The Science Behind Durability: Write-Ahead Logging Explained
For any persistence store system, guaranteeing durability of data being managed is of prime importance. Read on to know how write ahead logging ensures durability.
Join the DZone community and get the full member experience.
Join For FreeFor any persistence store system, guaranteeing durability of data being managed is of prime importance. To achieve this durability, the system should be resilient to failures and crashes, which are inevitable and could happen at any point of time.
Once the system agrees and acknowledges to perform any action, it should honor it even in case of a crash. Thus, for systems to know what actions it has agreed to perform, but might not have them executed yet, write ahead logs (WAL) are employed.
Write Ahead Logs Defined
WAL (sometimes also referred as REDO or commit logs) simply are a collection of immutable log entries appended sequentially to a file stored on a hard disk.
For each command, a system makes a log entry to WAL first. Only once the system confirms the log entry is successfully written to WAL, the specified action in command is performed. Upon the successful completion of the action, the log entry is marked as committed. This ensures that even in case of any failure or crash between the write to WAL and the action being performed, on recovery/restart the process will perform the pending action(s). Thus, durability is guaranteed.
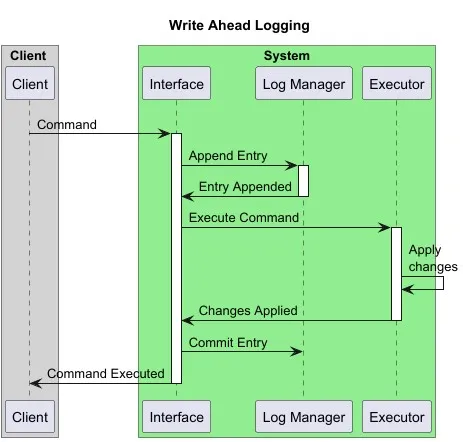
Figure 1 — Write-Ahead Logging before command execution to ensure durability
It's crucial to note that WAL relies heavily on a stable storage system itself. In case of a media failure, whole WAL files could be lost. Thus, to tolerate such failures, replicated logs are used.
Performance Considerations for Write-Ahead Logging
Flushing each write ahead log entry to a disk may immediately provide a strong durability guarantee, but it could be inefficient in terms of performance. Thus, as a tradeoff, multiple log entries are batched while flushing. This however comes with risk of losing more entries in case of failure or crash.
To improve overall throughput, WAL is prioritized over action. Both are decoupled such that actions are performed asynchronously post-log entry. This could mean the system sees the changes being applied with delays. If such delays are significant and unacceptable, decoupling can be switched off.
Ideal Log Entry Structure
Each log entry should:
- have all required information to perform a specific action. For example, a change of user name from JohnDoe to FooBar (which in RDBMS terminologies translates to "update USERNAME to FooBar" in table USER which previously was JohnDoe). To achieve atomicity, a set of actions can be batched together and written as a single log entry.
- be assigned a unique identifier viz. Log Sequence Number (LSN), ensuring a strict order of execution. This helps in recovering the exact state of system.
- have either a cyclic redundancy check (CRC) or an end-of-entry marker to detect and discard corrupted entries. Log entry corruption is possible due to various reasons such as incomplete write (arising out of sudden process crash) or network/transmission failures.
Scalability Considerations
As the system grows consider the following:
- a single WAL file could quickly become a bottleneck. To overcome any such limitations, segmented logs can be utilized to scale the system by logically splitting them into smaller files, i.e. segments for easier management.
- clean up of committed log entries via low water mark (LWM) can be performed. LWM is a threshold which signifies that all entries up to it are applied and thus can be safely discarded. These committed log entries are identified via their respective LSN.
System Recovery
On recovery, from either failure or crash, the system scans the write ahead logs and performs all pending actions starting from the checkpoint (or last committed entry identified via its LSN). While doing so, the system advances the checkpoint to newly applied changes. The system also identifies and discards corrupted entries to maintain data integrity, where applicable.
Since the log entries are immutable and append only, WAL could have duplicates due to client retries or other errors. Thus, recovery should either be idempotent or employ a mechanism to identify and discard duplicates.
WAL Usage and Similarities
- All traditional RDBMS systems and a few NoSQL systems use write-ahead logging to guarantee durability.
- Apache Kafka utilizes similar structure as WAL for its storage and replication needs.
- The Git concept of “commit” is similar as a log entry to journal every change. This can be used to restore any previous state.
Further Reading
Algorithms for Recovery and Isolation Exploiting Semantics (ARIES) is a popular algorithm utilizing WAL.
Write-Ahead Logging vs. Event Sourcing
While both WAL and event sourcing involve logging changes, they serve different purposes and operate at different levels of abstraction. WAL is a low-level technique for ensuring data integrity in databases, while event sourcing is a higher-level architectural pattern for capturing and utilizing the complete history of a system’s state changes.
Also, they differ in terms of lifespan and granularity. Write ahead logs are short lived and focus on the “how” behind data changes, while event sourcing may keep data indefinitely to construct a state at any point of time (historical) with focus on the “what” happened in a system from a business perspective.
Published at DZone with permission of Ammar Husain. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments