Record Audio Using webrtc in Chrome and Speech Recognition With Websockets
Join the DZone community and get the full member experience.
Join For Free
so let's see what we can do with this. most of the examples i've seen so far focus on processing the input directly, within the browser, using the web audio api . you get synthesizers, audio visualizations, spectrometers etc. what was missing, however, was a means of recording the audio data and storing it for further processing at the server side. in this article i'll show you just that. i'm going to show you how you can create the following (you might need to enlarge it to read the response from the server):
in this screencast you can see the following:
- a simple html page that access your microphone
- the speech is recorded and using websockets is sent to a backend
- the backend combines the audio data
- and sends it to google's speech to text api
- the result from this api call is returned to the browser
and all this is done without any plugins in the browser! so what's involved to accomplish all this.
allowing access to your microphone
the first thing you need to do is make sure you've got an up to date version of chrome. i use the dev build, and am currently on this version:

since this is still an experimental feature we need to enable this using the chrome flags.
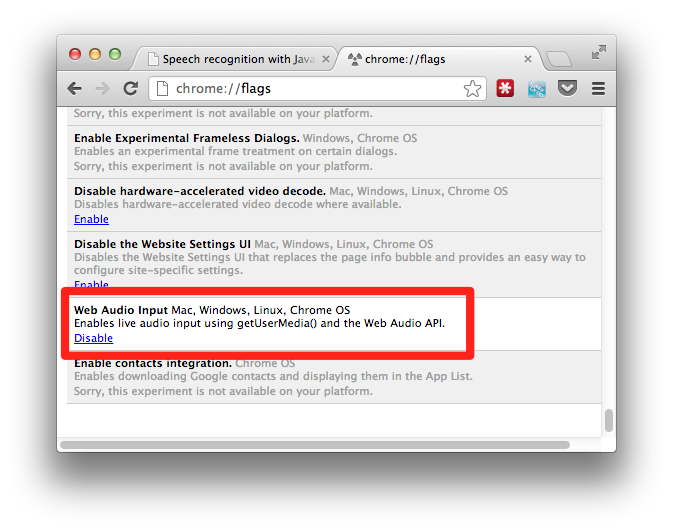
make sure the "web audio input" flag is enabled. with this configuration out of the way we can start to access our microphone.
access the audio stream from the microphone
this is actually very easy:
function callback(stream) {
var context = new webkitaudiocontext();
var mediastreamsource = context.createmediastreamsource(stream);
...
}
$(document).ready(function() {
navigator.webkitgetusermedia({audio:true}, callback);
...
}
as you can see i use the webkit prefix functions directly, you could, of course, also use a shim so it is browser independent. what happens in the code above is rather straightforward. we ask, using getusermedia, for access to the microphone. if this is successful our callback gets called with the audio stream as its parameter. in this callback we use the web audio specification to create a mediastreamsource from our microphone. with this mediastreamsource we can do all the nice web audio tricks you can see here .
but we don't want that, we want to record the stream and send it to a backend server for further processing. in future versions this will probably be possible directly from the webrtc api, at this time, however, this isn't possible yet. luckily, though, we can use a feature from the web audio api to get access to the raw data. with the javascriptaudionode we can create a custom node, which we can use to access the raw data (which is pcm encoded). before i started my own work on this i searched around a bit and came across the recoder.js project from here: https://github.com/mattdiamond/recorderjs . matt created a recorder that can record the output from web audio nodes, and that's exactly what i needed.
all i needed to do now was connect the stream we just created to the recorder library:
function callback(stream) {
var context = new webkitaudiocontext();
var mediastreamsource = context.createmediastreamsource(stream);
rec = new recorder(mediastreamsource);
}
with this code, we create a recorder from our stream. this recorder provides the following functions:
- record: start recording from the input
- stop: stop recording
- clear: clear the current recording
- exportwav: export the data as a wav file
connect the recorder to the buttons
i've created a simple webpage with an output for the text and two buttons to control the recording:

the 'record' button starts the recording, and once you hit the 'export' button the recording stops, and is sent to the backend for processing.
record button:
$('#record').click(function() {
rec.record();
ws.send("start");
$("#message").text("click export to stop recording and analyze the input");
// export a wav every second, so we can send it using websockets
intervalkey = setinterval(function() {
rec.exportwav(function(blob) {
rec.clear();
ws.send(blob);
});
}, 1000);
});
this function (using jquery to connect it to the button) when clicked starts the recording. it also uses a websocket (ws), see further down on how to setup the websocket, to indicate to the backend server to expect a new recording (more on this later). finally when the button is clicked an interval is created that passes the data to the backend, encoded as wav file, every second. we do this to avoid sending too large chunks of data to the backend and improve performance.
export button:
$('#export').click(function() {
// first send the stop command
rec.stop();
ws.send("stop");
clearinterval(intervalkey);
ws.send("analyze");
$("#message").text("");
});
the export button, bad naming i think when i'm writing this, stops the recording, the interval and informs the backend server that it can send the received data to the google api for further processing.
connecting the frontend to the backend
to connect the webapplication to the backend server we use websockets. in the previous code fragments you've already seen how they are used. we create them with the following:
var ws = new websocket("ws://127.0.0.1:9999");
ws.onopen = function () {
console.log("openened connection to websocket");
};
ws.onmessage = function(e) {
var jsonresponse = jquery.parsejson(e.data );
console.log(jsonresponse);
if (jsonresponse.hypotheses.length > 0) {
var bestmatch = jsonresponse.hypotheses[0].utterance;
$("#outputtext").text(bestmatch);
}
}
we create a connection, and when we receive a message from the backend we just assume it contains the response to our speech analysis. and that's it for the complete front end of the application. we use getusermedia to access the microphone, use the web audio api to get access to the raw data and communicate with websockets with the backend server.
the backend server
our backend server needs to do a couple of things. it first needs to combine the incoming chunks to a single audio file, next it needs to convert this to a format google apis expect, which is flac. finally we make a call to the google api and return the response.
i've used jetty as the websocket server for this example. if you want to know the details about setting this up, look at the facedetection example. in this article i'll only show the code to process the incoming messages.
first step, combine the incoming data
the data we receive is encoded as wav (thanks to the recorder.js library we don't have to do this ourselves). in our backend we thus receive sound fragments with a length of one second. we can't just concatenate these together, since wav files have a header that tells how long the fragment is (amongst other things), so we have to combine them, and rewrite the header. lets first look at the code (ugly code, but works good enough for now :)
public void onmessage(byte[] data, int offset, int length) {
if (currentcommand.equals("start")) {
try {
// the temporary file that contains our captured audio stream
file f = new file("out.wav");
// if the file already exists we append it.
if (f.exists()) {
log.info("adding received block to existing file.");
// two clips are used to concat the data
audioinputstream clip1 = audiosystem.getaudioinputstream(f);
audioinputstream clip2 = audiosystem.getaudioinputstream(new bytearrayinputstream(data));
// use a sequenceinput to cat them together
audioinputstream appendedfiles =
new audioinputstream(
new sequenceinputstream(clip1, clip2),
clip1.getformat(),
clip1.getframelength() + clip2.getframelength());
// write out the output to a temporary file
audiosystem.write(appendedfiles,
audiofileformat.type.wave,
new file("out2.wav"));
// rename the files and delete the old one
file f1 = new file("out.wav");
file f2 = new file("out2.wav");
f1.delete();
f2.renameto(new file("out.wav"));
} else {
log.info("starting new recording.");
fileoutputstream fout = new fileoutputstream("out.wav",true);
fout.write(data);
fout.close();
}
} catch (exception e) { ...}
}
}
this method gets called for each chunk of audio we receive from the browser. what we do here is the following:
- first, we check whether we have a temp audio file, if not we create it
- if the file exists we use java's audiosystem to create an audio sequence
- this sequence is then written to another file
- the original is deleted and the new one is renamed.
- we repeat this for each chunk
so at this point we have a wav file that keeps on growing for each added chunk. now before we convert this, lets look at the code we use to control the backend.
public void onmessage(string data) {
if (data.startswith("start")) {
// before we start we cleanup anything left over
cleanup();
currentcommand = "start";
} else if (data.startswith("stop")) {
currentcommand = "stop";
} else if (data.startswith("clear")) {
// just remove the current recording
cleanup();
} else if (data.startswith("analyze")) {
// convert to flac
...
// send the request to the google speech to text service
...
}
}
the previous method responded to binary websockets messages. the one shown above responds to string messages. we use this to control, from the browser, what the backend should do. let's look at the analyze command, since that is the interesting one. when this command is issued from the frontend the backend needs to convert the wav file to flac and send it to the google service.
convert to flac
for the conversion to flac we need an external library since java standard has no support for this. i used the javaflacencoder from here for this.
// get an encoder
flac_fileencoder flacencoder = new flac_fileencoder();
// point to the input file
file inputfile = new file("out.wav");
file outputfile = new file("out2.flac");
// encode the file
log.info("start encoding wav file to flac.");
flacencoder.encode(inputfile, outputfile);
log.info("finished encoding wav file to flac.");
easy as that. now we got a flac file that we can send to google for analysis.
send to google for analysis
a couple of weeks ago i ran across an article that explained how someone analyzed chrome and found out about an undocumented google api you can use for speech to text. if you post a flac file to this url: https://www.google.com/speech-api/v1/recognize?xjerr=1&client=chromium&l... you receive a response like this:
{
"status": 0,
"id": "ae466ffa24a1213f5611f32a17d5a42b-1",
"hypotheses": [
{
"utterance": "the quick brown fox",
"confidence": 0.857393
}]
}
to do this from java code, using httpclient, you do the following:
// send the request to the google speech to text service
log.info("sending file to google for speech2text");
httpclient client = new defaulthttpclient();
httppost p = new httppost(url);
p.addheader("content-type", "audio/x-flac; rate=44100");
p.setentity(new fileentity(outputfile, "audio/x-flac; rate=44100"));
httpresponse response = client.execute(p);
f (response.getstatusline().getstatuscode() == 200) {
log.info("received valid response, sending back to browser.");
string result = new string(ioutils.tobytearray(response.getentity().getcontent()));
this.connection.sendmessage(result);
}
and that are all the steps that are needed.

Published at DZone with permission of Jos Dirksen. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments