Salesforce Change Data Capture Streaming Data With Kafka and Snowflake Data Warehouse
In our tutorial, we are going to demonstrate how Salesforce Orders can be sent to the event bus and pushed them into a Snowflake table in near real-time.
Join the DZone community and get the full member experience.
Join For FreeIntroduction
Salesforce Change Data Capture feature supports near real-time data replication with an event-driven architecture based on Salesforce Event Bus. This event bus can be connected to Kafka as a data producer. On the other hand, Snowflake - working together with Confluent - has also made available its own Snowflake Connector for Kafka which makes it easy to configure a Kafka sink (i.e. a data consumer) and store JSON or Avro data inside Snowflake tables that can then be analyzed with Snowflake semi-structured SQL queries. These components together provide an ideal architecture for Salesforce streaming data processing in Snowflake.
Architecture
In our tutorial, we are going to demonstrate how Salesforce Orders can be sent to the event bus and pushed them into a Snowflake table in near real-time.
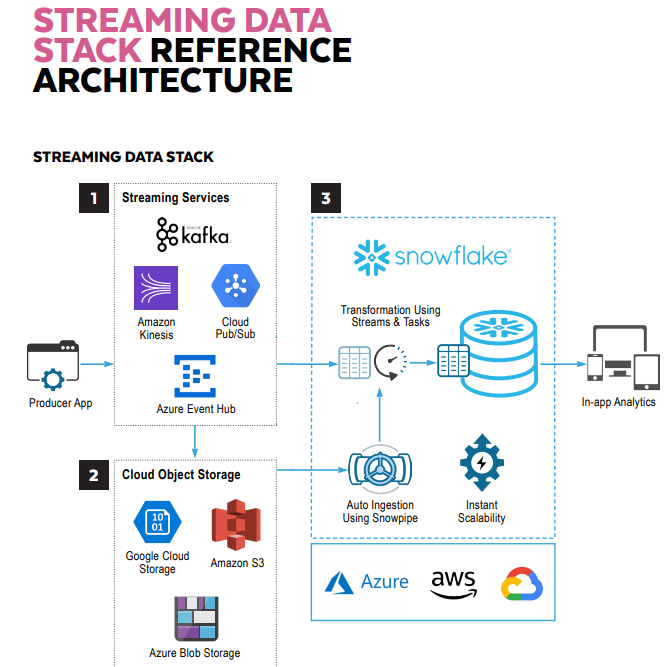
The streaming data stack looks as follows:
Configuration
In Salesforce we need to enable Change Data Capture for Orders. This is as simple as selecting the standard Order object under the Setup->Change Data Capture menu:
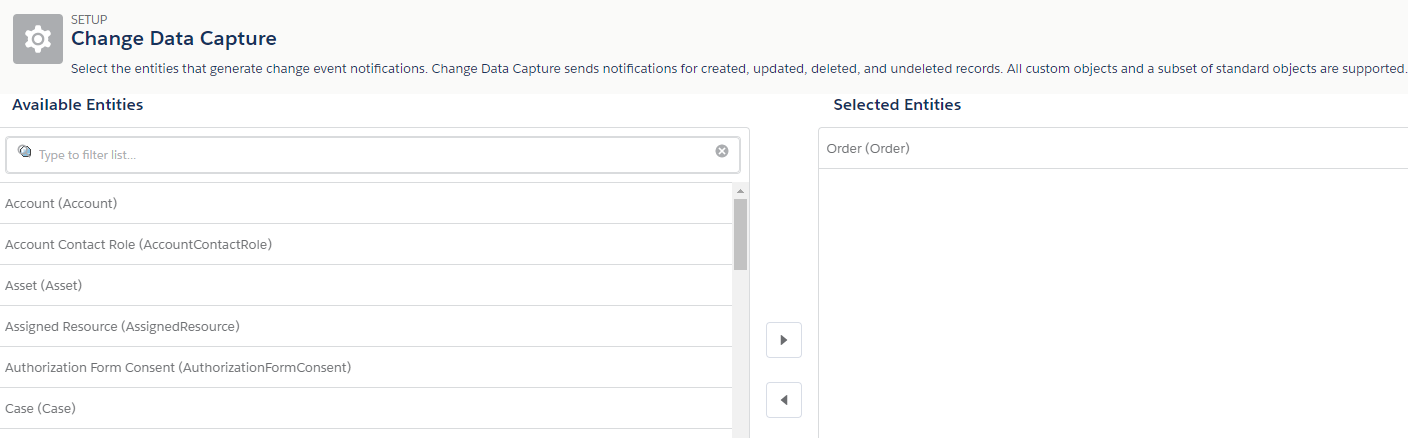
Once that is done, Salesforce will create an OrderChangeEvent object ad it is ready for publish chage data capture events.
