Reducing RAG Hallucinations With Relationship-Aware Retrieval
An architectural idea and how it addresses the retrieval weaknesses that lead to hallucinations, with a reference implementation using RudraDB.
Join the DZone community and get the full member experience.
Join For FreeRetrieval-augmented generation (RAG) is now the default pattern for grounding large language models in private or domain-specific knowledge. Yet most RAG systems still hallucinate, and the cause is rarely the model itself. It is the retrieval step. A language model can only reason over the passages it is handed; when retrieval returns an incomplete or disconnected set of passages, the model quietly fills the gaps with plausible-sounding but unsupported text. The retrieval layer, in other words, is where trustworthiness is won or lost.
This article examines a specific architectural idea — relationship-aware retrieval — and how it addresses the retrieval weaknesses that lead to hallucination. The reference implementation is RudraDB-Opin, a free, relationship-aware vector database. RudraDB-Opin is the free edition built for learning, prototyping, and real projects: it supports up to 100,000 vectors and 500,000 relationships — ample room to model a substantial knowledge base and demonstrate every retrieval pattern discussed here.
The Weak Link in RAG Is Similarity-Only Retrieval
A conventional RAG pipeline embeds each document chunk into a vector, stores the vectors, and at query time returns the k chunks whose embeddings are closest to the query embedding. This works well when the answer lives inside a single passage that happens to be lexically and semantically similar to the question.
It breaks down in a common and important case: when the information needed to answer correctly is connected to the matched passage rather than being similar to it.
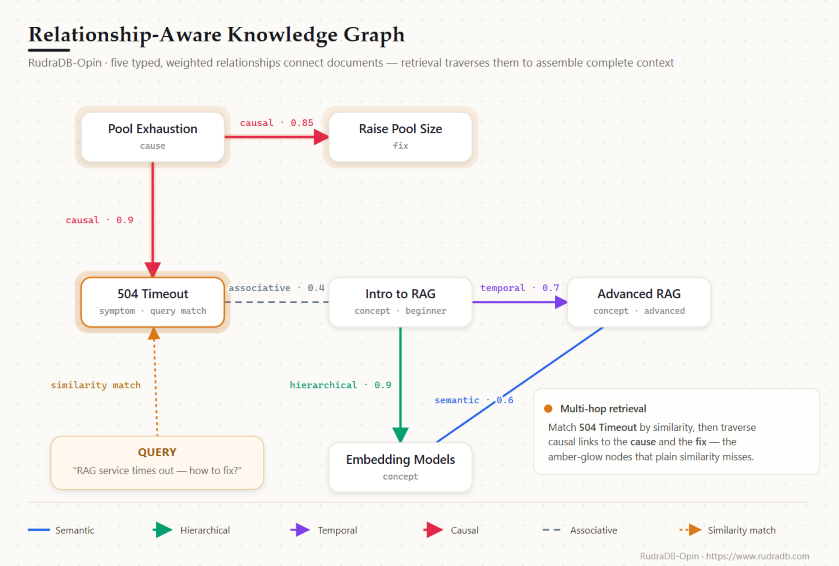
Consider a troubleshooting knowledge base. A user asks why a service intermittently returns timeout errors. Similarity search retrieves the passage describing the timeout symptom. But the actual remediation lives in a separate passage about a connection-pool setting — a passage that shares almost no vocabulary with the question and therefore ranks low. The cause-and-effect link between the symptom and the fix is real, but a similarity index has no representation of it. The model receives the symptom without the cause, and a hallucinated remedy is the predictable result.
This is the structural blind spot of similarity-only retrieval: it can find passages that look alike, but it cannot find passages that belong together.
Adding the Missing Dimension: Relationships Between Items
Relationship-aware retrieval keeps similarity search and adds an explicit model of how items relate to one another. In RudraDB-Opin, every stored vector can carry typed, directional relationships to other vectors, and search can traverse those relationships to assemble context that similarity alone would never surface.
RudraDB-Opin defines five relationship types, each mapping to a connection pattern that appears repeatedly in real knowledge bases:
| Relationship type |
what it captures | typical rag use |
|---|---|---|
semantic |
Topical or meaning-based connection | Related articles, alternative explanations of the same concept |
hierarchical |
Parent–child or part-of structure | A concept and its prerequisites; a section and its subsections |
temporal |
Order or time-based progression | Sequential steps, course, or workflow order |
causal |
Cause-and-effect or problem–solution | Symptom-to-fix, question-to-answer, trigger-to-outcome |
associative |
General, looser association | Cross-references, "see also," recommendations |
The important property is that these relationships are first-class data, not a side effect of vector proximity. A causal link between a symptom passage and its fix exists in the graph, whether or not the two embeddings are close. Retrieval can therefore follow the link directly.
How Relationship-Aware Retrieval Works in Practice
RudraDB-Opin is intentionally zero-configuration. It detects the embedding dimension from the first vector you add, so it works with any model — Sentence Transformers (384-D), HuggingFace models (768-D), OpenAI embeddings (1536-D) — without any setup change.
Start by installing the package and loading your chunks:
pip install rudradb-opinimport rudradb
import numpy as np
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("all-MiniLM-L6-v2") # 384-dimensional embeddings
db = rudradb.RudraDB() # dimension auto-detected on first add
docs = {
"timeout_symptom": "The service intermittently returns HTTP 504 timeout errors under load.",
"pool_setting": "Connection pool exhaustion causes requests to queue until they time out.",
"pool_fix": "Raise the maximum pool size and reduce idle connection lifetime.",
"load_testing": "Reproduce timeouts by driving concurrent requests above steady-state traffic.",
}
for doc_id, text in docs.items():
embedding = model.encode(text).astype(np.float32)
db.add_vector(doc_id, embedding, {"text": text})
print(f"Embedding dimension auto-detected: {db.dimension()}D")
Next, model the connections you already understand about your own content. This is the step that separates relationship-aware retrieval from everything else: you encode the structure of the knowledge, not just its surface text.
# The symptom is caused by pool exhaustion (cause-effect)
db.add_relationship("timeout_symptom", "pool_setting", "causal", 0.9)
# Pool exhaustion is resolved by the fix (problem-solution)
db.add_relationship("pool_setting", "pool_fix", "causal", 0.9)
# Load testing is the procedure used to reproduce the symptom (related procedure)
db.add_relationship("timeout_symptom", "load_testing", "associative", 0.6)
Now run a relationship-aware search. Enabling include_relationships tells the engine to rank and expand results using both vector similarity and the relationships you modeled, while max_hops bounds how far it will traverse:
query = "Why does the service keep timing out and how do I fix it?"
q_emb = model.encode(query).astype(np.float32)
results = db.search(q_emb, rudradb.SearchParams(
top_k=5,
include_relationships=True, # traverse modeled relationships, not just cosine distance
max_hops=2, # reach context up to two relationships away
relationship_weight=0.3 # blend similarity score with relationship strength
))The query is most similar to the symptom passage, so similarity alone would return that passage and stop. Relationship-aware search instead follows the causal edges outward — symptom → cause → fix — and brings the remediation into the result set even though it is lexically distant from the question.
You can inspect exactly how a passage connects to the rest of the graph, which is invaluable when debugging retrieval quality:
for vector, hops in db.get_connected_vectors("timeout_symptom", max_hops=2):
reach = "direct match" if hops == 0 else f"{hops}-hop connection"
print(f"{vector['id']:18} {reach}")The retrieved passages — the matched chunk plus the chunks reached through its relationships — are then passed into the LLM prompt as grounded context, exactly as in any RAG pipeline. The difference is that the context is now complete with respect to the question.
Why Relationships Reduce Hallucination
Relationship-aware retrieval attacks hallucination at its source — incomplete or incoherent context — in three concrete ways.
It closes context gaps. Hallucination most often occurs when an answer requires a fact that retrieval failed to supply, forcing the model to invent it. By following hierarchical and causal relationships, the retriever delivers the prerequisite definition, the upstream cause, or the corresponding solution alongside the matched passage. The model is no longer asked to bridge a gap; the bridge was retrieved with the rest of the evidence.
It grounds answers in explicit, traceable connections. A similarity score is a statistical proximity, not a statement of fact. A modeled relationship is an explicit assertion — this symptom is caused by that setting — authored against your real knowledge. When the answer follows a chain of declared relationships, every step of the supporting context can be traced back to a connection that someone deliberately encoded, rather than to incidental vector closeness. That traceability is what makes the retrieved context auditable.
