Redis Enterprise Kubernetes Release on Pivotal Container Service?
Over the last few months, our team has been busy working on deploying Redis Enterprise on Kubernetes. Through this blog post, I'd like to present the principles we used for deploying the Kubernetes release of Redis Enterprise on a Pivotal Container Service cluster.
Join the DZone community and get the full member experience.
Join For FreeOver the last few months our team has been busy working on deploying Redis Enterprise on Kubernetes. Our journey started with writing a simple controller for the Kubernetes release of Redis Enterprise. A few months later, we introduced Helm Chart support, and over the last couple of months, we have been writing an operator for our Kubernetes release.
Through this blog post, I would like to present the principles we used for deploying the Kubernetes release of Redis Enterprise on a Pivotal Container Service® cluster.
Why PKS?
It is imperative to manage containerized microservices in a cloud-native way, and Kubernetes has become the de facto unit of deployment for microservices architectures. PKS, a certified Kubernetes distribution, can be used in combination with the Pivotal Application System® (PAS) to manage your entire application lifecycle. Both of these platforms are governed by Cloud Foundry® and BOSH, a cloud orchestration tool. Together they provide an efficient approach for managing stateful services (e.g. your databases), as well as stateless services (e.g. your applications).
The three main components of PKS are:
- Pivotal Ops Manager - used to deploy BOSH Director and a PKS tile;
- PKS Client VM - for subcomponents like UAA CLI, PKS CLI and Kubectl CLI, which is usually deployed on a separate VM
- "Stemcell" - a customized operating system image for BOSH-managed virtual machines.
For the purpose of this blog post, let's assume that these components are successfully installed on an underlying infrastructure like vSphere.
Why Redis Enterprise?
Redis Enterprise combines the advantages of world-class database technology with the innovation of a vibrant open source Redis community to gain:
- Robust high availability with single-digit failover time
- True linear scalability, delivering an additional 1M+ ops/sec for every node you add to the cluster
- Distributed Active-Active based on Conflict-free Replicated Data Types (CRDT) technology
- Multi-model through Redis modules, which enriches Redis capabilities with RediSearch, ReJSON, Redis Graph, Redis-ML and others
- DRAM extension with Flash/SSDs for infrastructure cost savings.
Why Redis Enterprise on PKS?
We use four important principles for Redis Enterprise on PKS in order to maximize a robust deployment:
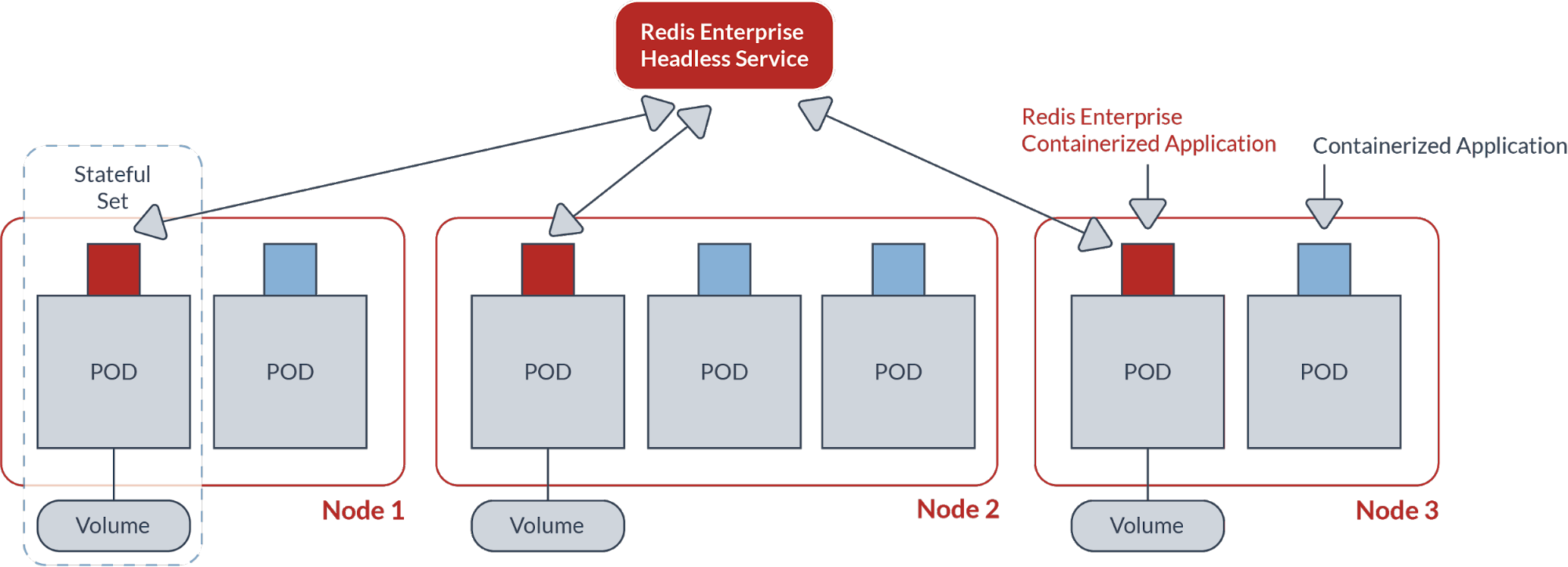
- Operator-based deploymentwith Statefulset & Anti-Affinity: Operators allows us to maintain a unified deployment across all Kubernetes environments. Kubernetes statefulset and anti-affinity enable Redis Enterprise node to reside on a POD that is hosted on a different VM or physical server. This setup is illustrated below:
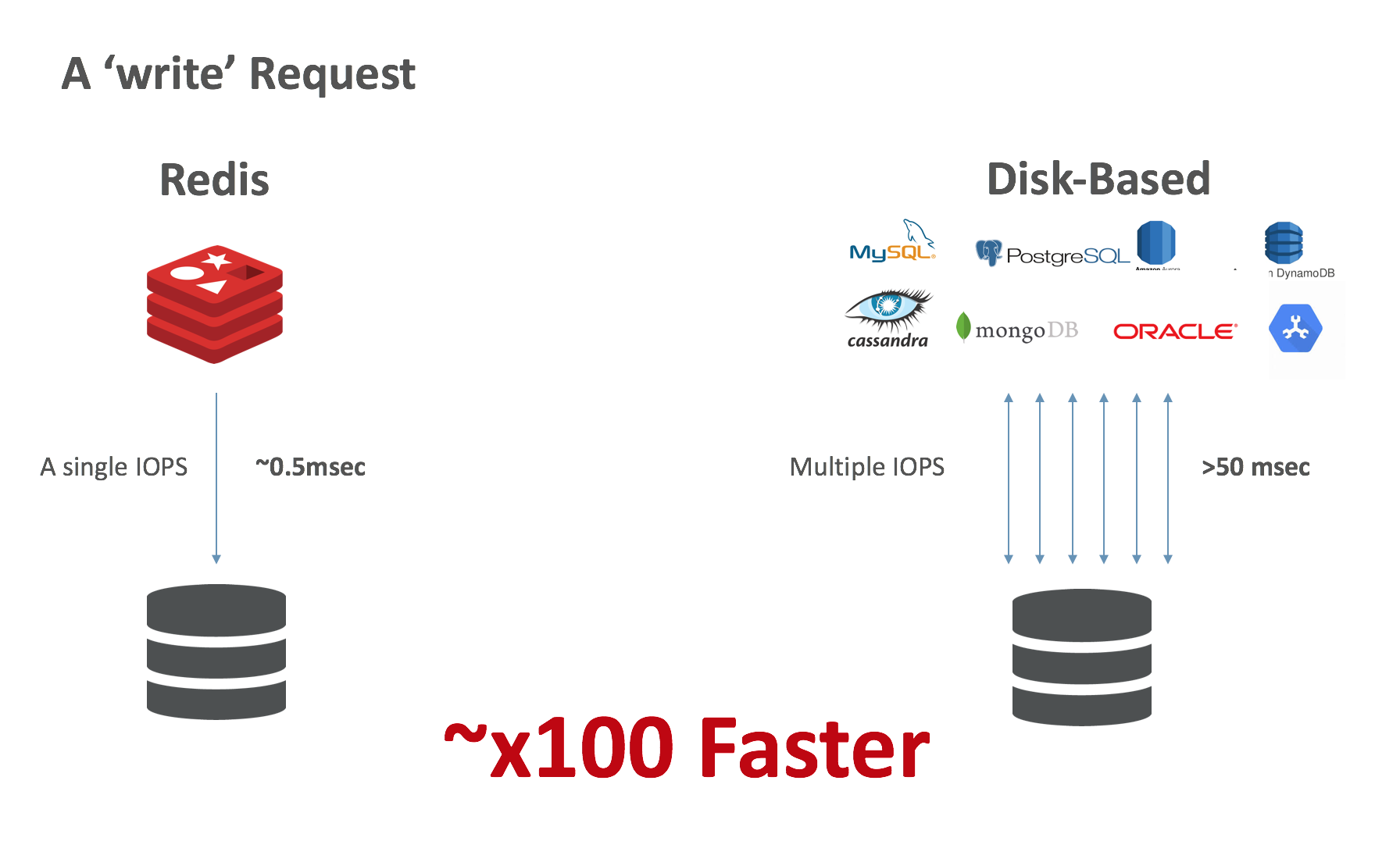
- Network-attached Persistent Storage forData Durability: To avoid losing local data on every POD failure event, PKS requires that storage volumes are network-attached to compute instances. In addition, since Redis is extremely efficient in the way it uses persistent storage (even when a user chooses to configure Redis to write every change to the disk), we see significant performance improvements with typical PKS environments. Compared to a disk-based database that requires multiple interactions (in most cases) with a storage device for every read or write operation, Redis uses single IOPS (in most cases) for a write operation and zero IOPS for a read operation.

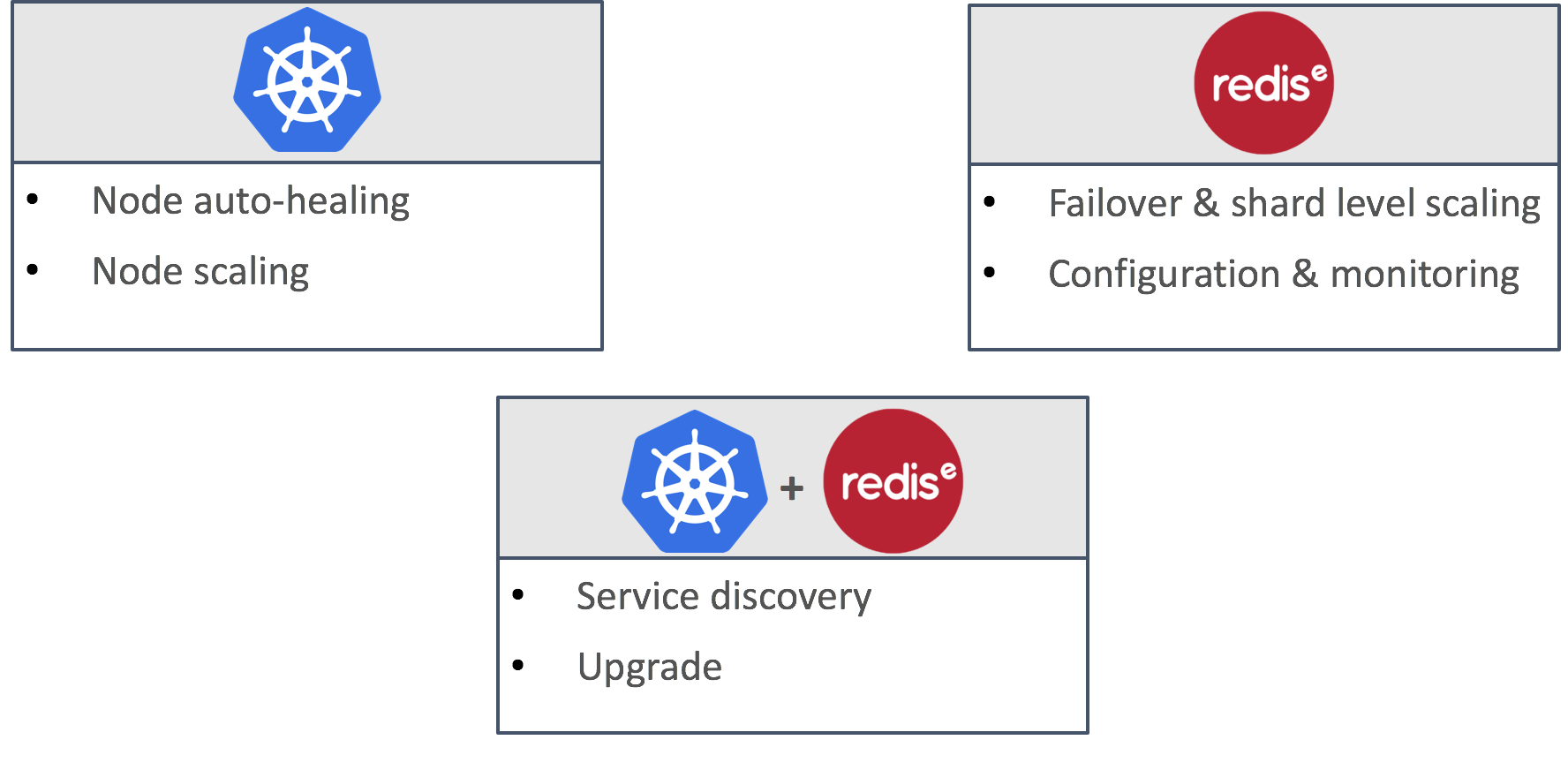
- Layered Orchestrator Architecture: We use this approach to deal with all the nuances associated with operating Redis on a Kubernetes cluster. Kubernetes is a great orchestration tool, but was not designed for specific Redis tasks and can sometimes react incorrectly to internal Redis problems. In addition, Kubernetes orchestration runs outside the Redis cluster deployment, and may fail to trigger a failover event in network split scenarios. Our layered architecture approach overcomes these issues by splitting responsibilities between the things Kubernetes does well, the things Redis Enterprise cluster is good at, and the things both can orchestrate together. This layered architecture is shown below:
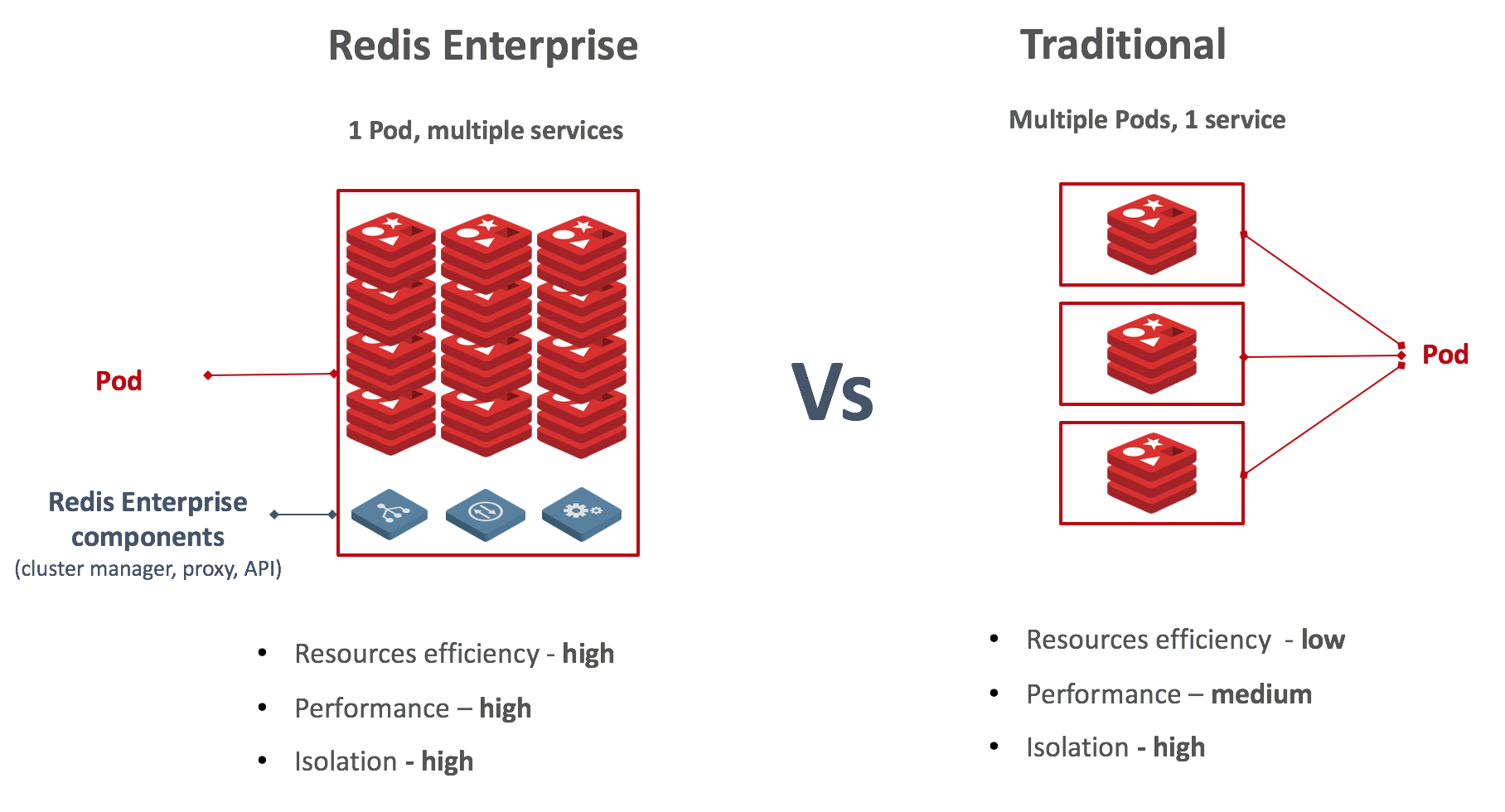
- Multiple Instance Deployment: We found that the traditional way to deploy a Redis over PKS (where each POD includes just one Redis instance while preserving a dedicated CPU) is extremely inefficient! Redis is extremely fast and in many cases can use just a fraction of the CPU to deliver the requested throughput. Furthermore, when running a Redis cluster with multiple Redis instances across multiple PODs, the PKS network (with its multiple vSwitches) can become your bottleneck. Therefore, we took a different approach for Redis Enterprise over PKS, in which each POD includes multiple Redis instances (multiple services). This allows each POD to better utilize hardware resources (CPU, memory and network), while keeping the same level of isolation. This approach is shown below:
Getting Started with Redis Enterprise on PKS
The docker image of the Redis Enterprise for PKS deployment is located here. You can read more about the architecture for Redis Enterprise Kubernetes release here.
