Scalable Distributed Architectures in E-Commerce: Proven Case Studies
Learn how AWS, GCP, and Kubernetes designs achieve resilience, low latency, and massive scalability with real-world blueprints.
Join the DZone community and get the full member experience.
Join For FreeModern e-commerce platforms must handle massive scale – from flash sales driving sudden traffic spikes to global user bases demanding low-latency experiences. Achieving this reliability and performance at scale requires robust distributed architectures. In this article, I’ll share three case studies of scalable e-commerce architectures that I’ve analyzed and worked with, each leveraging a different tech stack:
- Serverless microservices on AWS – how Amazon’s cloud (Lambda, SQS, DynamoDB, etc.) solved real-world scaling problems for an online retailer.
- Containerized services on Google Cloud – using GCP’s serverless containers (Cloud Run, Firestore, Pub/Sub, BigQuery) for high traffic and maintainability in a retail scenario.
- Open-source cloud-native stack – a Kubernetes, Kafka, Redis, PostgreSQL architecture that scaled a large online retail platform with open source tooling.
Each example will include an architecture diagram, key components (with a table where helpful), the challenges faced, and how the design addressed them – along with deployment and operations insights. As an engineering lead, I’ll also highlight practical takeaways from these architectures. Let’s dive in.
Case Study 1: Serverless Microservices on AWS (MatHem’s Journey)
MatHem, Sweden’s largest online-only grocery retailer, reached a breaking point with their monolithic e-commerce application in 2016. The on-premise monolith couldn’t keep up with growth – scaling was clunky and deployments were painfully slow, often taking weeks to test and roll out new features . The company needed to handle increasing traffic and innovate faster to stay competitive.
Challenge: The monolithic system caused development bottlenecks and couldn’t scale for peak demand. Any code change affected the entire system, and provisioning new test environments took weeks . MatHem’s small IT team also spent too much time on infrastructure upkeep instead of delivering features
Solution Architecture: In 2017, MatHem made a bold move to a serverless microservices architecture on AWS. They refactored their application into hundreds of microservices running as AWS Lambda functions, with Amazon API Gateway routing requests to these functions . Data was migrated to cloud-native stores: dozens of Amazon DynamoDB tables for high-traffic, schema-flexible data (product catalogs, sessions, etc.) and Amazon Aurora Serverless for transactional data needing SQL. Crucially, they adopted an event-driven design – business events (like order placements, inventory updates) flow through Amazon SNS topics and SQS queues, triggering Lambda-based workflows asynchronously. This decouples services and smooths out traffic bursts, as each Lambda will scale automatically in response to queue backlogs.
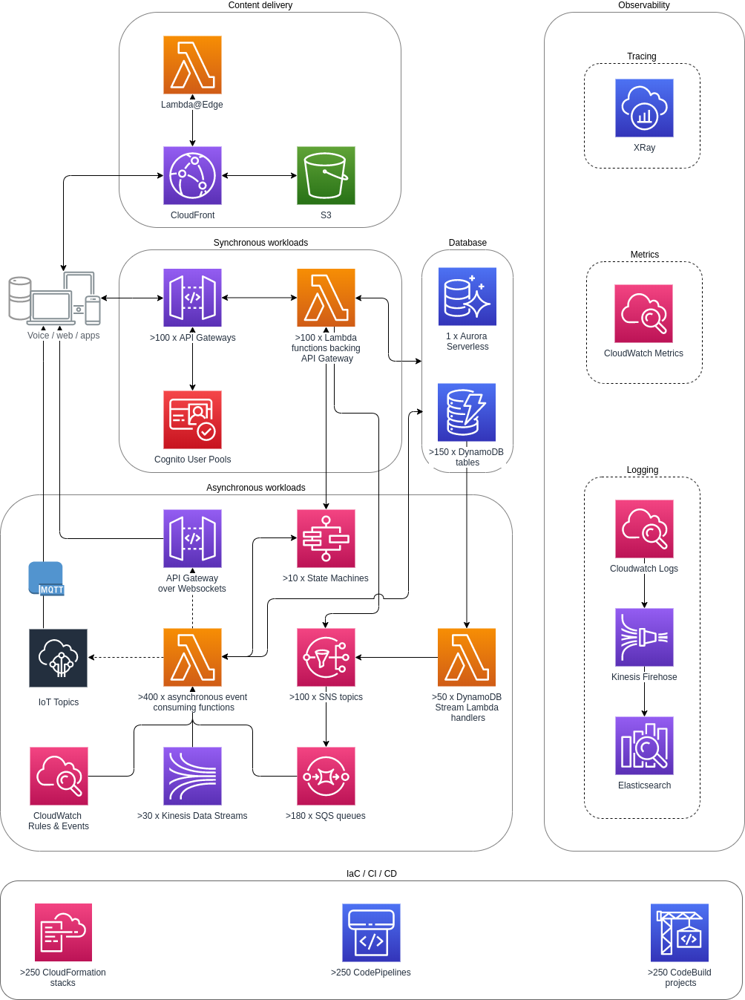
Figure 1: Architecture of MatHem’s serverless e-commerce platform on AWS. Client-facing apps invoke API Gateway endpoints (not shown for simplicity) which trigger Lambda functions (orange) implementing various services (e.g. product catalog, orders, user profile). These functions interact with a database layer (blue) comprising Amazon Aurora Serverless (for relational data) and ~150 DynamoDB tables (for high-scale NoSQL storage). Synchronous requests are handled through REST APIs backed by over 100 Lambda functions behind API Gateway . Asynchronous workflows use a combination of AWS services: e.g. IoT or app events -> Amazon SNS topics -> SQS queues (pink) -> Lambda consumers, and orchestration via Step Functions (state machines). This event-driven approach ensures non-blocking processing of tasks like order fulfillment and notifications. Content is delivered efficiently via Amazon S3 and CloudFront, with Lambda@Edge for dynamic edge logic. Observability is built in with X-Ray (distributed tracing) and CloudWatch (metrics/logs) for monitoring.
In this serverless design, each microservice is an independent Lambda, so they can be developed, deployed, and scaled individually. For example, one Lambda handles user checkout logic, another processes payments, another updates inventory. This isolation meant developers no longer “step on each other’s toes” – MatHem found that by decoupling services, they could deliver new features 5–10× faster than before . The DynamoDB-backed services easily scaled to meet peak traffic with zero manual intervention, since DynamoDB is fully managed and auto-scales throughput. In MatHem’s case, DynamoDB even serves as a flexible schema store for product data and a persistent shopping cart session store, letting them add new product categories without painful migrations . Meanwhile, Amazon SQS queues handle surges in orders: if a sudden spike of checkouts occurs, orders queue up and Lambdas scale out to process them in parallel, preventing any single service from becoming a bottleneck.
Key AWS Components and Roles: To clarify how AWS services fit together, here’s a breakdown of the core components in this architecture:
- AWS Lambda: Serverless compute for all backend logic. Each Lambda function handles a specific domain (orders, payments, etc.) and can scale from zero to thousands of concurrent executions in response to load, without pre-provisioning servers. This on-demand scaling was critical for handling flash sales and unpredictable spikes. MatHem’s deployment uses over 100 Lambda functions backing their APIs , plus many more for async processing (e.g. ~50 Lambdas consuming DynamoDB streams for change events).
- Amazon API Gateway: Fronts the Lambda microservices with RESTful endpoints. It provides a unified API for the frontend (web or mobile), handles routing to the correct Lambda, implements throttling and caching, and offloads authentication concerns. This managed gateway means the team didn’t have to run their own API servers, and it scales as calls increase (important on big shopping days).
- Amazon DynamoDB: A fully managed NoSQL database used for scalable, low-latency data storage. MatHem uses DynamoDB for things like product catalogs and user sessions/shopping carts . Dynamo’s schemaless design allows rapidly adding new product attributes or categories as the business evolves . It can handle extremely high request rates with minimal latency, which was essential for read-heavy workloads (e.g. displaying product pages or checking inventory in real-time).
- Amazon Aurora Serverless: A serverless relational database (compatible with PostgreSQL/MySQL) used where strong consistency and SQL capabilities are needed (e.g. for order transactions or user data joining across tables). Aurora Serverless automatically adjusts capacity, so the team doesn’t worry about provisioning or scaling the DB for peak vs. off-peak – it scales based on load. In the MatHem architecture, a single Aurora cluster supplements DynamoDB for those use-cases requiring complex queries or transactions that DynamoDB isn’t suited.
- Amazon SQS and SNS: AWS’s messaging backbone for decoupling services. SNS (Simple Notification Service) is used as a pub/sub system to broadcast events – for instance, when an order is placed, an SNS topic can fan out notifications to inventory service, email service, analytics service, etc. SQS (Simple Queue Service) provides durable queues to buffer workload. MatHem’s system includes ~180 SQS queues enabling components like billing or warehouse updates to process tasks at their own pace. This ensures that sudden surges (say 1000 orders in a minute) don’t overwhelm downstream services; they’ll just accumulate in the queue and be processed as fast as Lambdas can scale. Together, SNS and SQS make the system resilient and elastic – they absorb traffic bursts and failures (messages persist until processed), improving reliability.
- Amazon CloudFront and Lambda@Edge: CloudFront (CDN) caches static content (images, CSS/JS, product pages cached as HTML) at edge locations worldwide, reducing latency for users and offloading traffic from origin servers . MatHem also uses Lambda@Edge (small Lambda functions that run at CloudFront edge nodes) to handle things like personalization or geolocation logic right at the CDN, improving performance. This content delivery layer is crucial in e-commerce where page load speed directly impacts conversion rates. As AWS notes, serving requests from the closest edge location helps sustain peak traffic without stressing the core infrastructure .
- Observability (Amazon CloudWatch & AWS X-Ray): With a highly distributed system (dozens of Lambdas interacting via events), MatHem invested in monitoring and tracing. CloudWatch provides centralized logs and custom metrics (e.g. monitoring DynamoDB throughput or Lambda errors), and X-Ray traces end-to-end request flows through the microservices. This observability stack gives the team insight into performance bottlenecks and failure points in a complex workflow. For example, they can trace a user’s checkout request as it traverses API Gateway -> Lambda -> DynamoDB -> SNS -> another Lambda, and identify any slow segments. Such tooling is essential for operating a microservices architecture in production.
Outcomes: The AWS serverless approach paid off dramatically for MatHem. They reported that after migrating to microservices on Lambda and DynamoDB, developers could innovate “5 to 10 times faster” than with the old monolith . Each service has a smaller codebase and can be deployed independently, so development became more agile. The tech team shifted to be “100% dedicated to development, rather than infrastructure management” – in other words, AWS’s managed services took over the undifferentiated heavy lifting of scaling, backups, servers, etc., allowing engineers to focus on product features. This architecture easily handled growth in traffic; because it’s event-driven and serverless, scalability is largely automatic. During peak shopping periods (like holiday sales), Lambda concurrency and DynamoDB throughput scale up transparently to meet demand, then scale down to reduce costs during lulls. MatHem’s journey shows that a well-architected serverless system can achieve both high scalability and developer velocity. From an ops perspective, they also invested in Infrastructure as Code and CI/CD – the team created over 250 CloudFormation stacks and pipelines to manage the deployment of all these Lambda services and supporting resources. With everything scripted and automated, deployments became routine and safe, even as they were doing dozens per day.
Lessons Learned: In my experience, designing an e-commerce backend this way requires careful service decomposition (defining clear bounded contexts for each Lambda/service) and attention to data access patterns (e.g. using DynamoDB effectively with proper keys to avoid hot partitions). It’s also important to implement idempotency and exactly-once processing in the event-driven flows (for example, ensuring a Lambda reading from an SQS queue can safely retry without double-charging an order). MatHem leveraged AWS’s best practices – they even worked with AWS experts to tune their serverless configs – which highlights that using managed services doesn’t eliminate the need for good architecture discipline. That said, the “serverless-first” strategy tremendously reduced operational overhead. This case demonstrates that AWS’s stack (Lambda + API Gateway, DynamoDB, etc.) can successfully power a large-scale e-commerce platform with minimal ops burden, offering virtually limitless scaling and high resilience out of the box.
Case Study 2: Containerized E-Commerce on Google Cloud (Kauche)
Not every system can go fully serverless function-as-a-service. Some need the flexibility of running containerized services while still outsourcing infrastructure management. Google Cloud Platform (GCP) provides a suite of serverless and managed services that a savvy team can harness for scalability. Kauche, a fast-growing social e-commerce startup from Japan, is a great example – they built a scalable architecture on GCP that handles sudden viral traffic with ease, all while keeping operations simple.
Kauche’s platform lets users team up with friends to get group discounts on purchases . As a startup launching in 2020, they faced typical challenges: limited engineering resources but the need to rapidly build a product that could scale to millions of users. They anticipated spikes in traffic, especially when marketing campaigns or TV ads ran, which could send floods of users to the app in a short time . Their requirements were to handle these surges without downtime, iterate quickly on features, and avoid heavy ops work (since a small team had to manage everything).
Solution Architecture: Kauche embraced a microservices architecture on GCP using Cloud Run, a fully managed container runtime. They decided early on to containerize all services (each microservice packaged as a Docker container) and deploy them to Google Cloud Run . Cloud Run gave them the best of both worlds: they could write each service in their language of choice and have fine-grained control over the runtime (unlike a function which is more constrained), but Google handles all the provisioning, scaling, and management of the underlying compute. As architect Yuki Ito explained, “Cloud Run was attractive because it runs containers on a fully managed platform… easier to manage as it’s serverless.” . They avoided managing Kubernetes directly by using Cloud Run, yet kept open the possibility to migrate to Kubernetes in the future (since anything running in Cloud Run could later run on GKE if needed) .
The Kauche backend consists of multiple containerized microservices (written in Go) running on Cloud Run, communicating via gRPC and HTTP APIs. A Cloud Load Balancer and API Gateway (Envoy proxy) front these services, routing requests from the mobile app to the appropriate service. For data storage, Kauche uses a combination of Google Cloud Firestore (a serverless NoSQL document database) and Cloud Spanner (a horizontally scalable relational database) . Firestore is used for most application data due to its simplicity and ability to sync in real-time to clients, while Spanner is used for certain high-volume relational data that needs strong consistency and unlimited scale (Spanner is Google’s globally-distributed SQL database). They also use Google Pub/Sub as an asynchronous messaging system – for example, to handle events like “group purchase completed” or to queue up tasks like sending push notifications . Additionally, they leverage Cloud Tasks for background jobs and Cloud Scheduler for any cron-like scheduled tasks (such as daily deals or nightly data imports)
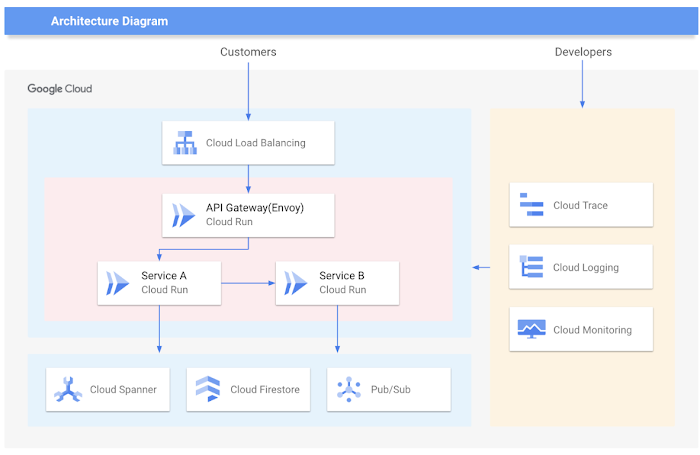
Figure 2: High-level architecture of Kauche’s e-commerce backend on Google Cloud. Client requests from the mobile app first hit Cloud Load Balancing, then go through an API Gateway (an Envoy proxy running on Cloud Run) that routes to the appropriate service. The microservices (e.g., Service A and Service B in this diagram) run on Cloud Run in a fully managed container environment, scaling up and down automatically based on request load. Services communicate with each other (as indicated by the arrow from Service A to Service B) via API calls or gRPC. The state is stored in Google-managed data stores: here Cloud Spanner (for relational data) and Cloud Firestore (for document-centric data) provide a scalable, managed database layer. Cloud Pub/Sub acts as the event bus for asynchronous processing – services publish events to topics and other services can subscribe, enabling decoupled workflows (e.g., order events triggering inventory updates). On the right, the developer/operations tooling is shown: GCP’s Cloud Logging, Cloud Monitoring, and Cloud Trace services give the team insight into application performance and help with debugging in production. This architecture allowed Kauche to focus on building features while GCP handled the heavy lifting of scaling and reliability.
Scalability and Performance: This GCP setup was tested early on when Kauche ran TV advertising – suddenly a huge spike of users would hit their system. Because everything is managed, the platform scaled smoothly: Cloud Run automatically added more instances of the containerized services as traffic grew, and Firestore/Spanner can scale (Spanner nodes can be increased in anticipation of big spikes) to handle the load . In fact, the team noted that if they expect a traffic spike (say, due to a feature on national TV), they can simply set the number of Spanner nodes higher ahead of time to ensure virtually unlimited scaling, and the serverless platform takes care of the rest . Kauche’s app reached 1.5 million downloads and a large active user base, yet their backend handled it without major rewrites . The key was designing stateless services and offloading state to GCP databases and Pub/Sub. Each Cloud Run service can scale to many concurrent instances (scaling per request), and by using Pub/Sub they ensured that expensive processes (like aggregating group buy data or sending out bulk notifications) could be done asynchronously, smoothing out load. For example, when a shared purchase is completed, a Pub/Sub event triggers processing of rewards for multiple users; if 10,000 purchases complete at once, Pub/Sub will buffer those events and Cloud Run subscribers will scale out to handle them in parallel, preventing any single service from choking .
Maintainability: A strong advantage of this architecture is how little operational effort is required. The Kauche team was extremely small – at one point just 2 platform engineers and 1 site reliability engineer operating the whole system ! And yet, they could run a production service with millions of users. “The biggest advantage of Google Cloud is that it’s hands-off… almost zero compute resources to manage,” said their architect . Indeed, they didn’t manage any VMs or clusters directly; everything (compute, databases, messaging) is either serverless or fully managed. This freed the team to focus on product development. They managed infrastructure using declarative configuration (infrastructure as code with deployment manager or similar) and set up monitoring with GCP’s Operations Suite (Cloud Monitoring, Logging, Trace) . Out-of-the-box, GCP provides detailed metrics for Cloud Run (concurrency, CPU/memory), Firestore performance, Pub/Sub queue depths, etc., which they used to keep an eye on the system health. For deployments, Cloud Build and Cloud Deploy were likely used to build container images and continuously deploy them to Cloud Run (though not explicitly stated, GCP offers those services and the team emphasized full use of Google Cloud’s toolchain ). Thanks to this setup, Kauche could deploy new features daily and even multiple times per day. In an interview, the CTO of Paack (another retail tech firm on GCP) similarly noted, “Our time to market is short—we deploy software every day… release 5-6 features every week. It’s unmatched in [our] sector” . This is a common theme: using managed services leads to faster, more frequent deployments because the ops overhead is so low.
Security & Reliability: The Kauche architecture also benefited from GCP’s global network and security. Cloud Load Balancing allowed them to serve users from multiple regions and fail over if needed. Firestore and Spanner are highly available by design (Spanner offers 99.999% availability with multi-region data). By avoiding a single monolithic database and instead using Google’s distributed databases, they reduced the risk of outages from overload. Interestingly, the team consciously avoided traditional servers and self-managed relational databases, partly to minimize carbon footprint and inefficiency . The serverless approach inherently optimizes resource usage (e.g., Cloud Run spins down containers when idle, so you’re not running hot all the time). Cost-wise, they likely saved money by not running large servers 24/7 – they pay mainly per use (Cloud Run, Firestore, etc., are usage-based). When certain peak loads were predictable (like a TV ad slot), they could temporarily allocate more Spanner nodes, then scale them down, which is more cost-efficient than over-provisioning permanent servers .
Results: By building on Cloud Run and its ecosystem, Kauche achieved a platform that could seamlessly handle viral growth. They were able to launch their app from zero to production in about two months , thanks to the productivity of fully managed services. Even with a tiny team, they maintained high reliability – no major downtime during big traffic spikes was reported. This case validates that GCP’s serverless container approach can power a real-world e-commerce app with excellent scalability and minimal ops burden. It’s essentially a container-based analog of the previous AWS case: instead of Lambda functions, they use containerized microservices; instead of DynamoDB, they use Firestore/Spanner; instead of SQS/SNS, they use Pub/Sub and Tasks. The outcome – in terms of scaling and agility – was similarly positive. One difference is that running containers gave them a bit more flexibility (e.g. they can use any language and handle longer running processes more easily than a short-lived function might). The trade-off is slightly more complexity than pure functions, but GCP’s managed services still abstracted away most infrastructure concerns.
Practical Insights: From an engineering perspective, one insight here is how serverless containers can accelerate development for microservices. The Kauche team noted that adopting containers from the start ensured portability and choice (they weren’t locked into a single function framework) . They can later migrate to Kubernetes Engine if needed without rewriting services, since everything is already containerized . For other teams, this highlights a path where you can start fully managed (Cloud Run) and only “graduate” to running your own clusters when you have to – which might be never, depending on scale. Also, using managed databases like Firestore and Spanner removed the need for a dedicated DBA or heavy DevOps for data. Firestore in particular is developer-friendly (being schema-less and with real-time SDKs), which can speed up application coding. However, one must design data usage carefully: e-commerce systems often need relational data (orders, inventory counts, etc.). Kauche supplemented Firestore with Spanner for exactly this reason , showing that a polyglot persistence approach is useful. In my own experience, using multiple databases is worth it if each service can pick the right tool (NoSQL vs SQL) – just ensure you handle consistency and transactions correctly when needed. Lastly, the team’s reliance on GCP’s monitoring tools underscores that visibility is key in a distributed system. They set up Cloud Trace, Logging, Monitoring from the get-go , which helped maintain performance SLAs. When building something similar, I’d recommend configuring alerts on things like error rates, Pub/Sub backlog size, or slow query times, so you catch issues early.
In summary, the GCP-based architecture delivered scalability, maintainability, and performance for a modern e-commerce use case. It shows that even without a large ops team, one can achieve high throughput and rapid development by leveraging cloud-native services like Cloud Run, Firestore, Pub/Sub, etc. . This strikes a balance between fully serverless function architectures and fully self-managed microservices – yielding an efficient, scalable platform with low operational complexity.
Case Study 3: Open-Source Cloud-Native Stack on Kubernetes (La Redoute)
Our final case study looks at an architecture built predominantly on open-source technologies. Not every company uses a single cloud provider’s stack; some build cloud-agnostic platforms using open tools to avoid vendor lock-in or to leverage open-source innovation. One such example is La Redoute, a major e-commerce retailer in Europe with over 10 million customers, which undertook a digital transformation to move from legacy systems to a modern microservices platform . Their journey shows how a containerized, open-source-based architecture can support high scale and fast delivery in online retail.
Background: La Redoute is a 180-year-old retail company that evolved from mail-order catalogs to a primarily online retailer . Around 2014, they faced a crisis – near bankruptcy – which forced them to overhaul their technology completely . The goal was to remove bottlenecks and enable the tech platform to be a business enabler, not a liability . They needed to accelerate feature development, increase deployment frequency, and handle growing traffic across their e-commerce sites and services. Reliability and multi-cloud capability were also priorities (they didn’t want to be tied to a single vendor). In short, they required a massive scaling and modernization of their architecture to compete in the digital era.
Solution Architecture: La Redoute’s tech team decided to adopt microservices orchestrated by Kubernetes as the core of their new platform . After some experimentation, they chose Kubernetes for container orchestration and complemented it with other Cloud Native Computing Foundation (CNCF) projects that fit their needs . Essentially, they built their own cloud-neutral platform using open-source components, both for the application runtime and for supporting infrastructure (CI/CD, monitoring, messaging, etc.). Here are the key pieces of their stack:
- Docker and Kubernetes: All applications were containerized with Docker, and Kubernetes became the standard platform to deploy and run those containers across their environments . This provided a consistent way to package microservices and a robust scheduler to run them on a cluster of machines (whether on-premise or cloud). Kubernetes gave them automatic scaling, self-healing, and easier multi-cloud deployment. Containerization was a “de-facto choice for portable deployments” and avoided any specific machine setup issues – if a service runs on one dev’s laptop in Docker, it runs the same in prod on Kubernetes .
- Helm (Deployment Automation): They used Helm charts to templatize and deploy applications on Kubernetes . Helm allowed the team to define reusable deployment templates, so spinning up a new service or environment was quick and consistent. This was crucial for improving developer productivity, as creating a new microservice went from days to minutes .
- CI/CD with GitLab: For the developer experience and automation, La Redoute selected GitLab as their CI/CD platform . They built a robust pipeline where every commit could go through automated tests and be deployed via Helm to a cluster. The result was the ability to do dozens of deployments per day. In fact, after the transformation, they accelerated from roughly 40 deployments per day to 80 deployments per day across their services . This high frequency was a huge leap in agility, reflecting an “Elite” DevOps performance level in industry metrics. The use of GitLab and containerization meant any developer could quickly provision a pipeline for their microservice and get it to production in an automated fashion .
- Observability: Prometheus and Grafana: To handle monitoring of many microservices, they deployed Prometheus (for metrics collection) and Grafana (for dashboards) as part of their platform . Prometheus would scrape metrics from Kubernetes and the apps (like HTTP request rates, latencies, error counts), and Grafana provided visualization. This combination gave them insight into system health and performance. It “answered the requirement of monitoring and recovery” in their new setup . They later explored using Istio service mesh and Jaeger tracing to further enhance observability and security at the network level .
- Messaging/Event Streaming with Apache Kafka: For asynchronous processing and data streaming needs, La Redoute incorporated Apache Kafka as the backbone of their event-driven architecture . Kafka enabled them to ingest and process large volumes of events in real-time – a common requirement in retail (think orders, inventory updates, user activity logs, etc.). By introducing Kafka, the platform could reliably handle scenarios like updating inventory across systems or building real-time analytics without locking up the main application flows. The choice of Kafka also supports replay and decoupling of services (one service can publish events that others consume on their own time). In large-scale retail, this is pivotal; for example, Walmart leverages Kafka for a real-time inventory system that processes 11 billion events per day across 8,500 nodes to serve their omnichannel experience . Likewise, many of La Redoute’s use cases (such as ingesting logs for analysis, syncing data to their website, etc.) could be handled by Kafka in a scalable way.
- Redis for Caching: Although not explicitly mentioned in the case study, it’s common in such stacks to use Redis as a distributed cache and session store. In many e-commerce platforms, Redis is used to cache frequently accessed data (product details, user sessions, etc.) to alleviate pressure on databases . We can reasonably assume La Redoute employed something similar (or an open-source ElastiCache equivalent) for optimizing performance, as they were very focused on scalability. Redis, being in-memory, can serve reads extremely fast and handle large throughputs, which improves page load times and keeps the database from becoming a bottleneck .
- Relational Database (PostgreSQL): For persistent data storage of transactions, user data, and other relational records, an open-source choice like PostgreSQL was likely used (or MySQL/MariaDB). PostgreSQL is a popular choice in cloud-native architectures due to its reliability and advanced features. It can handle quite heavy loads on decent hardware, and can be scaled vertically or with read replicas for more throughput. In fact, PostgreSQL has proven itself in large-scale scenarios – it’s often referred to as the “4x4 of databases” because it can handle complex queries and heavy data volumes without breaking a sweat . Many companies choose Postgres over MySQL as they grow for these reasons . In La Redoute’s context, they might have used managed PostgreSQL or an on-prem cluster, possibly supplemented by sharding or a distributed SQL layer for scaling (this is conjecture, but aligns with common practice). The CNCF case study doesn’t detail the database, but given their open-source tilt, Postgres or a similar open DB would fit the bill for core data storage
Architecture Impact: With this new open-source, microservices architecture, La Redoute achieved remarkable improvements:
- Accelerated Delivery: The platform removed previous bottlenecks in development. Creating a new service became “a matter of minutes, not days” , thanks to templates and automation. They reached 80 deployments per day at peak, indicating very frequent releases . This meant new features or fixes could go live continuously, giving the business a competitive edge in responsiveness. Engineers could independently deploy their microservices without waiting for a big coordinated release, thanks to the independent deployability microservices provide.