Confluent platform support data integration for database changes for analytics, monitoring, etc.
To install Confluent Self-Managed Kafka, we need to go to https://www.confluent.io/download/
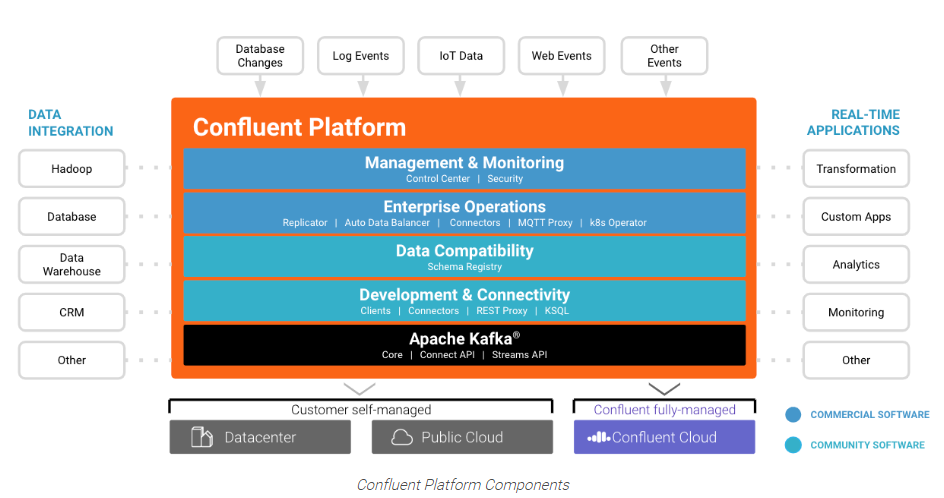
After downloading the platform, we need to set up the environment variables and the path and then we can start up the platform from command line:
export CONFLUENT_HOME=<path-to-confluent>
export PATH=$PATH:$CONFLUENT_HOME/bin
# Install the Kafka Connect Datagen source connector for demonstration purposes
$CONFLUENT_HOME/bin/confluent-hub install \
--no-prompt confluentinc/kafka-connect-datagen:latest
#This command starts all of the Confluent Platform components; including Kafka, ZooKeeper, Schema Registry, HTTP REST Proxy for Kafka, Kafka Connect, ksqlDB, and Control Center.
confluent local start
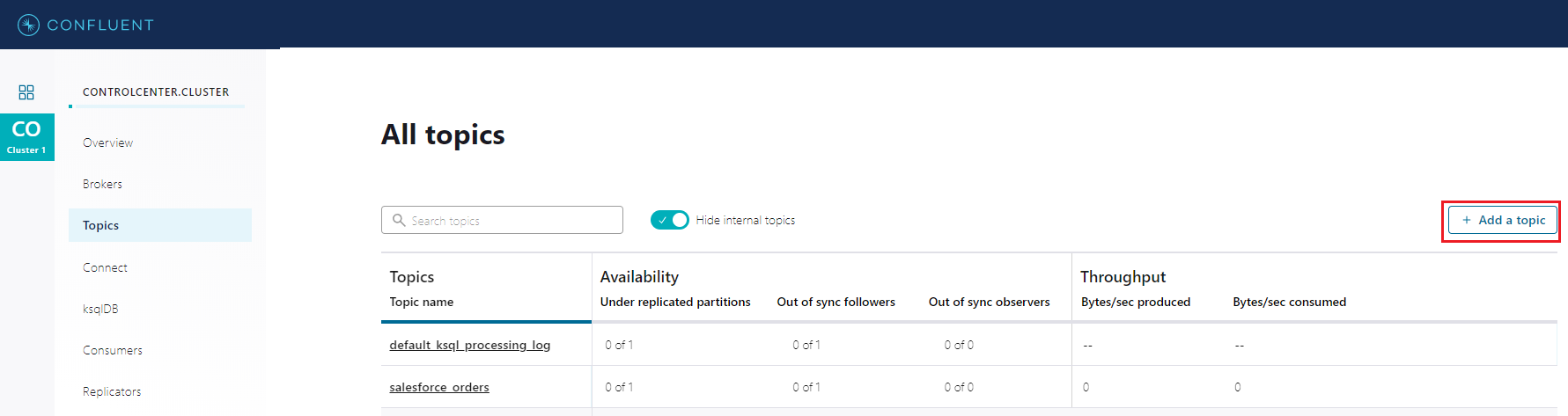
From the Control Center web interface we can create our Salesforce Orders topic, in our case it is called salesforce_orders:
Then we can create our connectors; first for Salesforce Change Data Capture and then for Snowflake:
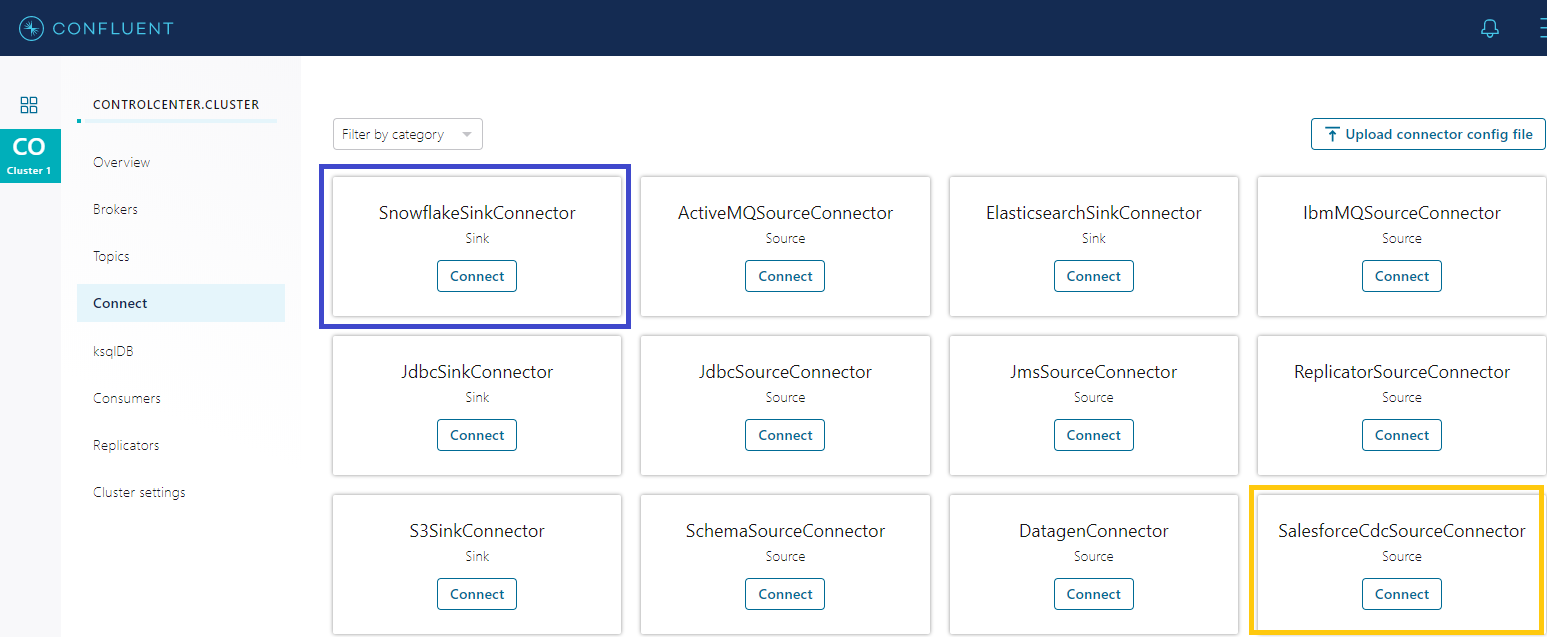
Salesforce Change Data Capture connecotr requires configuration parameters such as username, password, connected app consumer key and consumer secret. salesforce instance URL and the Kafka topic and Confluent Topic Servers:
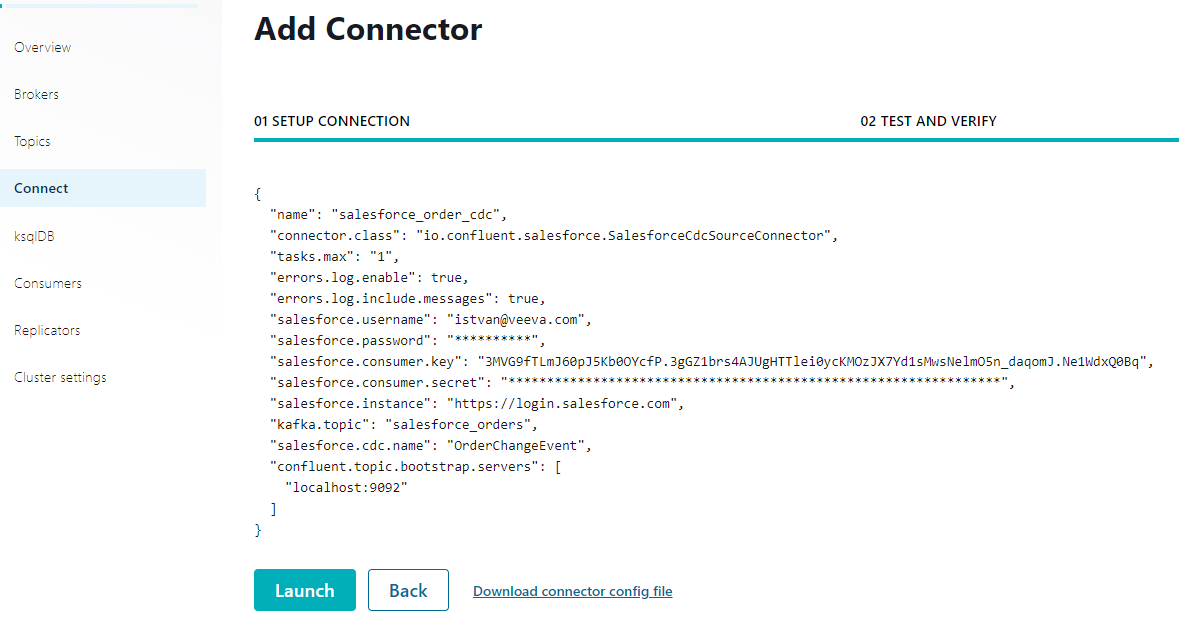
Snowflake connector configuration looks as follows:
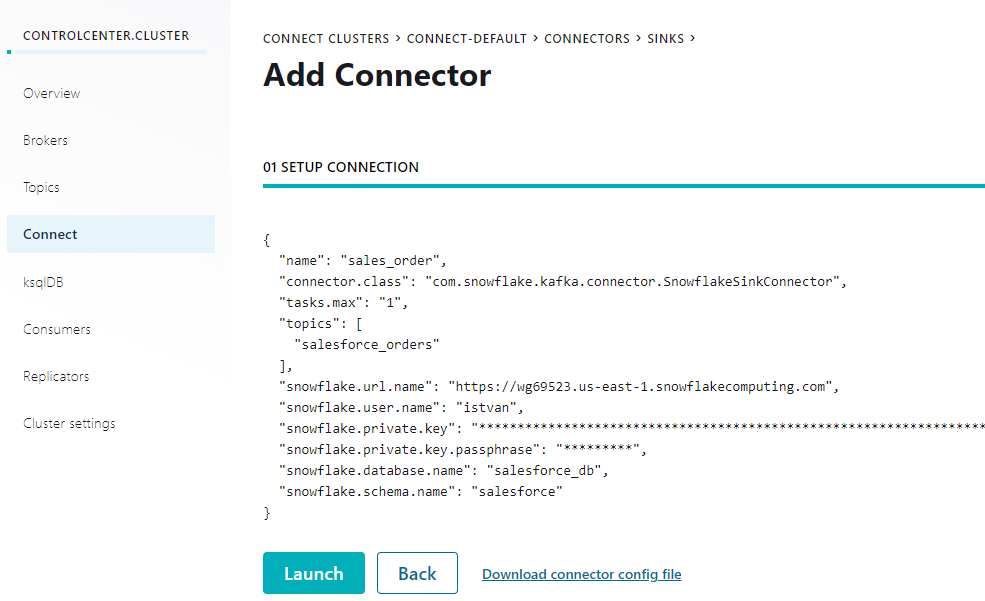
It uses key pair uthentication as described here so we need to generate private and public keys and set the database user's RSA_PUBLIC_KEY attribute accordingly.
