Saving Memory In Java: Making The Smallest Memory Footprint
This article explains how to reduce memory usage in Java by demonstrating four ways to achieve the best footprint size and a way to calculate it.
Join the DZone community and get the full member experience.
Join For FreeArticles To Read Before We Start
I've already written articles about memory estimation. The first one explains how to calculate memory for objects, arrays, etc. The second one shows tools for how to estimate recursively any object size. Before you begin this article, I strongly recommend you read the first ones. Otherwise, it would be a bit difficult to understand how I calculate the size of objects.
This article will cover the next tricks and topics:
- Using primitive fields over wrappers (e.g., Boolean -> boolean)
- Reducing the number of classes making a flat structure (collapsing classes in one or less number of classes)
- Using narrow data types when it's possible (e.g.,
shortinstead ofint,longinstead ofDate, etc.) - Using masks to hide one type inside another (e.g., many booleans inside short)
Introducing Classes Structure To Be Reduced
Let's just cut to the chase and review the classes that we will use in our example. We will alter its structure and estimate its size step-by-step four times.
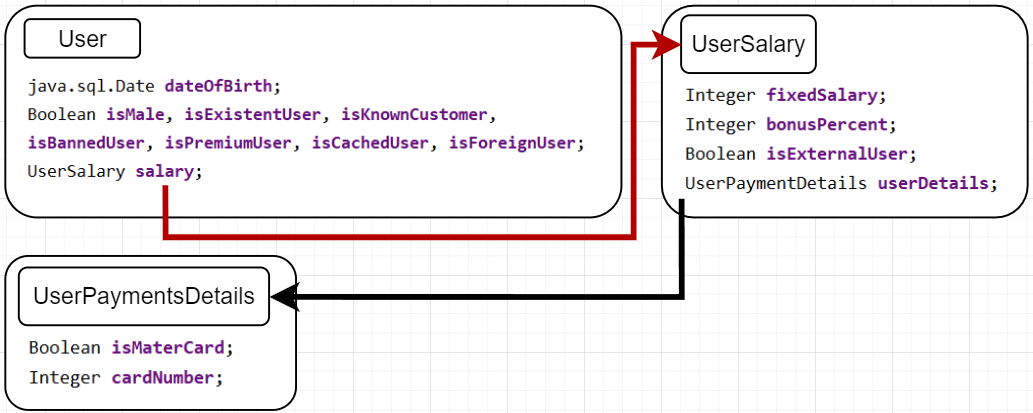
Calculating First Snapshot Size
As already mentioned above, I recommend reviewing the previous articles in order to understand the memory calculation process. In our case, we will use calculations based on 64-bit Java. We will verify all our calculations with the JOL-core library developed by Alexey Shipilev. You can find examples of this library in this manual.
Initiating User Object
First, let's create our 3 objects and set all fields. In our example, we will use all unique objects, and even for booleans, we will use new instances (by using new Boolean). In that case, our calculation will be most pessimistic (from size perspective) but perfectly correct:

Now let's calculate the size of each object (again considering that even all boolean instances are unique):
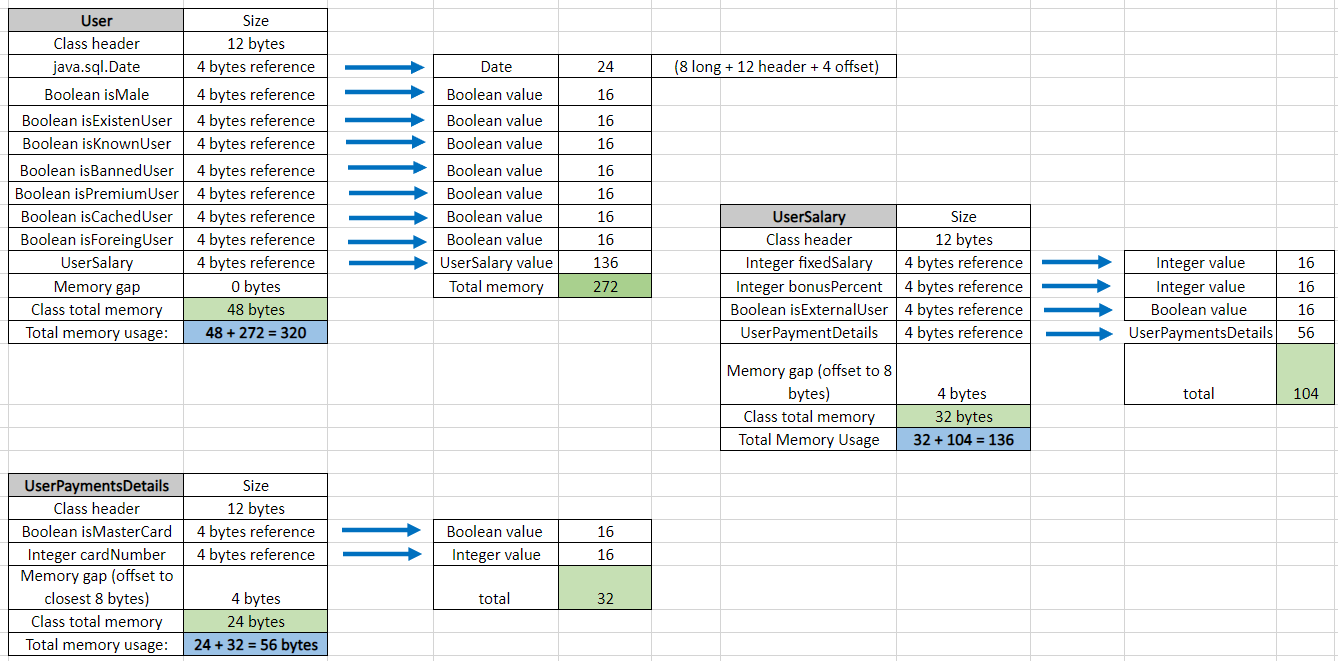
So after all, the total User size instance is 320 bytes (which includes UserSalary and UserPayment instances together). To verify it, let's use the JOL-core library and print their sizes:

The printed results are 56 bytes, 136 bytes, and 320 bytes.
Now let's improve this ridiculous example and initiate Boolean values properly.
In the previous example, I initiated Booleans as unique objects. Here, we will initiate in the way we reuse the same Boolean.true and Boolean.false references (and it's how you often initialize them). With such initialization, our example will be more realistic. (This step is not an optimization, it's just an additional step to explain how memory calculation works.)

Now we have to recalculate all objects because we basically changed Boolean initialization:
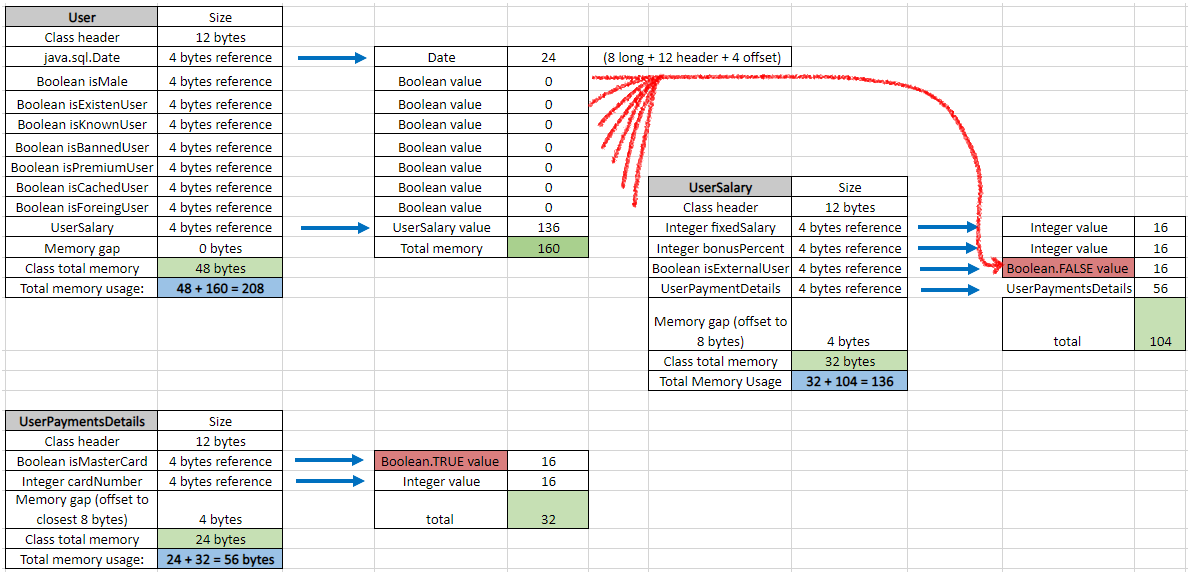
Print results are as expected: 56 bytes, 136 bytes, and 208 bytes (decrease from 320 bytes).
First Memory Optimization: Replacing All Wrappers by Primitives
Here, we make the first real optimization by using only primitives instead of wrappers objects. In such cases, we lose the null benefit option and all our values will be initialized by default.
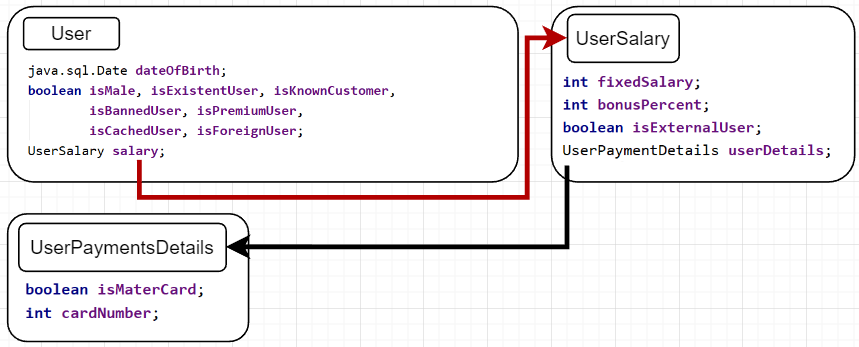
Now, let's recalculate the snapshot-size considering that all primitive values have no additional reference and stay inside their container object:
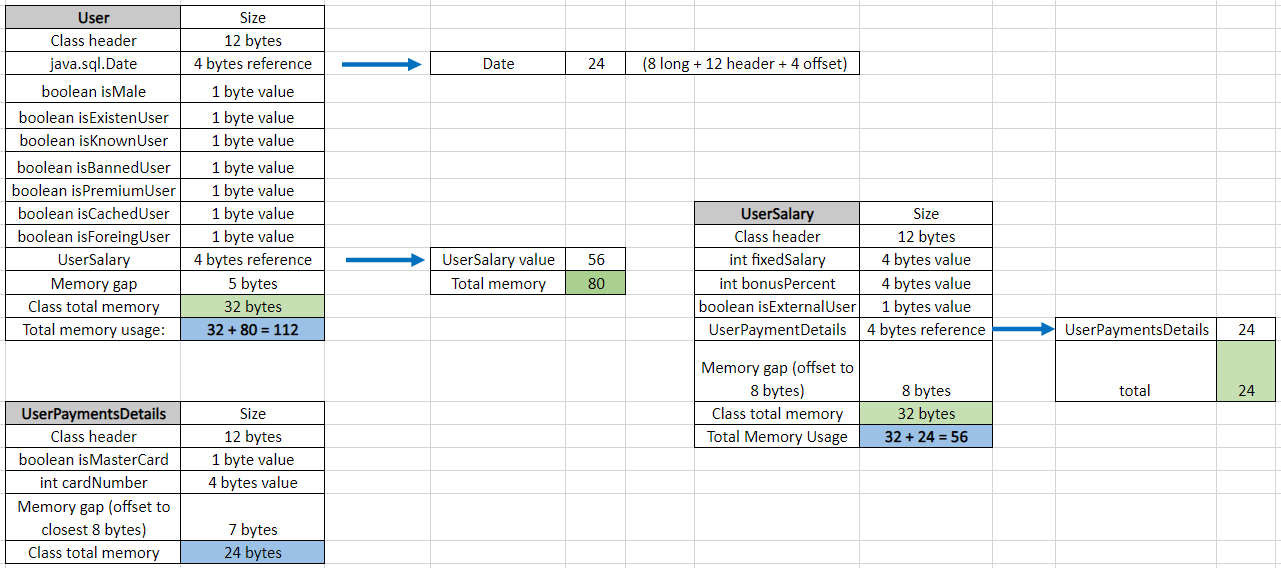
As you can see, all wrapper objects add 16 additional bytes. Such transformation decreases total size almost by 2 times from 208 to 112 bytes.
Second Memory Optimization: Collapsing Data in One Class
This optimization is not possible in the majority of situations, or at least makes OOP structure just less readable and maintainable; but in some urgent situations of memory shortage, you have no other options. So, let's move all fields on one class and see improvements:
Now having only one user object we also lost extra memory spent on references. Yes, the code is much more readable and maintainable, but we improved size almost by 2 times. JOL-Core library also confirms that the total size now is 64 bytes!
Third Memory Optimization: Using Narrow Types
If you check all types we use, you might mention that some of them cover bigger ranges than we need: e.g., salary is int value and covers from -2147483648 to -2,147,483,647, but according to our business requirement, it won't exceed 32,767 USD per month. Therefore, we can use Short data type instead of integer. In the same way, we can replace java.sql.Date and keep only long value (that are thousands of years in future and past already).
So in our case, we will make these next changes:

Now the total snapshot size is 40 bytes size. Can we improve it even more? Yes!
Fourth Memory Optimization: Using Narrow Types
At this step, we will "hide" smaller data types inside bigger types. The integer value is covered by 2^32 values. The boolean value is covered by 2^1. So inside one integer, we can "hide" 32 booleans. The same thing can be applied to these examples:
- 32 booleans (2^1) inside 1 integer (2^32)
- 4 bytes (2^7) inside 1 integer (2^32)
- 2 shorts (2^16) inside 1 integer (2^32)
- 2 integers (2^32) inside one long (2^64)
- Etc.
Writing Logic To Hide and To Reveal Masked Value for Booleans and Shorts
In our example, we will encapsulate all 9 booleans inside one short. We will use bitwise operations (shift to right, left, etc). You can find more examples in this article.
Transformation From Boolean To Short:
The transformation from boolean to short consists of the 3 next steps:
- Convert
booleanto1 (true)and0 (false). - Move that value to the left by
Nsteps using the left shift operator(<<). - Merge all values by using
OR (|)operator.
So, with defined flags order as below:

And implementation of all steps inside one method:

Now having this function, we can hide boolean values in one single short:

Revealing Hidden Boolean Values From Short Value
In order to identify what flag has what value, we need to make a backward transformation:
- Move
resultsvalue to right byNsteps (depending on flag order). - Make a comparison in order to "cut" the right number.
- Compare this number with
1, and if it's 1,=> flagsvalue is true.
All steps look like this:

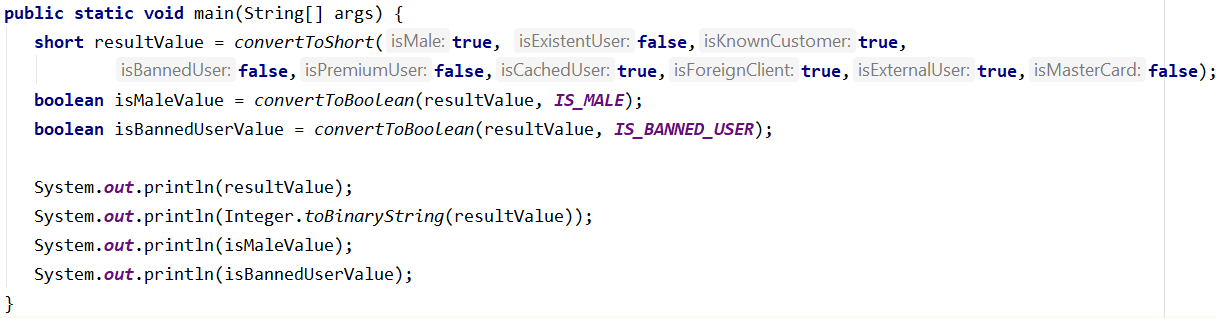
Now using all these functions we can try to hide the next values:

Our final value is 229, or can be represented in binary format as 011100101 and represent the next values as below:

Now having this result value, we can use mask and get a specific encapsulated boolean:
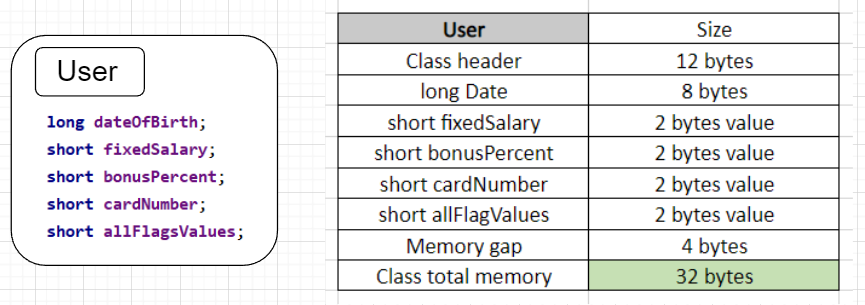
The final calculation is that the total size of our User class is 32 bytes.
Conclusions
After four transformations for our example, we got the next footprint improvements:
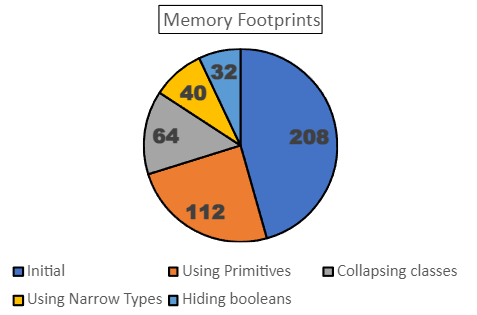
After all transformations, we reduced the size of the class from 208 bytes to 32, or almost 7 times. Our object is much more difficult to read and maintain, but memory consumption dropped dramatically. In the case of saving 10 million users, we would need only 320MB instead of 2.1GB. There are still some tricks on how to reduce memory usage, like string interning, but I hope the examples I show were useful. Here you can find all the used examples. Thanks for reading.
Opinions expressed by DZone contributors are their own.
Comments