Building Scalable Agentic Assistants: A Graph-Based Approach
This article explains how a graph-based, multi-agent architecture improves scalability, routing, and maintainability compared to monolithic agent designs.
Join the DZone community and get the full member experience.
Join For FreeAbout a year ago, we were drawn into what appeared to be a straightforward problem: building an interface assistant that could answer questions about payments, disputes, refunds, transactions, and a few other sub-domains and provide insights. The reality turned out far more complex.
Many teams already had multiple apis, data sources, internal tools, and domain experts collaborating. What we didn't have was a way to wire all this together into something that felt coherent, reliable, and scalable. Early experiments with single-agent chatbots worked for demos, but they collapsed under real organizational complexity. We needed to stop thinking in terms of agentic systems and start treating it as a coordinated system of agents, each with a narrow responsibility.
Three Hard Problems We Had to Solve
Our first attempts followed a familiar pattern. One large prompt, a growing list of tools, and a lot of conditional logic. As soon as we added more capabilities, everything became brittle.
We ran into three hard problems:
- Routing: How do you decide which expert logic should handle a given question?
- Context: How do you preserve conversational and organizational context without bloating every request?
- Scale: How do you add new capabilities without rewriting the system?
The breakthrough came when we stopped thinking about the assistant as a single brain and started treating it as a coordinated system where each node has a clear purpose.
An Agentic Architecture That Scales
At the heart of our solution is a graph-based orchestration model. Instead of one monolithic flow, we built a system where each node in the conversation is handled by a node with a clear purpose.
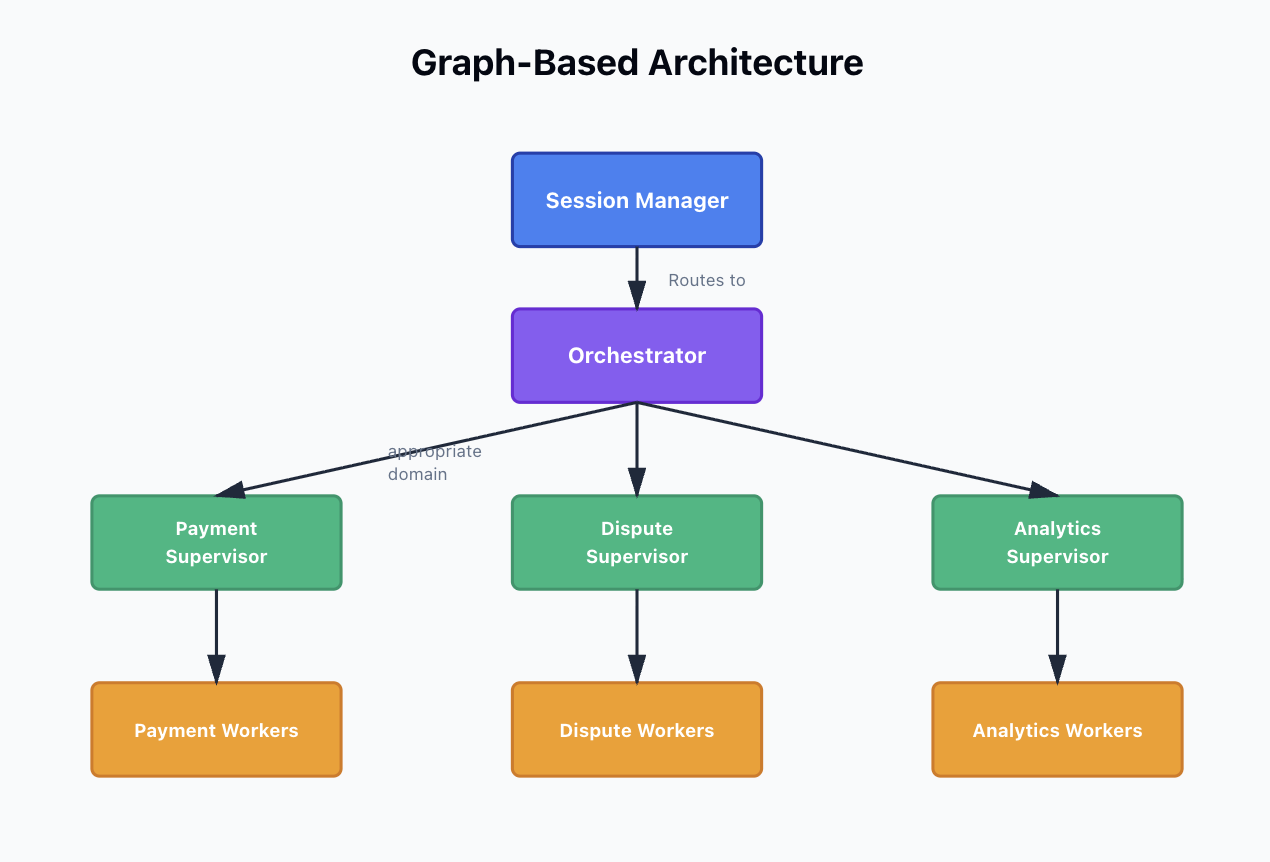
Session and Orchestration Layer
Every request starts with a session manager that handles state, history, and continuity. This feeds into a system orchestrator responsible for initializing agents and pushing state through the graph.