It keeps the retrieved context coherent. Temporal and hierarchical relationships preserve order and structure. When a question concerns a multi-step process, sequential relationships ensure the steps arrive together and in order, instead of as a scattered set of independently top-ranked fragments. Coherent context produces coherent answers and removes a frequent trigger for the model to "smooth over" missing or out-of-order steps.
Why It Fetches More Relevant Information
There is a difference between similar and relevant. Similarity measures resemblance; relevance measures whether a passage actually helps answer the question. The two overlap, but they are not the same — and similarity-only retrieval optimizes for the wrong one whenever the truly useful passage does not resemble the query.
Relationship-aware retrieval recovers relevance that similarity ranking discards. A prerequisite concept, a downstream consequence, or a paired solution is often highly relevant while being only loosely similar. Because RudraDB-Opin can reach those passages through relationships — and blends relationship strength with similarity via relationship_weight — it surfaces context that a pure vector ranking would push far down the list or omit entirely.
In practice, this means fewer "the answer was in the knowledge base, but the model never saw it" failures.
RudraDB-Opin vs. Traditional and Hybrid Vector Databases
It is worth being precise about what relationship-aware retrieval adds relative to the two retrieval architectures most teams already use.
| Capability | Traditional Vector Database | Hybrid Traditional Vector Database |
RudraDB-Opin |
|---|---|---|---|
| Core retrieval primitive | Dense vector similarity (e.g., cosine) | Dense similarity + lexical/keyword (e.g., BM25) + metadata filters | Dense similarity + typed relationships + bounded multi-hop traversal |
| Model of connections between items | None — items are independent | None — items are still scored independently | First-class: 5 relationship types (semantic, hierarchical, temporal, causal, associative) |
| Retrieving related-but-dissimilar context | Missed | Caught only when vocabulary overlaps | Reached by following modeled relationships |
| Multi-hop context | Not supported | Not supported | Supported (up to 2 hops in the Opin edition) |
| Typical effect on RAG | Context gaps the model may fill by guessing | Fewer lexical-mismatch gaps; connection gaps remain | Prerequisite, causal, and sequential context retrieved together |
| Setup | Specify dimension, build index | Dimension + index + analyzers/weights | Zero-config; embedding dimension auto-detected |
A Traditional Vector Database ranks every chunk independently by embedding distance. A Hybrid Traditional Vector Database improves recall on vocabulary mismatch by adding keyword search and metadata filtering on top of similarity — a genuine improvement, but one that still scores each item in isolation. Neither architecture has any notion that one chunk depends on, causes, or precedes another. RudraDB-Opin adds exactly that missing layer: an explicit, traversable model of the connections between items, which is precisely the structure RAG needs to retrieve complete and coherent context.
Where RudraDB-Opin Fits
RudraDB-Opin is the free edition, distributed under an MIT license and built for learning, tutorials, hackathons, and proof-of-concept work. Its 100,000-vector, 500,000-relationship capacity is generous enough to prototype a relationship-aware retriever, validate the pattern against your own content, and benchmark it against a similarity-only baseline. It works on Windows, macOS, and Linux, requires only Python 3.8+ and NumPy, and integrates with the embedding stacks teams already use, including OpenAI, HuggingFace, Sentence Transformers, and LangChain.
When a prototype outgrows that envelope, the data and the API carry forward to the full RudraDB for production scale, so the modeling work done at the prototype stage is not thrown away.
Conclusion
RAG quality is a retrieval problem before it is a model problem, and similarity-only retrieval has a structural blind spot: it cannot represent how pieces of knowledge connect. Relationship-aware retrieval closes that gap by treating connections — semantic, hierarchical, temporal, causal, and associative — as first-class, traversable data. The result is context that is more complete, more coherent, and more genuinely relevant, which is the most direct lever available for reducing hallucination in a grounded system.
RudraDB-Opin makes the pattern tangible in a few lines of code, with the capacity to back a real prototype.
Key takeaways:
- Most RAG hallucinations originate in retrieval, not generation; incomplete context forces the model to guess.
- Similarity finds passages that look alike; relationships find passages that belong together — and both matter.
- Modeling typed relationships lets retrieval follow causal, hierarchical, and sequential links to context that similarity ranking misses.
- Traditional and hybrid vector databases score items independently; relationship-aware retrieval adds the connection layer RAG needs.
RudraDB-Opin — Learn more, read the documentation, and install the free package at https://www.rudradb.com.
Opinions expressed by DZone contributors are their own.
Comments