To get started:
- Verify the PKS cluster is working by checking for the following settings.
- Verify BOSH-managed PKS nodes have been provisioned. For example, this image shows a four-node PKS cluster:

- Deploy your Redis Enterprise Cluster on PKS:Create a Custom Resource Definition (CRD) for Redis Enterprise on PKS:
kubectl apply -f redis-enterprise-crd.yml
Deploy the Redis Enterprise Operator on PKS:
kubectl apply -f redis-enterprise-operator.yml
Use the Operator and CRD to deploy a Redis Enterprise cluster on PKS:
kubectl apply -f redis-enterprise-cluster.yml - Verify that your Redis Enterprise Cluster is in a healthy state using Redis Enterprise Web Interface which is exposed on port 8443. This shows a three-node Redis Enterprise cluster running on top of a PKS cluster:
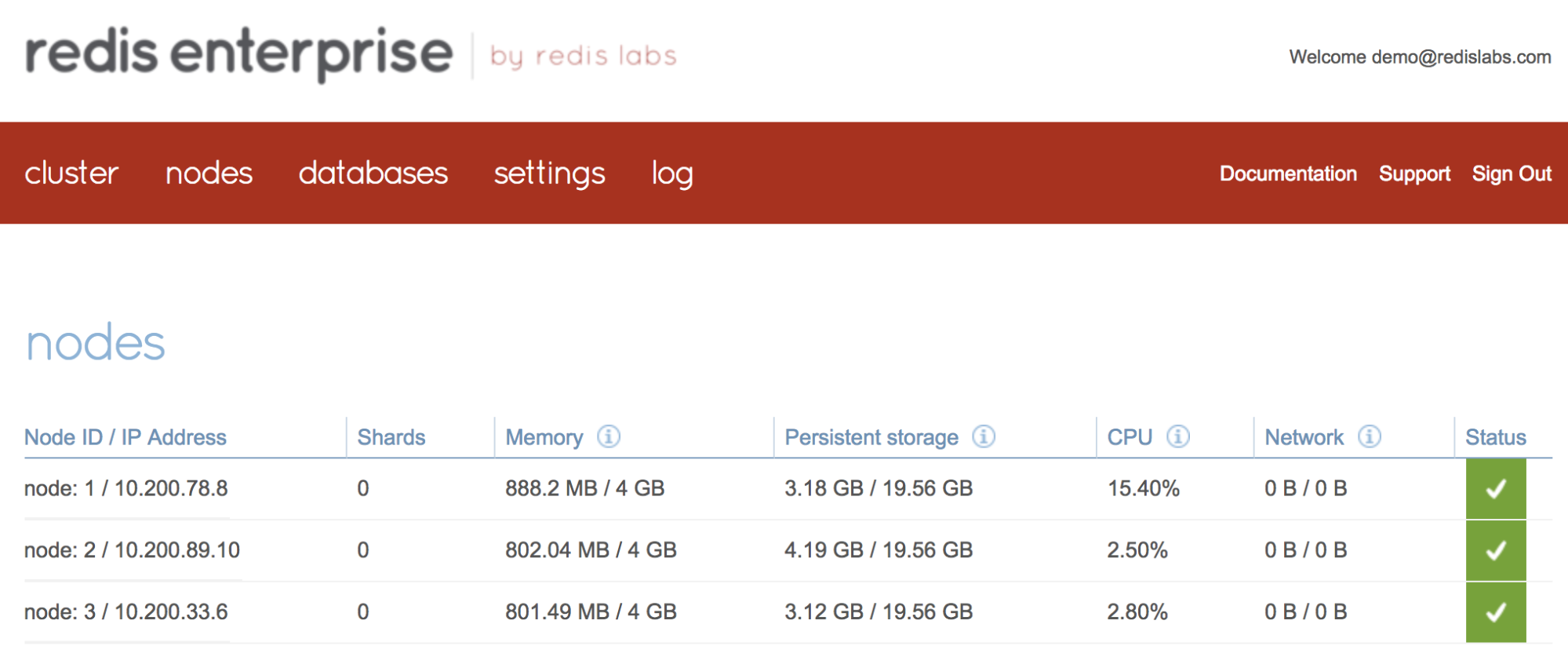
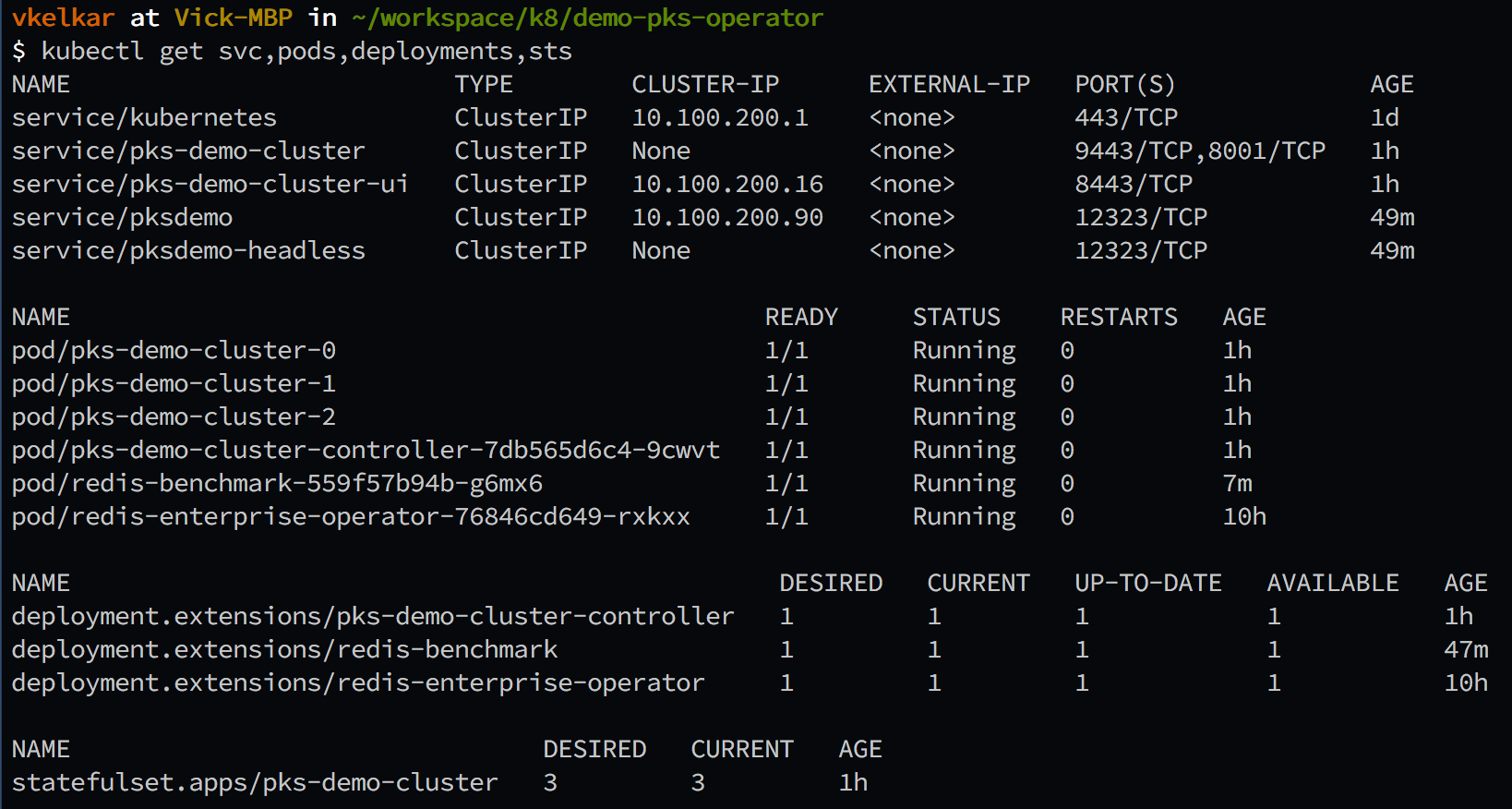
- Verify all deployed Redis Enterprise resources on the PKS cluster. This image shows a three-node Redis Enterprise deployment footprint:
| $ pks cluster redislabs | |
| Name: | redislabs |
| Plan Name: | large |
| UUID: | 5f4af2c0-5330-4dae-bdfc-6251ea3eecf2 |
| Last Action: | CREATE |
| Last Action State: | succeeded |
| Last Action Description: | Instance provisioning completed |
| Kubernetes Master Host: | 104.196.4.15 |
| Kubernetes Master Port: | 8443 |
| Worker Nodes: | 4 |
| Kubernetes Master IP(s): | 192.168.20.46, 192.168.20.47, 192.168.20.45 |
Benchmarking Redis Enterprise on PKS
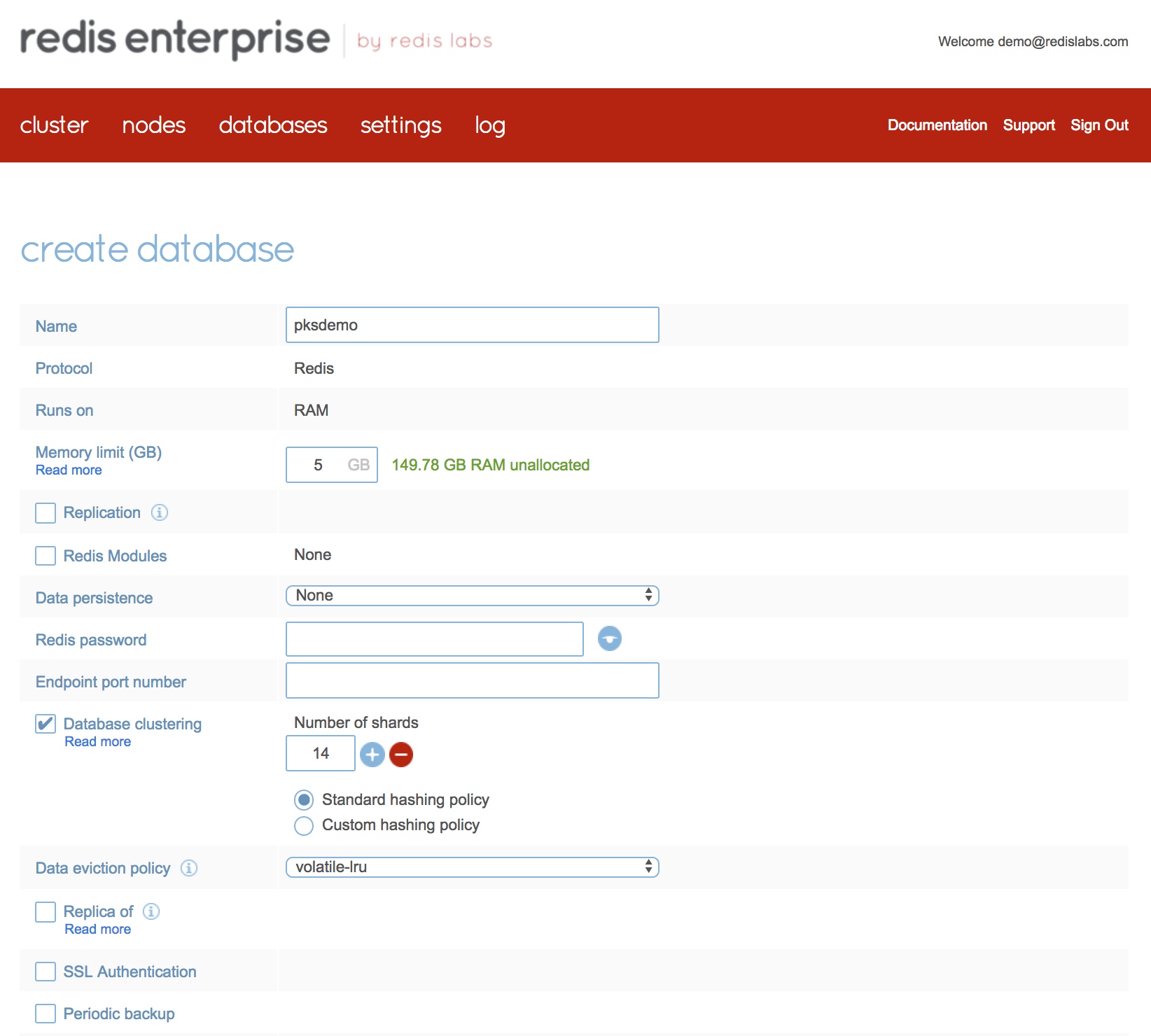