Generating Salesforce Change Data Capture Event
To create an OrderChangeEvent, we just need to navigate to Salesforce Orders and create a new order with the appropriate account and contracts values populated. The initial status will be Draft.
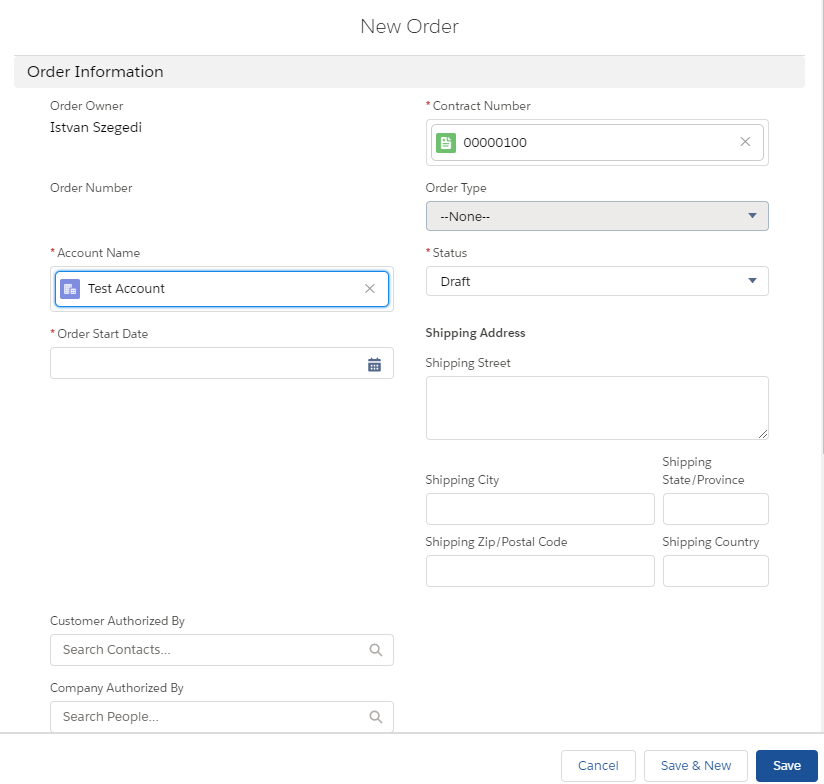
This will trigger a new CREATE Change Data Capture event.
The next step is to add Order Products:
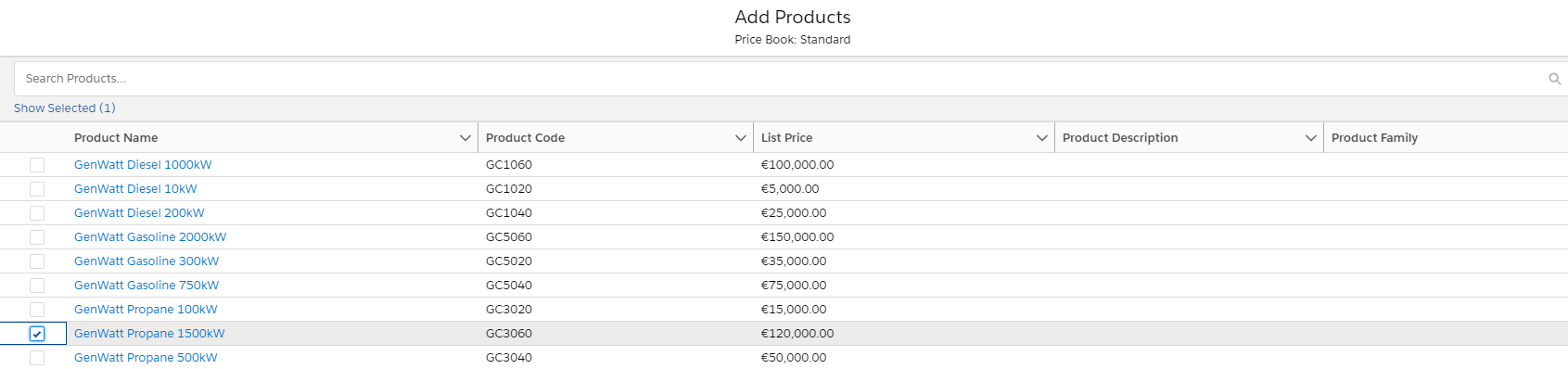
Once we selected the product and the quantity and saved the order products, a new Change Data Captire event will be created, an UPDATE event to set the TotalAmount value on teh order header.
Finally we can activate the order by selected the Activated value on the order status path Lightning component and click on Mark as Current Status button:
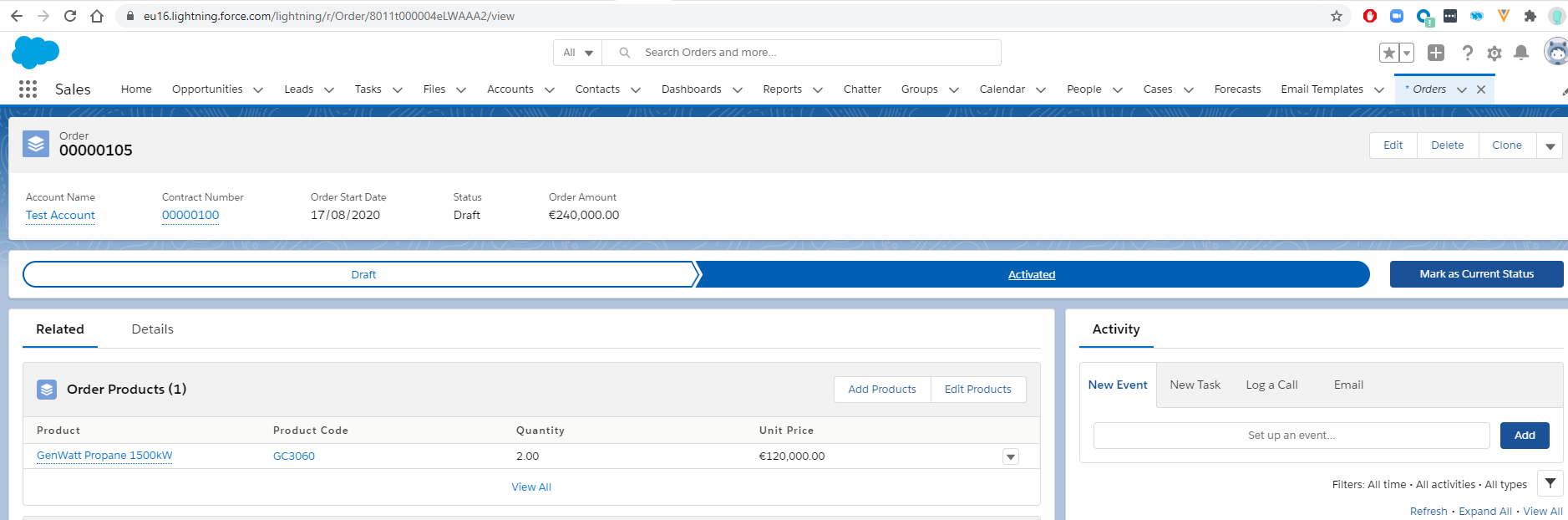
This will generate another UPDATE Change Data Capture event that is going to be published to Salesforce Event Bus. From there the Kafka connector will pick it up and generate a record on salesforce_orders topic
Querying the Change Data Capture Records in Snowflake
The Snowflake Kafka connector is designed to run inside a Kafka Connect cluster to read data from Kafka topics and write the data into Snowflake tables. From the perspective of Snowflake, a Kafka topic produces a stream of rows to be inserted into a Snowflake table. In general, each Kafka message contains one row.
Kafka topics can be mapped to existing Snowflake tables in the Kafka configuration. If the topics are not mapped, then the Kafka connector creates a new table for each topic using the topic name. (in our case salesforce_orders)
Every Snowflake table loaded by the Kafka connector has a schema consisting of two VARIANT columns:
RECORD_CONTENT. This contains the Kafka message.
RECORD_METADATA. This contains metadata about the message, for example, the topic from which the message was read.
In our scenario the new Snowflake table will be stored in SALESFORCE_DB database under SALESFORCEschema and and its name is SALESFORCE_ORDERS.
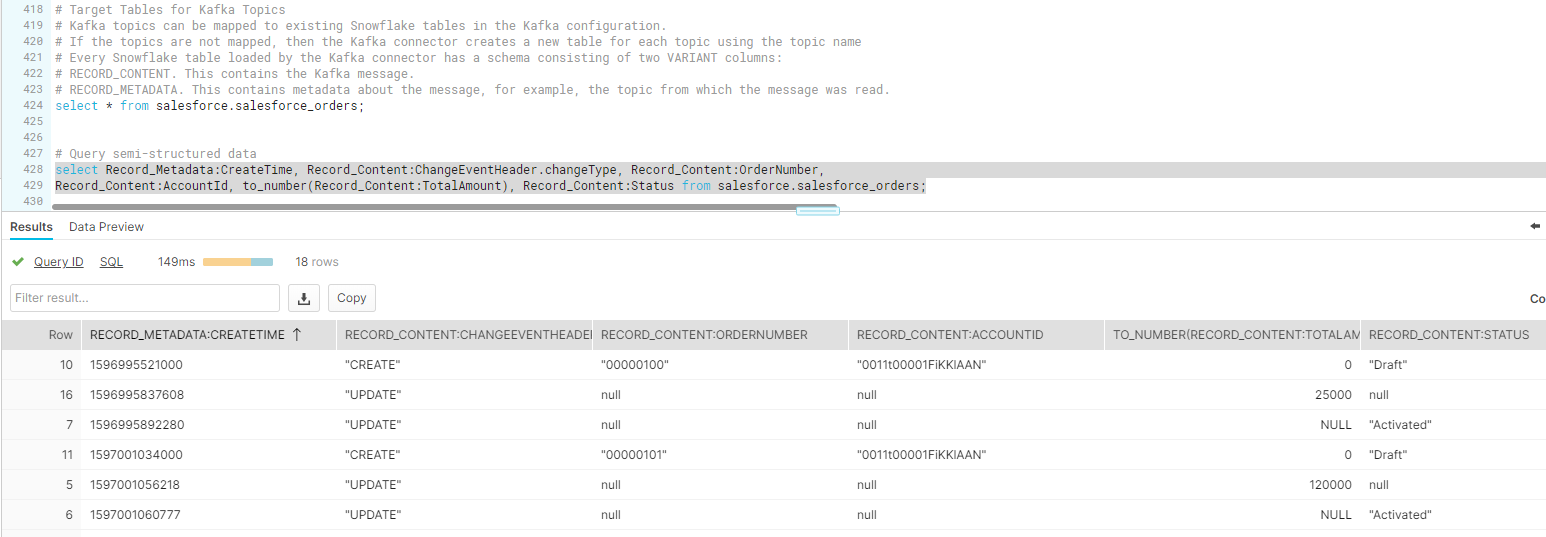
The data will be in JSON format so we will need to use SQL query format for semi-structured data format as shown below:
xxxxxxxxxx
select Record_Metadata:CreateTime, Record_Content:ChangeEventHeader.changeType, Record_Content:OrderNumber,
Record_Content:AccountId, to_number(Record_Content:TotalAmount), Record_Content:Status from salesforce.salesforce_orders;
In the Results section we will find the 3 change data capture events (CREATE, UPDATE with TotalAmount, UPDATE with Activated Status), as described above. In case of update operation Salesforce will only update the changed values and will also send teh LastModifiedTime value.
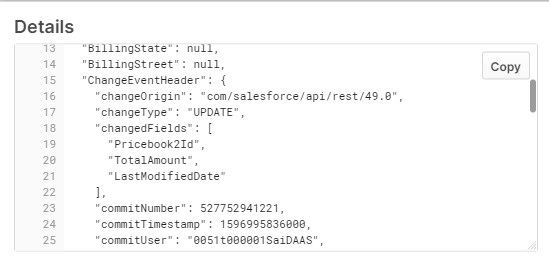
The original JSON data looks as follows (it is stored in RECORD_CONTENT field wich has VARIANT type):
Conclusion
In today's business world there are more and more needs to provide near-real time data for Customer 360 analytics utilizing various sources including CRM. Salesforce Change Data Capture event-driven mechanism together with Kafka and Snowflake provide a great architecture for these requirements. It is easy to setup and with the help of Confluent Kafka connectors there is no need to write any custom code, all can be achieved with simple web based configuration.
Snowflake Reference Architecture for Streaming Data
Opinions expressed by DZone contributors are their own.
Comments