The orchestrator doesn't make business decisions. Its job is to move data, not interpret it. That separation turned out to be critical for maintainability.
# Orchestrator State Management
state = {
"user_id": "abc123",
"conversation_history": last_3_turns, # Not entire history
"current_domain": "payments",
"session_context": {
"merchant_id": "merch_789",
"date_range": "last_30_days"
}
}
async def orchestrate(query: str, state: dict):
# Initialize supervisor based on domain
supervisor = get_supervisor(state["current_domain"])
# Pass minimal context, not everything
result = await supervisor.route_and_execute(
query=query,
context=state["session_context"]
)
# Update state for next turn
state["conversation_history"].append(result)
return resultSupervisor and Routing
Each domain in our system (payments, disputes, analytics) gets its own supervisor node. These supervisors don't process requests directly — they route to specialized worker agents based on the user's intent.
Think of routing like a well-designed API gateway. The supervisor examines the incoming request, decides which worker is best equipped to handle it, and hands off execution.
Workers and Tools
Worker agents are where the actual work happens. Each worker has access to a narrow set of tools and focuses on a specific domain. One might handle payment lookups, another processes dispute filings, and a third runs analytics queries.
Because workers are narrowly scoped, they're easier to test, easier to reason about, and easier to extend. Adding a new capability means adding a new worker node, not refactoring the entire system.
class PaymentWorker:
"""Handles payment-related queries only"""
def __init__(self, tools: List[Tool]):
self.tools = {
"lookup": PaymentLookupTool(),
"stats": PaymentStatsTool(),
"export": PaymentExportTool()
}
async def process(self, query: str, context: Context):
# Single responsibility: payment lookups only
tool_name = self._select_tool(query)
tool = self.tools[tool_name]
# Execute with merchant-specific context
result = await tool.execute(
query=query,
merchant_id=context.merchant_id,
filters=self._extract_filters(query)
)
return self._format_response(result)
def _select_tool(self, query: str) -> str:
"""Simple keyword matching for tool selection"""
if "export" in query.lower():
return "export"
elif any(word in query.lower() for word in ["total", "sum", "count"]):
return "stats"
else:
return "lookup"
Why This Architecture Works
When we moved to this model, several things improved immediately:
- Maintainability: Each component has a single responsibility. If something breaks, we know exactly where to look.
- Scalability: New features don't require rewriting core logic. We add nodes, not complexity.
- Testability: We can test each worker independently before integrating it into the larger graph.
- Context management: Because state flows through a deliberate graph structure, we avoid the "everything everywhere all at once" problem that plagued our first attempts.
Before: Monolithic Approach
# Everything in one massive prompt + conditional logic
async def handle_query(query: str):
if "payment" in query and "failed" in query:
if "last month" in query:
result = await query_payments(status="failed", days=30)
elif "today" in query:
result = await query_payments(status="failed", days=1)
else:
result = await query_payments(status="failed")
elif "dispute" in query:
if "open" in query:
result = await query_disputes(status="open")
elif "closed" in query:
result = await query_disputes(status="closed")
# ... 50 more conditions
elif "analytics" in query:
# ... another 30 conditions
# Fragile and impossible to maintain
return format_result(result)After: Graph-Based Approach
# Clean separation of concerns
async def handle_query(query: str, state: dict):
# Orchestrator determines domain
supervisor = orchestrator.route_to_supervisor(query, state)
# Supervisor picks the right worker
worker = supervisor.select_worker(query)
# Worker executes using appropriate tool
result = await worker.process(query, state["context"])
return result
# Adding new capability? Just add a new worker node
This isn't about throwing AI at a problem and hoping it works. It's about building systems that respect the complexity of real organizations while staying maintainable as they grow.
The graph-based approach gives us something we didn't have before: a way to coordinate multiple specialized agents without creating a tangled mess of conditionals and overloaded prompts.
Opinions expressed by DZone contributors are their own.
Comments