Exploring the Evolution of Transformers: From Basic To Advanced Architectures
This blog traces the evolution of Transformers from the original model to advanced architectures, highlighting significant advancements.
Join the DZone community and get the full member experience.
Join For FreeIn their seminal 2017 paper, "Attention Is All You Need," Vaswani et al. introduced the Transformer architecture, revolutionizing not only speech recognition technology but many other fields as well. This blog post explores the evolution of Transformers, tracing their development from the original design to the most advanced models, and highlighting significant advancements made along the way.
The Original Transformer
The original Transformer model introduced several groundbreaking concepts:
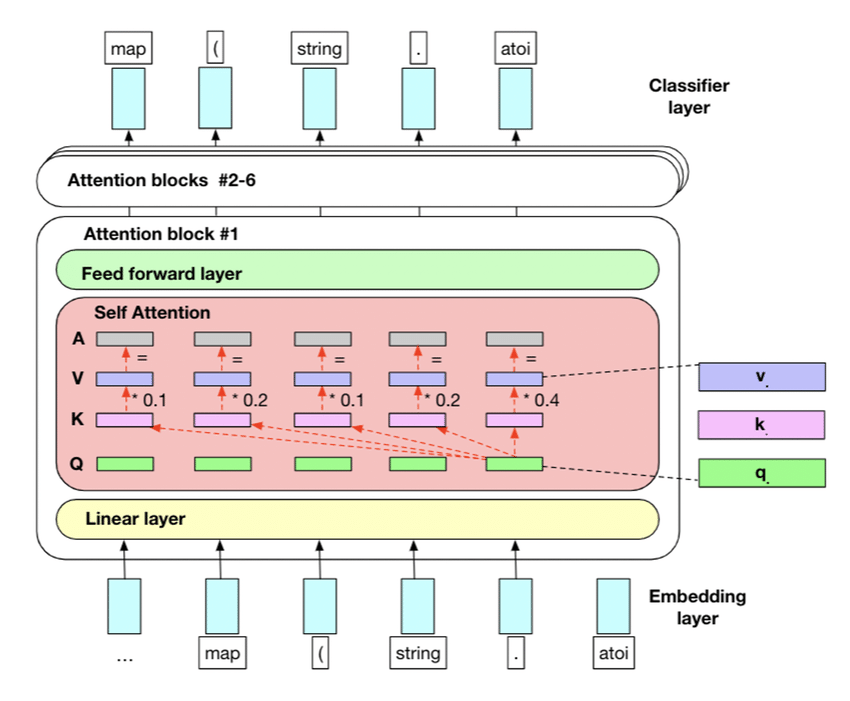
- Self-attention mechanism: This lets the model determine how important each component is in the input sequence.
- Positional encoding: Adds information about a token's position within a sequence, enabling the model to capture the order of the sequence.
- Multi-head attention: This feature allows the model to concurrently focus on different parts of the input sequence, enhancing its ability to understand complex relationships.
- Encoder-decoder architecture: Separates the processing of input and output sequences, enabling more efficient and effective sequence-to-sequence learning.
These elements combine to create a powerful and flexible architecture that outperforms previous sequence-to-sequence (S2S) models, especially in machine translation tasks.
Encoder-Decoder Transformers and Beyond
The original encoder-decoder structure has since been adapted and modified, leading to several notable advancements:
- BART (Bidirectional and auto-regressive transformers): Combines bidirectional encoding with autoregressive decoding, achieving notable success in text generation.
- T5 (Text-to-text transfer transformer): Recasts all NLP tasks as text-to-text problems, facilitating multi-tasking and transfer learning.
- mT5 (Multilingual T5): Expands T5's capabilities to 101 languages, showcasing its adaptability to multilingual contexts.
- MASS (Masked sequence to sequence pre-training): Introduces a new pre-training objective for sequence-to-sequence learning, enhancing model performance.
- UniLM (Unified language model): Integrates bidirectional, unidirectional, and sequence-to-sequence language modeling, offering a unified approach to various NLP tasks.
BERT and the Rise of Pre-Training
BERT (Bidirectional Encoder Representations from Transformers), launched by Google in 2018, marked a significant milestone in natural language processing. BERT popularized and perfected the concept of pre-training on large text corpora, leading to a paradigm shift in the approach to NLP tasks. Let's take a closer look at BERT's innovations and their impact.
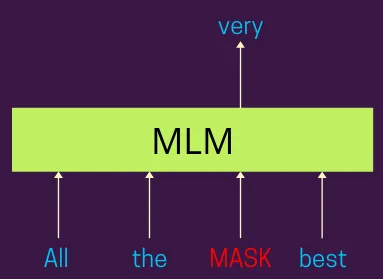
Masked Language Modeling (MLM)
- Process: Randomly masks 15% of tokens in each sequence. The model then attempts to predict these masked tokens based on the surrounding context.
- Bidirectional context: Unlike previous models that processed text either left-to-right or right-to-left, MLM allows BERT to consider the context from both directions simultaneously.
- Deeper understanding: This approach forces the model to develop a deeper understanding of the language, including syntax, semantics, and contextual relationships.
- Variant masking: To prevent the model from over-relying on [MASK] tokens during fine-tuning (since [MASK] does not appear during inference), 80% of the masked tokens are replaced by [MASK], 10% by random words, and 10% remain unchanged.
Next Sentence Prediction (NSP)
- Process: The model receives pairs of sentences and must predict whether the second sentence follows the first in the original text.
- Implementation: 50% of the time, the second sentence is the actual next sentence, and 50% of the time, it is a random sentence from the corpus.
- Purpose: This task helps BERT understand relationships between sentences, which is crucial for tasks like question answering and natural language inference.

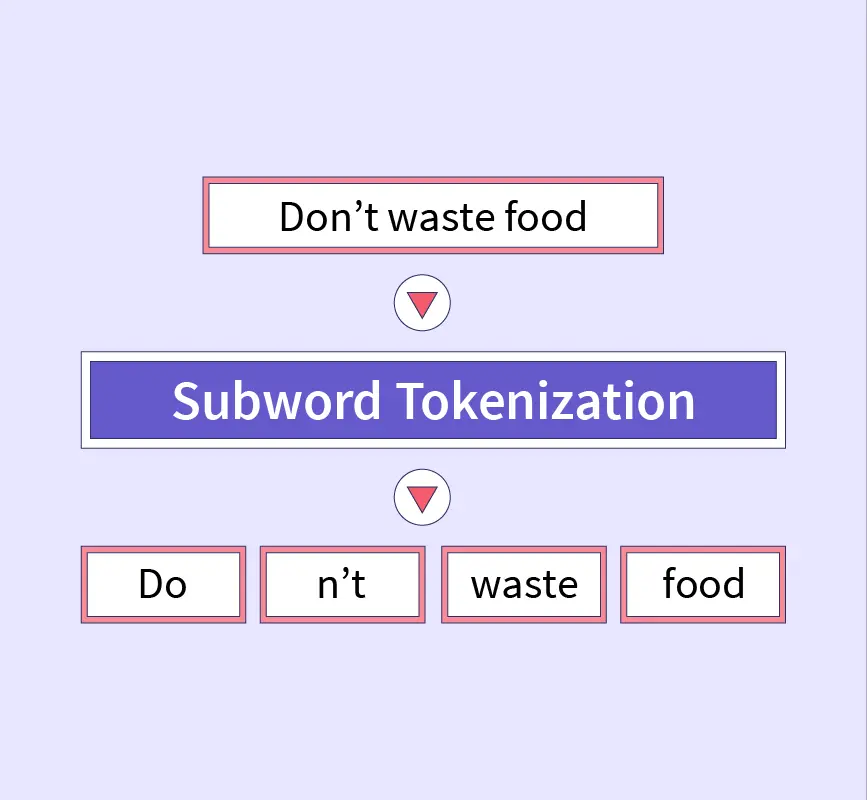
Subword Tokenization
- Process: Words are divided into subword units, balancing the size of the vocabulary and the ability to handle out-of-vocabulary words.
- Advantage: This approach allows BERT to handle a wide range of languages and efficiently process morphologically rich languages.
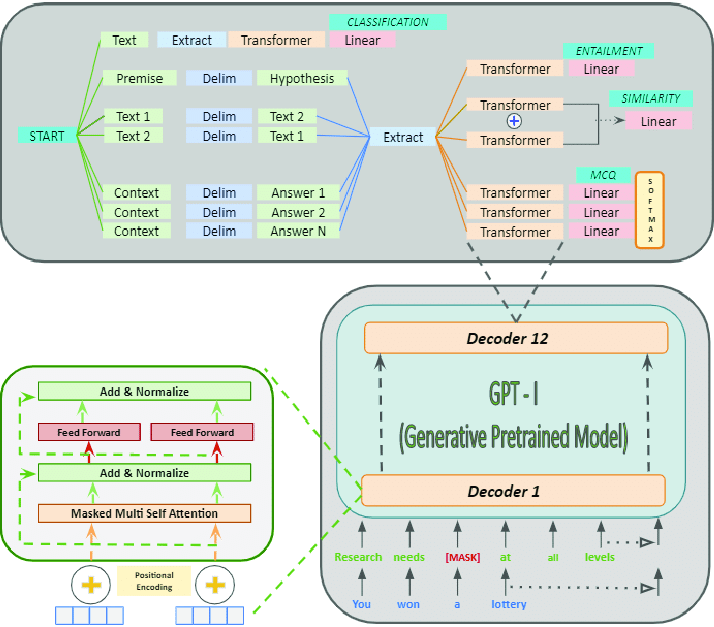
GPT: Generative Pre-Trained Transformers
OpenAI's Generative Pre-trained Transformer (GPT) series represents a significant advancement in language modeling, focusing on the Transformer decoder architecture for generation tasks. Each iteration of GPT has led to substantial improvements in scale, functionality, and impact on natural language processing.
GPT-1 (2018)
The first GPT model introduced the concept of pre-training for large-scale unsupervised language understanding:
- Architecture: Based on a Transformer decoder with 12 layers and 117 million parameters.
- Pre-training: Utilized a variety of online texts.
- Task: Predicted the next word, considering all previous words in the text.
- Innovation: Demonstrated that a single unsupervised model could be fine-tuned for different downstream tasks, achieving high performance without task-specific architectures.
- Implications: GPT-1 showcased the potential of transfer learning in NLP, where a model pre-trained on a large corpus could be fine-tuned for specific tasks with relatively little labeled data.
GPT-2 (2019)
GPT-2 significantly increased the model size and exhibited impressive zero-shot learning capabilities:
- Architecture: The largest version had 1.5 billion parameters, more than 10 times greater than GPT-1.
- Training data: Used a much larger and more diverse dataset of web pages.
- Features: Demonstrated the ability to generate coherent and contextually relevant text on a variety of topics and styles.
- Zero-shot learning: Showed the ability to perform tasks it was not specifically trained for by simply providing instructions in the input prompt.
- Impact: GPT-2 highlighted the scalability of language models and sparked discussions about the ethical implications of powerful text generation systems.
GPT-3 (2020)
GPT-3 represented a huge leap in scale and capabilities:
- Architecture: Consisted of 175 billion parameters, over 100 times larger than GPT-2.
- Training data: Utilized a vast collection of texts from the internet, books, and Wikipedia.
- Few-shot learning: Demonstrated remarkable ability to perform new tasks with only a few examples or prompts, without the need for fine-tuning.
- Versatility: Exhibited proficiency in a wide range of tasks, including translation, question answering, text summarization, and even basic coding.
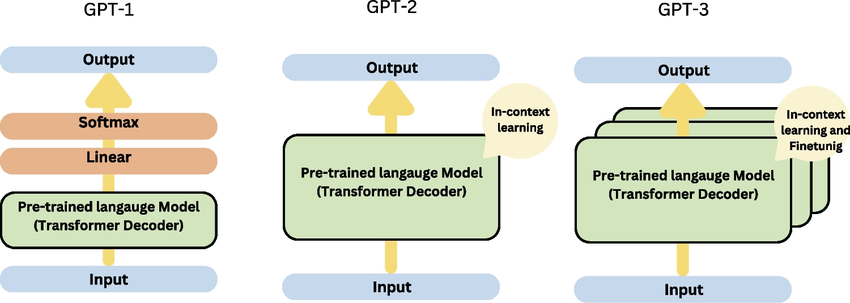
GPT-4 (2023)
GPT-4 further pushes the boundaries of what is possible with language models, building on the foundations laid by its predecessors.
- Architecture: While specific architectural details and the number of parameters have not been publicly disclosed, GPT-4 is believed to be significantly larger and more complex than GPT-3, with enhancements to its underlying architecture to improve efficiency and performance.
- Training data: GPT-4 was trained on an even more extensive and diverse dataset, including a wide range of internet texts, academic papers, books, and other sources, ensuring a comprehensive understanding of various subjects.
- Advanced few-shot and zero-shot learning: GPT-4 exhibits an even greater ability to perform new tasks with minimal examples, further reducing the need for task-specific fine-tuning.
- Enhanced contextual understanding: Improvements in contextual awareness allow GPT-4 to generate more accurate and contextually appropriate responses, making it even more effective in applications like dialogue systems, content generation, and complex problem-solving.
- Multimodal capabilities: GPT-4 integrates text with other modalities, such as images and possibly audio, enabling more sophisticated and versatile AI applications that can process and generate content across different media types.
- Ethical considerations and safety: OpenAI has placed a strong emphasis on the ethical deployment of GPT-4, implementing advanced safety mechanisms to mitigate potential misuse and ensure that the technology is used responsibly.
Innovations in Attention Mechanisms
Researchers have proposed various modifications to the attention mechanism, leading to significant advancements:
- Sparse attention: Allows for more efficient processing of long sequences by focusing on a subset of relevant elements.
- Adaptive attention: Dynamically adjusts the attention span based on the input, enhancing the model's ability to handle diverse tasks.
- Cross-attention variants: Improve how decoders attend to encoder outputs, resulting in more accurate and contextually relevant generations.
Conclusion
The evolution of Transformer architectures has been remarkable. From their initial introduction to the current state-of-the-art models, Transformers have consistently pushed the boundaries of what's possible in artificial intelligence. The versatility of the encoder-decoder structure, combined with ongoing innovations in attention mechanisms and model architectures, continues to drive progress in NLP and beyond. As research continues, we can expect further innovations that will expand the capabilities and applications of these powerful models across various domains.
Opinions expressed by DZone contributors are their own.
Comments