- Scalability & Stability: Today, La Redoute serves over 10 million online customers on this platform smoothly . The adoption of Kubernetes and cloud-native components allowed them to scale out as needed and improve uptime. If one microservice encounters a problem, it doesn’t bring down the whole system – fault isolation is improved (a broken “blog service” won’t affect the “checkout service,” for example). Kubernetes helped with self-healing (restarting crashed containers, rescheduling them on healthy nodes) and scaling services based on demand. Additionally, Kafka and other tooling ensured that spikes in one part of the system (e.g., a surge in user logs or orders) could be buffered and handled gracefully without knocking everything over.
- Multi-Cloud Flexibility: By using open-source and CNCF projects, La Redoute isn’t tightly coupled to a single cloud provider. They can run Kubernetes on AWS, Azure, GCP, or on-prem servers in their data center. This gave them leverage and flexibility in vendor choices. They explicitly aimed to limit vendor lock-in and maximize flexibility while managing total cost of ownership . Their Kubernetes platform was designed with portability in mind.
- Improved Developer Experience: Developers now have a self-service platform. Need a new database or message queue for a service? It’s provided through the platform’s catalog of open-source tools. Need to monitor something? Prometheus metrics and Grafana dashboards are readily available. The tedious work of setting up infrastructure for each project is replaced by platform APIs and templates. As a result, teams collaborate better – devs, ops, and architects all work from a common playbook (infrastructure-as-code, GitLab pipelines, etc.) . The ops team, freed from manually provisioning VMs or fighting fires constantly, can focus on improving the platform and infrastructure-as-code, further accelerating the organization’s capabilities .
Challenges Addressed: Initially, La Redoute had issues with long lead times for changes, infrequent deployments, and a high chance of failure on releases – classic symptoms of a legacy monolith. The new architecture addressed these by breaking the monolith into services and automating the pipeline. It significantly lowered the lead time for changes and the deployment failure rate by deploying smaller units more often. They also needed better scaling – the move to cloud-native microservices means each part of the system can scale independently (e.g., if the “order” service is experiencing high load, you can scale just that service’s pods on Kubernetes, without scaling the entire app) . This granular scaling was not possible before. The use of Kafka tackled the need for integrating numerous systems and ensuring no data loss or lag in processes like inventory sync – Kafka’s durable log and ability to integrate real-time and batch consumers solved those integration challenges in a unified way. Finally, by choosing open-source components, they also gained a strong community support and avoided licensing costs of proprietary systems.
Operations Considerations: Running an open-source stack is powerful but not without effort. Unlike a fully managed cloud service, here La Redoute’s team had to operate Kubernetes clusters (likely across dev/staging/prod), manage Kafka brokers, tune databases, etc. They mitigated this by incrementally building platform expertise and reusing components. For instance, they invested in reusable CI/CD templates and libraries to ease development and deployment across teams . They also validated the platform thoroughly (testing it for delivery speed, incident recovery, operations under load) before betting the business on it . This highlights that if you choose the open-source route, you should allocate time to build a strong “platform team” and invest in automation to manage complexity. La Redoute did exactly that – they formed a cross-functional platform team (architecture, engineering, ops, security all working together) to deliver this capability . Over time, they continued to improve it, adding service mesh (Istio) for better traffic management and security, exploring tracing (Jaeger), and so on as their needs evolved .
Another ops consideration is cloud cost vs. DIY: sometimes running your own open-source stack can be more cost-effective at scale, but one must consider engineering cost too. La Redoute’s decision was driven by strategic independence and fitting their culture of open-source adoption . They likely run Kubernetes clusters on cloud VMs or bare metal, and use open-source tools to avoid proprietary fees. This can save money if optimized well (for example, bin-packing containers on nodes for efficiency, using spot instances if on cloud, etc.). The flip side is the labor and expertise to manage it – which they justified by the benefits gained.
Results and Key Metrics: The transformation was a success. By 2020+, La Redoute had regained its position as a brand leader online, with 94% of sales coming through e-commerce and a thriving marketplace of products . Technology went from being a bottleneck to a competitive advantage. They measure their success partly by DevOps metrics: lead time, deployment frequency, etc., which all improved to “Elite” levels (multiple deploys a day, very low change failure rate) . Business-wise, the ability to continuously deliver improvements means the site can adapt quickly to market demands. For instance, if a new promotion or feature is needed, the teams can build and roll it out immediately. The platform is also resilient – they can handle infrastructure issues with minimal downtime. Self-healing and multi-AZ deployments in Kubernetes ensure high availability. And in the event of a big traffic surge, the team can scale out by adding more nodes to the cluster or more replicas to a deployment; plus, Kafka can buffer surges in activity (much like Pub/Sub in the GCP case or SQS in AWS case).
Lessons Learned: This case shows that a fully open-source, cloud-native architecture can meet the demands of large-scale e-commerce, but it requires a strong engineering culture and alignment. Some takeaways for practitioners:
- Invest in Platform Engineering: You’re essentially building your own “internal cloud.” Tools like Kubernetes and Kafka are powerful but need expertise to tune and operate. Having a dedicated team or at least dedicated effort to manage and evolve the platform is critical. La Redoute’s platform team approach and incremental rollout mitigated risks and allowed them to reap big rewards .
- Use Proven Open-Source Components: The components they chose (K8s, Helm, Prometheus, Kafka, etc.) are all battle-tested in industry. This reduces risk compared to using something very new or niche. Also, because these are popular, there’s a talent pool and community around them (and likely plenty of existing knowledge in the team, as they cultivated an open-source culture).
- Maintain Automation and Standards: With many moving parts, keeping consistency is key. Infrastructure as code, standardized Helm charts, logging conventions, etc., prevent chaos. La Redoute’s use of GitLab CI and templates ensured each service didn’t reinvent the wheel in how it’s built or deployed .
- Scalability is Holistic: They addressed scaling not just at the application layer, but also CI/CD (to handle many builds), data (using Kafka to scale data flows), and even organizationally (enabling teams to work in parallel without blocking each other) . True scalability in e-commerce isn’t only about handling users, but also about handling development at scale – many developers, many features. Microservices + DevOps practices achieved that.
- Open-Source vs Managed Trade-off: While they succeeded with open source, one should weigh this choice. If a company lacks the necessary in-house expertise or the scale to justify it, using managed cloud services (like in Case 1 and 2) might get you there faster. However, if strategic independence and maximizing customization are priorities, this case proves it can be done and can yield excellent results.
To put the three case studies in perspective, below is a comparison of their approaches and outcomes:
|
Approach |
Example Scale & Achievements |
Ops Overhead |
Primary Tech Stack |
|---|---|---|---|
|
AWS Serverless (Case 1) |
100+ microservices (Lambdas) running the entire e-commerce backend ; 5–10× faster feature delivery post-migration ; seamless auto-scaling for peak loads (no outages on big sales) |
Minimal – Fully managed services (no servers to manage). Operations focus on monitoring and IaC, not on provisioning/scaling. |
AWS Lambda, API Gateway, DynamoDB, SQS/SNS, Aurora Serverless, CloudFront, CloudWatch/X-Ray . |
|
GCP Serverless Containers (Case 2) |
~1.5 million users supported with <5 ops engineers ; daily deployments (5–6 features/week) ; handles sudden traffic spikes (e.g. 3× load from viral ads) without performance loss . |
Low – No cluster management, but some container build/ops knowledge needed. GCP manages scaling and infrastructure. |
Cloud Run, Cloud Load Balancer + Envoy, Firestore, Spanner, Pub/Sub, Cloud Tasks, BigQuery, Cloud Monitoring/Trace . |
|
Open-Source on Kubernetes (Case 3) |
10M+ customers, 80 deployments/day after re-platforming ; ~2× faster delivery lead time; high resilience via microservices isolation. Kafka pipelines handle billions of events/day in retail (e.g. Walmart’s 11B events/day inventory system) . |
Moderate – Requires SRE/platform team to manage Kubernetes, Kafka, DBs. High initial effort, but payoff in control and multi-cloud flexibility. |
Docker, Kubernetes, Helm, Prometheus/Grafana, Kafka, Redis, PostgreSQL, GitLab CI (all self-managed on cloud or on-prem) . |
Table 1: Comparison of the three architectures discussed, highlighting scale achieved, operational effort, and tech stack. Each approach succeeded in scaling e-commerce services, but with different philosophies: (1) outsource everything to cloud (serverless), (2) run containers on managed infrastructure (hybrid approach), (3) build a custom platform on open tech (max control).
Final Thoughts
There is no one-size-fits-all for scalable distributed architecture. Teams must choose based on their scale, operational maturity, and business goals.
Serverless platforms like AWS Lambda and Google Cloud Run offer speed and simplicity with minimal operations. Open-source cloud-native stacks like Kubernetes and Kafka provide greater control and flexibility at the cost of higher management effort.
Regardless of the approach, successful architectures consistently focus on decoupling, automation, observability, and elasticity.
Studying real-world systems helps us design platforms that can scale reliably and evolve with business needs.
Opinions expressed by DZone contributors are their own.
Comments