RNN, Seq2Seq, Transformers: Introduction to Neural Architectures Commonly Used in NLP
In this article, we’ll give you a high-level introduction to deep learning in NLP, and we’ll explain, briefly, how an RNN and a transformer work.
Join the DZone community and get the full member experience.
Join For FreeJust a few years ago, RNNs and their gated variants (that added multiplicative interactions and mechanisms for better gradient transfer) were the most popular architectures used for NLP.
Prominent researchers, such as Andrey Karpathy, were singing odes to RNNs' unreasonable effectiveness and large corporations were keen on adopting the models to put them into virtual agents and other NLP applications.
Now that Transformers (BERT, GPT-2) have come along, the community rarely even mentions recurrent nets.
In this article, we’ll give you a high-level introduction to deep learning in NLP; we’ll explain, briefly, how an RNN and a transformer work and which specific properties of the latter make it at a better architecture for a wide range of NLP tasks.
Here we go!
Let’s start with RNNs and why, up until recently, they were considered special.
Recurrent neural networks are a family of neural architectures with a cool property — a looping mechanism — that makes them a natural choice for processing sequential data of variable length. RNNs, unlike standard NNs, can hang on to information from previous layers while taking in a new input.
Here’s how it works
Say we’re building an e-commerce chatbot consisting of an RNN that processes text and a feed-forward net that predicts the intent behind it. The bot receives this message: "Hi! Do you guys have this shirt in any different colors?”
We have, as our input, 11 words (11 word embeddings) and the sequence, chopped into tokens, looks like this I1, I2…..I11.
The core idea behind RNN is that it applies the same weight matrix to every single input and also produces a sequence of hidden states (there’s going to be as many of them as we have inputs) that carry information from previous time steps.
Each hidden state (Ht) is computed based on the previous hidden state (Ht-1) and the current input (It); As we’ve mentioned, they’re really the same state that keeps being modified on each time step.
So, the processing starts with the first word embedding (I1) going into the model along with the initial hidden state (H0); inside the RNN's first unit, a linear transformation is performed on both I1 and H0, a bias is added, and the final value is put through some kind of nonlinearity (sigmoid, ReLU, etc.) — that’s how we get H1.
Afterwards, the model eats I2 paired with H1 and performs the same computations, then I3 with H2 go in, followed by I4 with H3, and so on until we crunch through the entire sequence.
Since we’re using the same weight matrix over and over, the RNN can work with lengthy sequences and not increase in size itself. Another advantage is that, theoretically, each time step can have access to data from many steps ago.
The issues
RNN’s distinctive feature — that it uses the same layer many times — is also what makes it extremely prone to the effects of vanishing and exploding gradients. In practice, it’s too difficult for these networks to preserve data over many steps.
Also, RNNs don’t see any hierarchy in a sequence. The models alter the hidden state every time a new input is being processed despite how insignificant it might be. Therefore, the data from earlier layers may end up being completely washed out by the time the network gets to the end of the sequence.
This means that in our example “Hi! Do you guys have this shirt in any different colors?” the feed-forward net may be left trying to predict the intent based on just “any different colors?” which wouldn’t be easy to do even for a human.
Another inherent disadvantage lies in the nature of sequential processing: since parts of the input are being processed one at a time (we can’t compute H2 unless we have H1) the network’s computations, overall, are very slow.
The gated variants
To fight the issues discussed above, different architectural modifications have been proposed to improve RNNs, the most popular being Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GTU).
The main idea behind LSTM, roughly speaking, is to have a cell state — a memory storage — inside every unit in addition to the hidden state (they are both vectors of the same size).
Also, these models have three gates (forget gate, input gate, output gate) that determine which info to write, read, or erase from the cell state.
All the gates are vectors of the same length as the hidden state, and here’s exactly what they’re for:
- Forget gate determines what should be kept vs. what should be erased from the previous time step.
- The input gate determines what new information should be let in into the cell state.
- The output gate determines what data from the cell should be incorporated into the hidden state.
They’re all computed using the sigmoid function so they always output values between 0 and 1.
If a gate produces something closer to 1, it's considered open (data can be included in the cell state) and if it gives out a value closer to 0, the information is to be ignored.
GRUs operate similarly to LSTMs, but they’re way simpler in architecture; they do away with cell states and compute two gates instead of three before the hidden state.
The point of GRUs is to retain the power and robustness of LSTMs (in terms of mitigating vanishing gradients) and get rid of its complexities. GRU’s gates are:
Update gate determines what parts of the hidden state should be modified vs. what parts should be preserved. In a way, it does what input and forget gates do in LSTMs.
Reset gate determines what parts of the hidden state matter now. If it outputs a number closer to 1, we can just copy the previous state and free the network from having to update weights (no weight adjustments - no vanishing gradient.)
Both LSTMs and GRUs are capable of controlling the flow of information, grasping long-range dependencies, and having error messages flow at different strengths depending on the input.
Sequence-to-sequence (seq2seq) models and attention mechanisms
Sequence to sequence models, once so popular in the domain of neural machine translation (NMT), consist of two RNNs — an encoder and a decoder — stacked together.
Encoder processes inputs sequentially and produces a thought vector that holds data from every time step. Then, its output is passed on to decoder that uses that context to predict an appropriate target sequence (a translation, a chatbot’s reply, etc.)
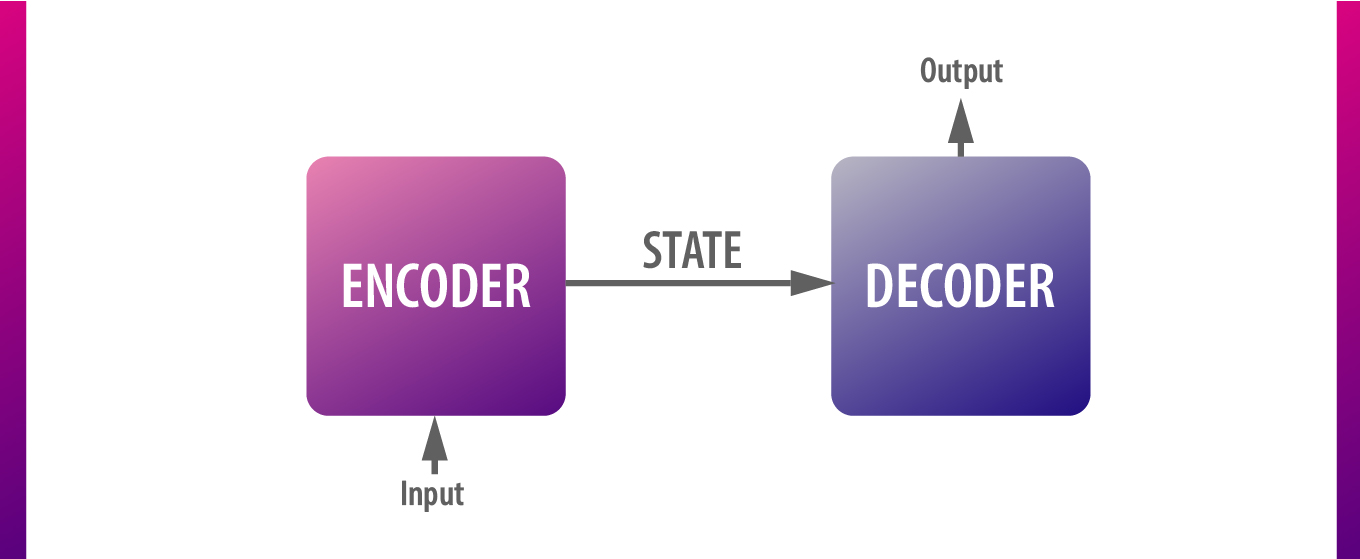
The problem with a vanilla seq2seq, however, is that it tries to cram the context of the entire input into one fixed-sized vector, and there’s a limit to how much data it can carry.
Here’s where attention mechanisms help. They allow the decoder network to focus on relevant parts of the input when producing the output. They do so by adding an extra input to each decoding step that comes from the encoding steps.
RNN’s fall and transformers
Yes, we can have a lengthened short memory in RNNs using the LSTM build and even a long memory using attention. But we still can’t completely eliminate the impact of vanishing gradients, make these models (whose design inhibits parallel computing) faster, or get them to explicitly model long-range dependencies and hierarchy in sequences.
Transformer, a model introduced by researchers from Google in 2017, surmounts all RNN’s shortcomings. This new and revolutionary architecture enables us to do away with recurrent computations and achieve state-of-the-art results in a wide range of NLP tasks — NMT, question answering, etc. — by relying solely on attention mechanisms.
A transformer, too, consists of an encoder and a decoder. It actually has a stack of encoders on one side and a stack of decoders (with the same number of units) on the other side.
Encoders
Each encoder unit is comprised of a self-attention layer and a feed-forward layer.
Self-attention is the mechanism that allows a cell to compare the content of an input to all other inputs in the sequence and include the relationships between them into the embedding. If we’re talking about a word, self-attention allows representing which other words in a sentence it has strong relationships with.
In the transformer model, each position can interact with all the other positions in the input simultaneously; the network's computations are trivial to parallelize.
Self-attention layers are further enhanced by the multi-head attention mechanism that improves the model’s ability to focus on various positions and enables it to create representation subspaces (to have different weight matrices applied to the same input).
To establish the order of the input, Transformers add another vector to each embedding (this is known as positional encoding), which helps them recognize the position of each input in a sequence as well as distances between them.
Each encoder pushes its output up to the unit directly above it.
On the decoder side, the cells, too, have a self-attention layer, a feed-forward layer, and one additional element — an encoder decoder attention layer — in between. The decoder component in Transformers takes in the output from the top encoder — a series of attention vectors — and uses it to focus on relevant parts of the input when predicting target sequences.
Overall, transformers are lighter models than RNNs, they’re easier to train and lend themselves well to parallelization; they can learn long-range dependencies.
Concluding notes
The transformer architecture has become the base for many groundbreaking models.
Google researches used the ideas from the "Attention is all you need" paper to develop BERT — a powerful language representation model that can be easily adapted to various NLP tasks (through the addition of just one fine-tuned output layer) and OpenAI scientists have managed to create GPT-2 an unbelievably coherent language model that, according to them, is too dangerous to be released.
The multi-head attention technology is now being tried out in various areas of research. Soon, we might see it transform multiple industries in a profound way. This will be exciting.
Opinions expressed by DZone contributors are their own.
Comments