From Metrics to Action: Adding AI Recommendations to Your SaaS App
Learn how to add AI recommendations to your SaaS app, turning telemetry data into actionable insights for smarter DevOps decisions.
Join the DZone community and get the full member experience.
Join For FreeYou log into your DevOps portal, pinched to think about 300 different metrics: CPU, latency, errors, all lighting up red on your dashboard. But what to prioritize? It’s what an AI-based recommendation tool could resolve.
Every SaaS platform managing cloud operations records an incredible amount of telemetry data. Most products, however, simply provide visualization: interesting graphics, yet no actionable information. What if your product could provide automated suggestions for config, scaling, or alerts based on tenant behavior?
Using this article, you can incorporate AI recommendation functionality into your SaaS-based platform, thereby turning data into meaningful information. AI’s role in transforming DevOps dashboards into optimization engines shall also be discussed.
Why This Matters Now
It is now common for multi-cloud platforms to produce data points in the tens of millions each day. Engineers simply can't process these results. AI-powered assistance is no longer a "nice to have," it’s the next frontier in dashboard usability for new SaaS interfaces. Include context for actionable, customized suggestions to encourage faster decision-making, reduce unnecessary expenditures, and improve adoption.
Background
Most DevOps tools are built to monitor, not to advise. Dashboards and alerts tell you "what’s happening," not "what to do next!"
Some typical problems are:
- Decision fatigue: too many charts with no actionable conclusions.
- Compute waste: 40-60% of servers are below 40% utilization.
- Low feature adoption: less than 25% of alert templates are in use. Conventional rules-based automated approaches simply cannot be scaled for individual workloads or tenants. It follows naturally to move to a model based on learning from usage patterns.
Solution Overview
To resolve these kinds of earlier problems, something more than dashboards with static rules is needed. Intelligence with the capacity to learn from user activity, in addition to directing these engineers, would be necessary to inform their efforts, rather than having to interpret each of these many different graphics.
It starts with behavioral learning. Every engagement, whether it's opening a metric, muting an alert, or modifying an autoscaling rule, leaves traces, or signals, about what's useful, confusing, or volatile. To illustrate, if multiple groups of users are consistently modifying the volatile settings for an alert, it suggests modifications to point to a more stable environment.
On this foundation, collaborative intelligence finds similarities among tenants. Even for tenants whose data isn't shared, there's apt to be similarity in their workloads. If one set of tenants has successfully optimized CPU variability by turning on scheduled autoscaling, such variability is noticed by collaborative intelligence, which suggests an analogous solution for other tenants with similar workloads.
Generalization to new, unseen situations would be enabled by vector embeddings, which represent the properties of resources, such as instance types, alerting settings, or metric behaviors. A new instance type, for instance, could then be automatically matched with tenants likely to benefit from their workloads.
Every finding passes through a low-latency scoring layer, which instantly recommends actions in the SaaS interface. With each new telemetry, the engine suggests actions based on rankings, including offers like "Enable autoscaling: Similar groups with analogous workloads observed a 15% cost savings." Since inference times are below 100ms, these suggestions are perceived as native to the platform.
It improves with feedback. Successful predictions strengthen the model, while failed predictions decrease model confidence. It’s retrained nightly or hourly to keep its model fresh, eliminating costly real-time retraining. Trials with such a model have provided clouds with performance variability reductions of 22% with inference latency below 80ms.
With such embedded intelligence, your SaaS offering not only remains a monitoring solution but also becomes a proactive collaborator, which assists in taking faster actions, optimizing expenditures, and making more informed operational choices.
Architecture and Flow
Below is a visual representation of the complete AI recommendation system architecture utilized in these types of SaaS/DevOps applications. It highlights the flow of data from telemetry, behavioral, or workload metadata through the ingestion, model, and real-time scoring to provide actionable recommendations in product UI.
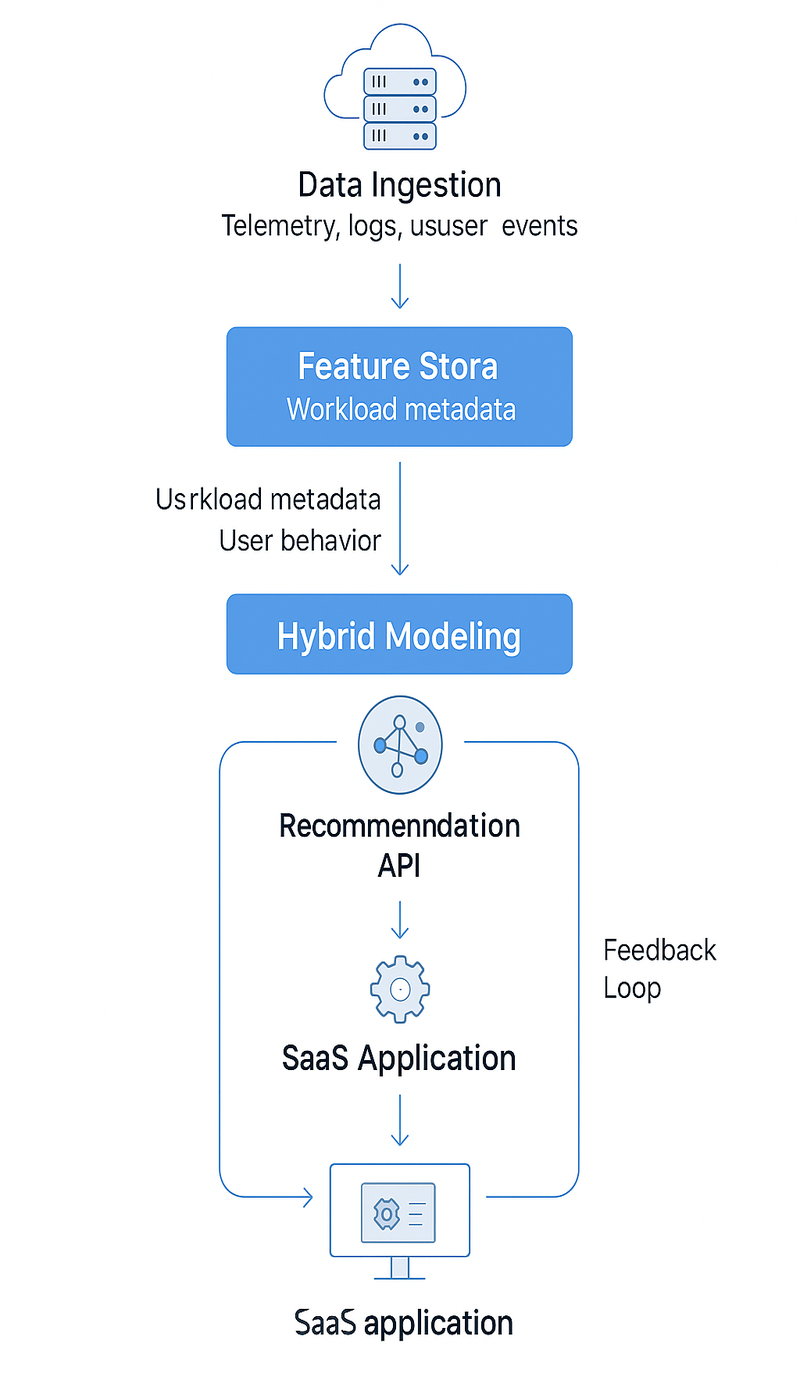
Before vs. After: Operational Intelligence Transformation
Before AI Recommendations
DevOps professionals spend inordinate amounts of their time trying to understand their dashboards, navigating between their metric views, or manually setting thresholds for alerts or scaling rules. Most choices are based on tribal knowledge or iterative testing. Inconsistent settings, sluggish response, or continuous over- or under-provisioning plague DevOps professionals' systems. Highly useful functions, such as anomaly detection or predictive scaling, go unused simply due to unfamiliarity with their appropriate use.
After AI Recommendations
It transforms from being a passive observer to an active decision-maker. Rather than looking at several hundred graphs, engineers get their most pressing answers in context with what they are working on. It shows them what they care about most, why, and what they should do next, which could be solved with one click. It’s dynamic because it changes based on what’s being received from the users, which improves with time.
Implementation Steps
A DevOps SaaS platform employed AI in offering cost-efficient settings based on cross-tenant activity.
1. Resource optimization begins with aggregating workload data with operational activity driven by users.
It is able to capture the patterns in machine activity, such as over-provisioned machines, noisy pages, misconfigured scaling rules, and inefficient workloads, while also taking into consideration human intention.
SQL: Aggregate multi-tenant resource signals
SELECT
tenant_id,
user_id,
resource_id,
AVG(cpu_util) AS avg_cpu,
AVG(mem_util) AS avg_mem,
PERCENTILE_CONT(0.95) WITHIN GROUP (ORDER BY cpu_util) AS p95_cpu,
COUNT(*) FILTER (WHERE action='resize') AS resize_events,
MAX(event_ts) AS last_seen
FROM telemetry_user_actions
GROUP BY tenant_id, user_id, resource_id;
Apply decay weighting to prioritize current workloads.
df['weight'] = df['resize_events'] * np.exp(-(now - df['last_seen']).dt.days / 7)Why this matters for optimization:
- Utilization patterns shift weekly
- Users adjust scaling rules when workloads misbehave
- Decay prevents old sizing decisions from influencing new recommendations
Compliance
Per-tenant matrices keep resource/workload behavior isolated for SOC2/HIPAA environments.
2. Build a hybrid behavioral/semantic model for optimization.
DevOps workloads vary widely — there are APIs, constant batch processing, and spiky ML inference work. Consequently, it needs to have an understanding of the nature of similar workloads, plus adjustments made to them by engineers.
Collaborative filtering learns human decisions.
model_cf = AlternatingLeastSquares(factors=64, regularization=0.1)
model_cf.fit(user_resource_matrix)Embeddings capture workload semantics.
resource_desc = workload["instance_type"] + " " + workload["traffic_pattern"]
item_embeddings = model_emb.encode(resource_desc)Blend into unified optimization score.
score = 0.65 * cf_score + 0.35 * cosine_similarity(item_embeddings)Why this hybrid approach works:
- CF mirrors real optimization patterns (“teams like you downsize this VM after consistently low CPU”).
- Embeddings capture resource characteristics, enabling recommendations for new instance families or unknown workloads.
- Hybrid ensures stability during high variance and low-data periods.
3. Deploy low-latency optimization API with SLOs and observability.
These optimization suggestions have to be made in real time, within dashboards where engineers are analyzing performance.
FastAPI Microservice (P99 < 120 ms target):
@app.get("/optimize/{tenant}/{resource}")
async def optimize(tenant, resource):
rec = hybrid_engine.recommend(tenant, resource)
return {
"resource": resource,
"suggested_actions": rec,
"explainability": rec.weights # CPU%, peer similarity, cost delta
}Add system observability. Use Prometheus counters:
- recsys_latency_ms
- recsys_success_total
- recsys_failure_total
- recsys_cache_hit_ratio
Example recommendations:
- “Resize c5.large → c5.medium (avg CPU: 22%, p95 CPU: 41%).”
- “Enable HPA (high variance workload detected).”
- “Adopt anomaly alerting (noise reduced 40% for similar apps).”
4. Feedback learning, drift detection, and retraining.
Resource optimization begins with recognizing what drives performance and cost improvements.
Log impact-aware feedback:
feedback.append({
"tenant": tenant,
"resource": resource,
"action": action,
"accepted": accepted,
"cpu_delta": post_cpu - pre_cpu,
"cost_delta": post_cost - pre_cost
})Drift detection (seasonality, traffic spikes, new deployments):
drift_detector = drift.ADWIN()
if drift_detector.update(current_avg_cpu):
trigger_early_retrain()Nightly retraining via Airflow:
with DAG("retrain_optimizer", schedule_interval="@daily") as dag:
PythonOperator(task_id="retrain", python_callable=retrain_pipeline)5. Validate the engine using optimization-centric metrics.
Consumer recommenders differ in that success is not measured by click-throughs in this case.
Offline
- Right-sizing prediction accuracy
- Improvement in CPU/memory balance
- Recall@5 for optimization suggestions
Online (A/B tests)
- % cost reduction per tenant
- Reduction in manual resize/edit operations
- Alert noise reduction
- Improved scaling stability (fewer OOMs, fewer restarts)
Key Takeaways and Future Directions
AI-driven optimization represents a paradigm shift for SaaS/DevOps platforms in general, since it translates raw infrastructure data into actionable insights to eliminate cloud inefficiencies and variability. By leveraging a hybrid approach to behavioral learning and workload semantics, the model is able to provide meaningful suggestions for rightsizing, scaling, and alarm tuning with significantly improved accuracy levels compared to traditional rule-based systems.
These features are most beneficial in multi-tenant scenarios, which are influenced by tenant isolation, compliance, and real-time inference needs in terms of constructing these suggestions. As the model learns from accepted and rejected suggestions, it gets more in line with operational needs for each tenant, thereby addressing their inefficiency levels, noise in alerts, and performance variability.
These foundations will also lay the groundwork for what next-generation optimization engines look like. Future engines will look not just at recommendations, but at safe, autonomous changes to make within given guardrails. Enhanced support for CI/CD pipelines will enable changes to be tracked against deployments or new service launches, while seasonal forecasts and time-series analysis will enable platforms to forecast demand peaks in advance. With increasing adoption in multiple clouds, engines will also enable analogous instance types on AWS, GCP, and Azure, to provide truly cloud-agnostic optimization for workloads. It all suggests a next chapter in which SaaS platforms evolve to be intelligent partners, with partners that enable self-improved, self-optimized, and faster decision-making for operationally confident teams.
Opinions expressed by DZone contributors are their own.
Comments