In order to measure performance, you can create a Redis database using the Redis Enterprise UI (or API) with the following parameters (Note: this setup assumes there are enough cores in the Kubernetes node to support Redis Enterprise cluster. In the example below we used a 14-shard database):
Next, deploy memtier_benchmark on another POD on the same Kubernetes cluster and run memtier_benchmark with the following parameters:
-d 100 -pipeline=35 -c 10 -t 8 -n 2000000 -ratio=1:5 -key-pattern=G:G -key-stddev=3 -distinct-client-seed -randomize
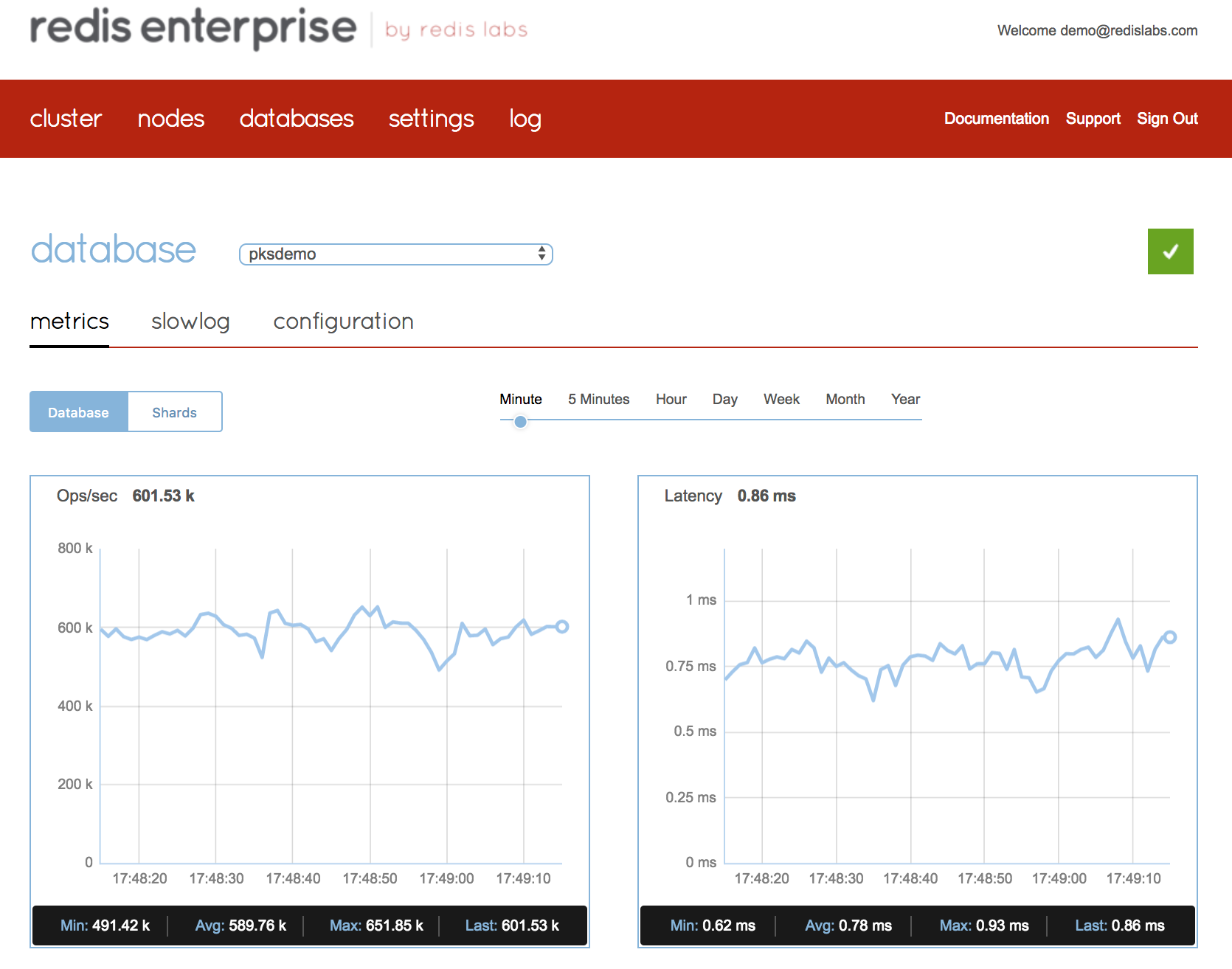
Use the metrics screen in the Redis Enterprise UI to monitor the performance of your database under load. As you can see in the figure below, Redis Enterprise can easily reach over 0.5M ops/sec using just one of the cluster nodes over Kubernetes infrastructure, while keeping latency under sub-millisecond.
 What's Next?
What's Next?
In this blog post, we demonstrated a simplified deployment of PKS by deploying all the resources on a flat network. To write this blog, we used the tech-preview version of the Redis Enterprise release for PKS. As we work towards general availability, we will continue to explore our PKS integration efforts around areas of network segmentation as well as the Kubernetes ingress primitive. Furthermore, we will soon add support for Active-Active geo-distributed Redis CRDTs over PKS to serve globally distributed applications.
If you would like to start experimenting with our Redis Enterprise release for PKS, please contact [email protected] so that we can help you with your Redis needs.
Published at DZone with permission of Vick Kelkar. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments