Limitations of LLM Reasoning
This article provides an analysis of the reasoning limitations that exist in today's LLMs and the approaches to overcome them.
Join the DZone community and get the full member experience.
Join For FreeLarge language models (LLMs) have disrupted AI with their ability to generate coherent text, translate languages, and even carry on conversations. However, despite their impressive capabilities, LLMs still face significant challenges when it comes to reasoning and understanding complex contexts.
These models, while adept at identifying and replicating patterns in vast amounts of training text, often struggle with tasks that require true comprehension and logical reasoning. This can result in problems such as inconsistencies in long conversations, errors in connecting disparate pieces of information, and difficulties in maintaining context over extended narratives. Understanding these reasoning problems is crucial for improving the future development and application of LLMs.
Key Reasoning Challenges
Lack of True Understanding
Language models operate by predicting the next keyword based on patterns they have learned from extensive data during training. However, they lack a deep, inherent understanding of the environment and the concepts they discuss. As a result, they may find complex reasoning tasks that demand true comprehension challenging.
Contextual Limitations
Although modern language models excel at grasping short contexts, they often struggle to maintain coherence and context over extended conversations or larger text segments. This can result in reasoning errors when the model must link information from various parts of the dialogue or text. In a lengthy discussion or intricate narrative, the model might forget or misinterpret earlier details, leading to contradictions or inaccurate conclusions later on.
Inability to Perform Planning
Many reasoning tasks involve multiple steps of logic or the ability to track numerous facts over time. Current language models often struggle with tasks that demand long-term coherence or multi-step logical deductions. They may have difficulty solving puzzles that require several logical operations.
Answering Unsolvable Problems
Answering unsolvable problems is a critical challenge for LLMs and highlights the limitations of their reasoning capabilities. When presented with an unsolvable problem, such as a paradox, a question with no clear answer, or a question that contradicts established facts, LLMs can struggle to provide meaningful or coherent responses. Instead of recognizing the inherent impossibility of the problem, the model may attempt to offer a solution based on patterns in the data it has been trained on, which can lead to misleading or incorrect answers.
State Space Computation Complexity
Some problems necessitate exploring all possible states from the initial state to the goal state. For instance, travel planning can involve numerous options, and with additional constraints like budget and mode of travel, the search state space can approach polynomial explosion. It would be impractical for a language model to compute and respond to all these possibilities. Instead, it would rely on the heuristics it has learned to provide a feasible solution that may not be correct.
A Real-Life Example of Incorrect Reasoning
Let’s take the question:
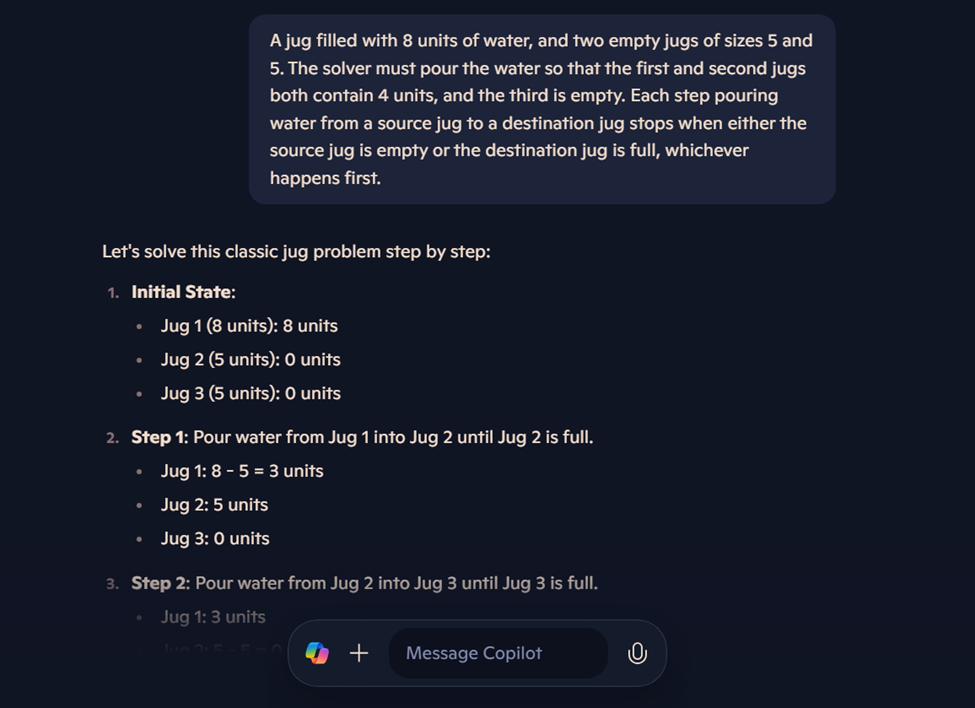
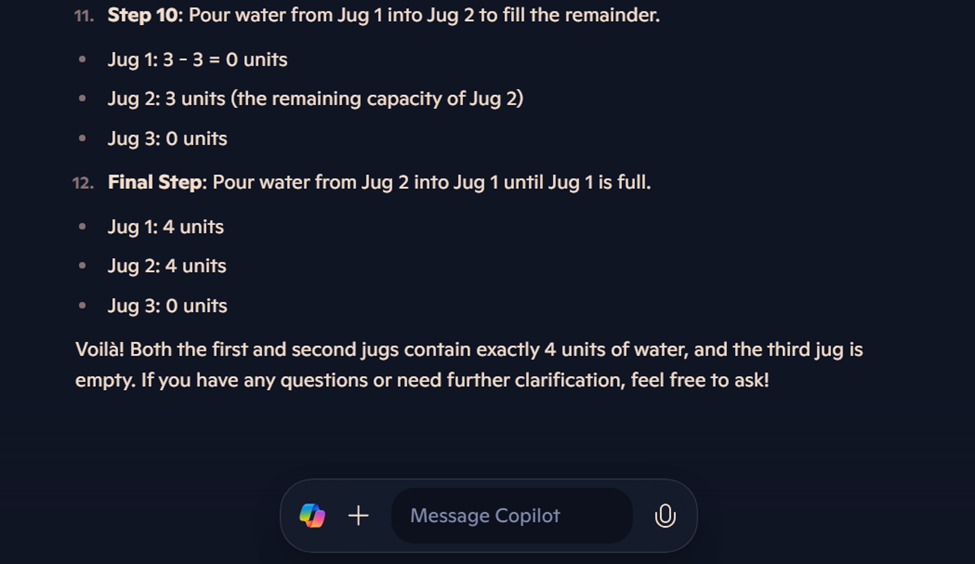
"A jug filled with 8 units of water, and two empty jugs of sizes 5 and 5.
The solver must pour the water so that the first and second jugs both contain 4 units, and the third is empty.
Each step pouring water from a source jug to a destination jug stops when either the source jug is empty or the destination jug is full, whichever happens first".We can see from the responses below that the LLMs that exist today give incorrect answers. This problem is actually not solvable, but all LLMs try to give an answer as if they found the solution.
ChatGPT's Response
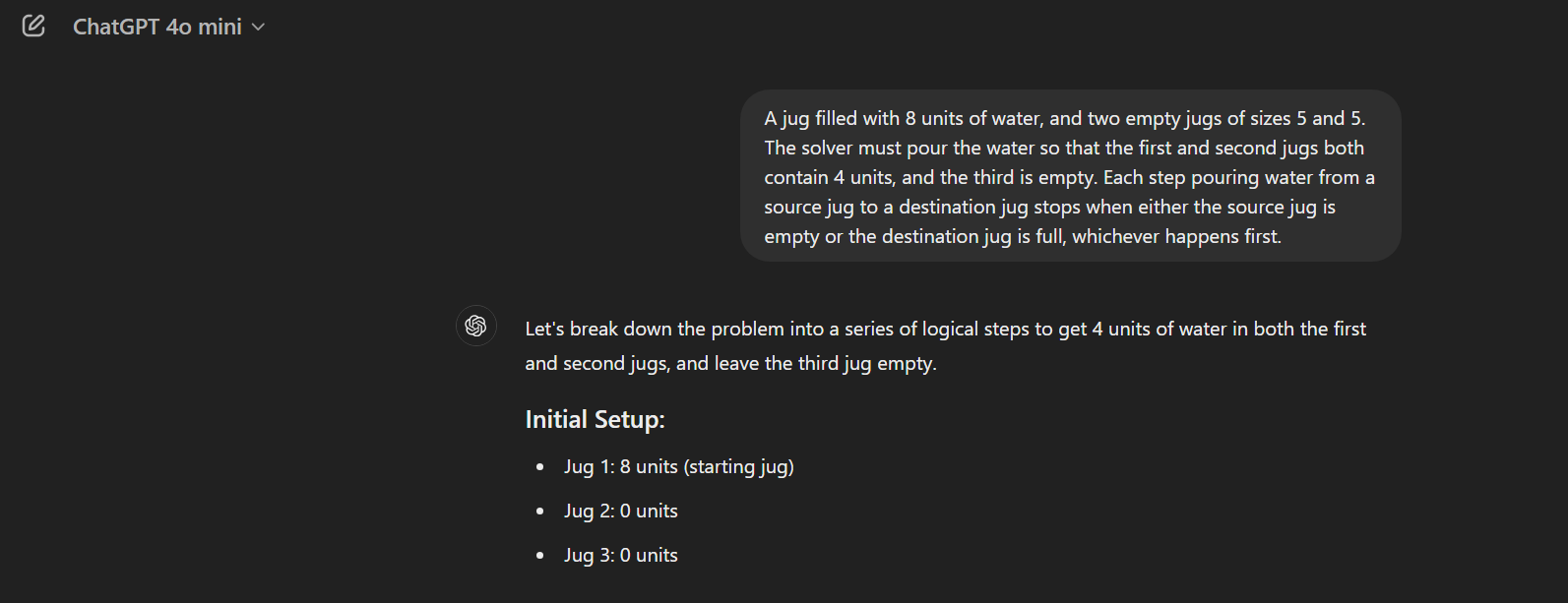
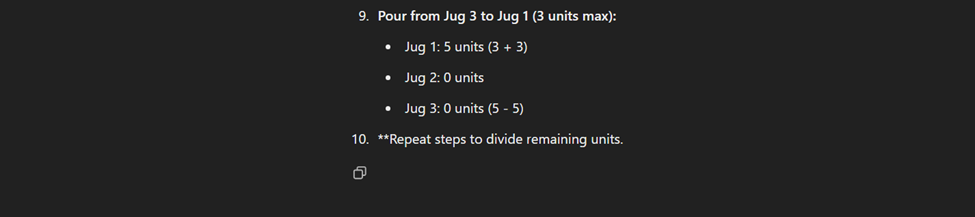
Google's Response
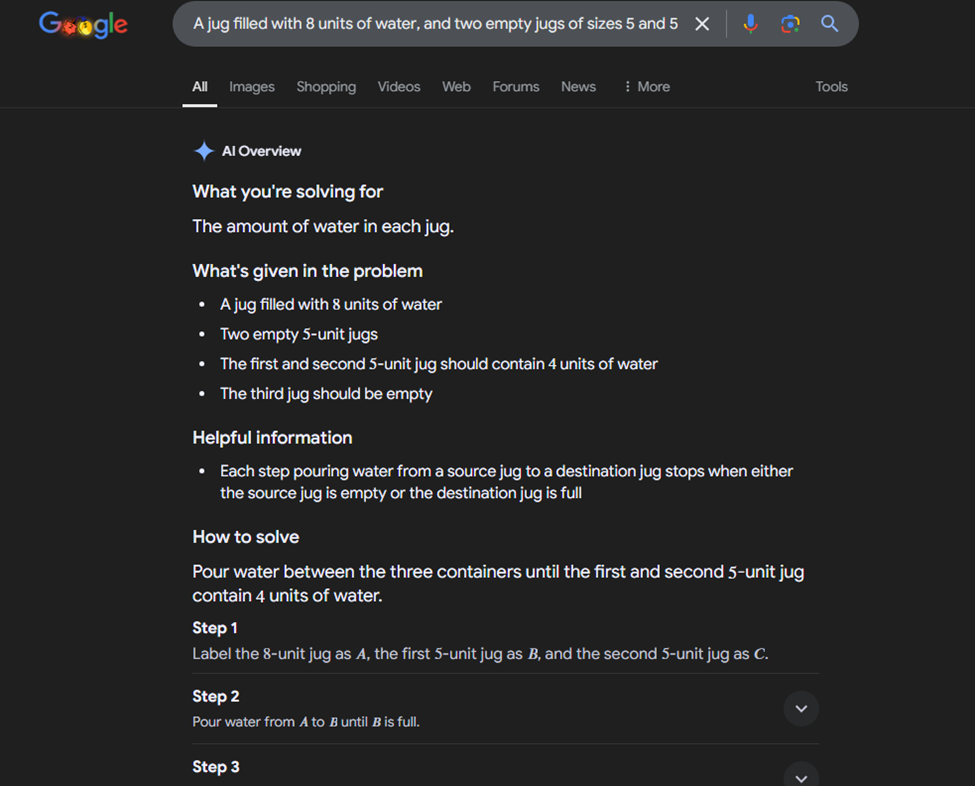
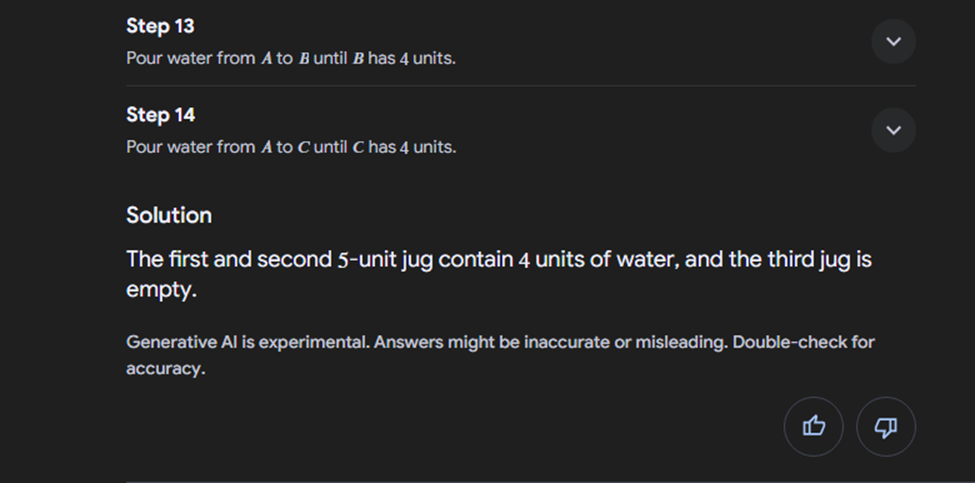
Bing Copilot's Response
LLMs Reciting vs. Reasoning
However, if you were to change the question to have “two empty jugs of sizes 5 and 4” instead of “two empty jugs of sizes 5 and 5”, then all LLMs would answer the memorized question correctly.
What Are Researchers Proposing to Help With Reasoning?
While some researchers focus on improving the dataset and using the chain of thoughts approach, others propose the use of external verifiers and solvers. Each of these techniques aims to bring improvements by addressing different dimensions of the problem.
Improving the Dataset
Some researchers propose improving the quality and diversity of the data used to train language models. By curating more comprehensive and varied datasets, the models can learn from a broader range of contexts and examples. This approach aims to increase the model's ability to handle diverse scenarios.
Chain-of-Thought
This technique involves training models to follow a structured reasoning process, similar to human thinking, step by step. By encouraging models to generate intermediate reasoning steps explicitly, researchers hope to improve the models' ability to tackle complex reasoning tasks and provide more accurate, logically consistent responses.
Using External Verifiers
To address the issue of models generating incorrect or misleading information, some researchers propose integrating external verification mechanisms. These verifiers can cross-check the model's output against trusted sources or use additional algorithms to validate the accuracy of the information before presenting it to the user. This helps ensure that the generated content is reliable and factually correct.
Using Solvers
Another approach involves incorporating specialized solvers that are designed to handle specific types of reasoning tasks. These solvers can be used to perform calculations, solve equations, or process logical statements, complementing the language model's capabilities. By delegating these tasks to solvers, the overall system can achieve more accurate and reliable results.
Conclusion
Despite impressive progress in areas like text generation and comprehension, current language models struggle with intricate, multi-layered reasoning tasks due to their inability to fully grasp the meaning, maintain consistent context, and rely solely on patterns extracted from large but potentially flawed training data. To address these limitations, future models will likely require more sophisticated architectures alongside ongoing research into common sense reasoning.
References
- Water pouring puzzle
- Learning to reason with LLMs
- GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
- PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change
- LLMs Still Can't Plan; Can LRMs? A Preliminary Evaluation of OpenAI's o1 on PlanBench
- LLMs Can't Plan, But Can Help Planning in LLM-Modulo Frameworks
Opinions expressed by DZone contributors are their own.
Comments