-based access control
- Encryption and TLS
- Audit logging
- Multi-tenant clusters
This is critical for FinTech, healthcare, and other regulated domains.
Operational Maturity
Elasticsearch is already in use by many enterprises for log analytics, observability, or search. Extending that investment to RAG and Agentic AI is a natural and cost-effective path.
Architecture Design: RAG + Agentic AI + Elasticsearch
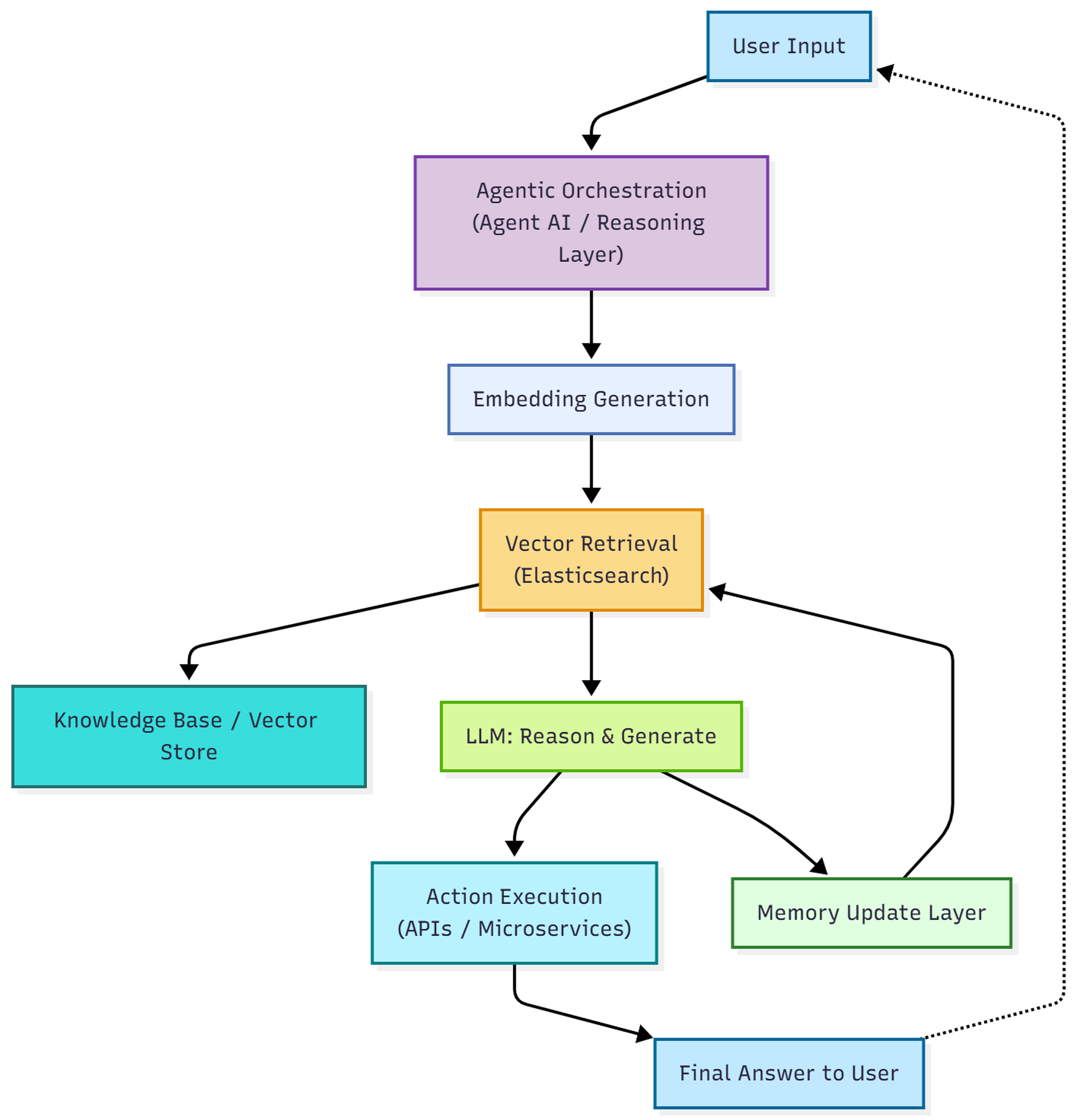
High-Level Architecture
Components
- User Input Layer: Receives commands or queries.
- Embedding Generation: Converts input into semantic vectors using LLM embeddings.
- Vector Retrieval Layer (Elasticsearch): Searches for relevant embeddings from knowledge or memory.
- Agent Reasoning Layer: LLM uses retrieved context to generate responses or actions.
- Action Execution Layer: Executes tasks via APIs, microservices, or internal logic.
- Memory Update Layer: Stores embeddings of new interactions for future retrieval.
Key Roles of Integrated Technologies
| Technology Role | Core Function in Architecture |
| Elasticsearch Vector Store | Serves as the knowledge base and long-term agent memory, storing embeddings and enabling high-speed vector similarity search. |
| RAG Layer | Orchestrates the retrieval process: fetching vectors, reconstructing text chunks, and assembling the final context sent to the LLM. |
| LLM | The core computational engine that interprets the question and synthesizes the answer only from the provided context. |
| Agentic Layer | The control plane that plans the multi-step workflow, determines when to invoke tools (including RAG), and manages memory updates. |
Design Best Practices
- Chunk your documents wisely (by sections, headings, or semantic units).
- Index rich metadata (source, department, tags, data sensitivity).
- Use hybrid search to combine keyword and vector retrieval.
- Add guardrails: if context is weak, the agent should abstain or escalate.
- Evaluate regularly with synthetic and real test cases (hallucinations, relevance, latency).
- Start narrow and expand: begin with one domain (e.g., onboarding) and scale out.
Implementation Walkthrough in Python
Below is a simplified but realistic implementation to help you go from concept to code.
Install Dependencies
pip install elasticsearch sentence-transformers openai numpy
You can swap OpenAI with any LLM provider; the RAG pattern stays the same.
Connect to Elasticsearch
from elasticsearch import Elasticsearch
es = Elasticsearch(
"http://localhost:9200",
basic_auth=("elastic", "your_password")
)
Create a Vector-Enabled Index
index_name = "rag_docs"
index_body = {
"mappings": {
"properties": {
"content": {"type": "text"},
"embedding": {
"type": "dense_vector",
"dims": 768,
"similarity": "cosine"
},
"source": {"type": "keyword"}
}
}
}
if not es.indices.exists(index=index_name):
es.indices.create(index=index_name, body=index_body)
Generate Embeddings and Index Documents
from sentence_transformers import SentenceTransformer
import uuid
model = SentenceTransformer("all-MiniLM-L6-v2")
documents = [
{
"content": "RAG reduces hallucinations by grounding LLM responses in retrieved enterprise knowledge.",
"source": "architecture-notes"
},
{
"content": "Agentic AI enables multi-step reasoning and tool usage, turning LLMs into autonomous agents.",
"source": "design-doc"
},
{
"content": "Elasticsearch provides scalable vector search and hybrid retrieval for enterprise AI workloads.",
"source": "platform-doc"
}
]
for doc in documents:
embedding = model.encode(doc["content"]).tolist()
es.index(
index=index_name,
id=str(uuid.uuid4()),
document={
"content": doc["content"],
"embedding": embedding,
"source": doc["source"]
}
)
Build a Retrieval Function
def retrieve_context(question: str, k: int = 3):
query_vec = model.encode(question).tolist()
search_body = {
"size": k,
"query": {
"knn": {
"embedding": {
"vector": query_vec,
"k": k
}
}
}
}
results = es.search(index=index_name, body=search_body)
chunks = []
for hit in results["hits"]["hits"]:
source = hit["_source"]
chunks.append(source["content"])
return "\n".join(chunks)
Construct a RAG Prompt
def build_rag_prompt(question: str) -> str:
context = retrieve_context(question)
return f"""
You are an enterprise AI assistant. Use ONLY the context below to answer the question accurately.
If the context is insufficient, say you do not have enough information.
Context:
{context}
Question:
{question}
"""
Call the LLM
from openai import OpenAI
client = OpenAI(api_key="YOUR_OPENAI_API_KEY")
def ask_rag(question: str) -> str:
prompt = build_rag_prompt(question)
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": "You are a precise, compliant enterprise assistant."},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message["content"]
print(ask_rag("How does RAG help reduce hallucinations in enterprise AI?"))
From RAG to Agentic AI
To evolve from “assistant” to agent, you add:
Planning
The agent decides what to do next:
- Retrieve more context
- Call an external API
- Write new data back into Elasticsearch
- Ask the user for clarification
Tool Use
You expose tools to the agent:
search_docs(RAG retrieval)call_api(microservices, SaaS, internal APIs)write_memory(store embeddings, notes, decisions)
Memory
You can treat Elasticsearch itself as a memory layer:
- Store decisions and summaries as embeddings
- Store user preferences or case state as documents
- Retrieve them later as part of context
Simple Agent Loop (Conceptual)
def agent(query: str):
# Step 1: Retrieve context via RAG
context = retrieve_context(query)
# Step 2: Ask the LLM to propose a plan
plan_prompt = f"""
You are an enterprise AI agent.
Given the user query and the context below, decide the next step.
Context:
{context}
User query:
{query}
Decide whether to:
- answer_directly
- refine_and_search
- ask_clarifying_question
Explain your reasoning briefly.
"""
plan = ask_llm(plan_prompt) # wrapper around LLM call
# Step 3: Act based on plan (simplified)
if "refine_and_search" in plan:
refined_query = extract_refined_query(plan) # parse from LLM output
return agent(refined_query)
elif "ask_clarifying_question" in plan:
question_to_user = extract_question(plan)
return f"CLARIFY: {question_to_user}"
else:
# answer directly using current context
return ask_rag(query)
Real-World Use Cases and Design Tips
Use Cases
FinTech & Wealth Management
- Advisor onboarding assistants
- Product and services recommendations
- Compliance-checking agents
- Policy and product knowledge assistants
Healthcare
- Clinical guidelines retrieval
- Summarizing patient history from notes (with proper governance)
Cybersecurity
- Incident triage agents retrieving logs and playbooks
- Guided response workflows based on runbooks
Internal Enterprise AI
- Developer knowledge assistants
- Architecture and design documentation copilots
- Support agents for internal tools and platforms
Real-World FinTech Example
Scenario: An AI agent advising clients on retirement portfolios.
- User input: “Recommend a moderate-risk strategy for 2025.”
- Embedding generation: Convert the query into a vector.
- Vector search: Retrieve client history, recent market analysis, and regulatory guidelines.
- RAG-based reasoning: LLM combines context to provide an informed recommendation.
- Action: Suggest portfolio allocation via dashboard or notification.
- Memory update: Store embeddings for future personalized recommendations.
Benefits
- Dynamic, accurate, and personalized advice
- Reduced hallucinations
- Scalable knowledge retrieval
Conclusion
Enterprises today demand AI systems that go beyond generating text; they must interpret complex domain data, make informed decisions, retain long-term context, and deliver accurate outputs traceable to authoritative sources. Traditional LLMs alone cannot meet these expectations due to hallucinations, a lack of enterprise grounding, and limited reasoning over extended tasks.
Integration of RAG and Agentic AI, powered by Elasticsearch vector databases, enables organizations to gain a scalable and reliable foundation for autonomous enterprise intelligence. This unified architecture provides factual, domain-grounded answers, transparent reasoning, high-performance semantic retrieval, and persistent memory that supports complex multi-step agent workflows.
As enterprises move toward autonomous and self-improving systems, the combined RAG + Agentic AI + Elasticsearch architecture offers a clear blueprint for modern AI design. It enables agents to reliably retrieve, reason, remember, and act — elevating enterprise AI from basic assistance to true autonomy.
Opinions expressed by DZone contributors are their own.
Comments