Search Engines vs Recommendation Engines and The Impact of Deep Learning
Read on to understand how they differ and why this could change with the advent of deep learning, machine learning, and Artificial Intelligence.
Join the DZone community and get the full member experience.
Join For FreeAt first glance, the differences between eCommerce product search and product recommendations seem fairly obvious. We have all seen clear-cut examples of both when shopping online, but often during different stages of the customer journey.
However similar they may seem in terms of underlying technology, conventional search engines are quite different from product recommendation engines. Behaviour is typically at the center of a recommender system, while it is an added dimension for the search engine.
Read on to understand how they differ and why this could change with the advent of deep learning, machine learning, and Artificial Intelligence.
The Many Types of Recommendation Engines
You don’t have to look very hard to find lots of different eCommerce recommendation systems with varying characteristics and qualities. You have most likely encountered many types already. They range from highly specialized, proprietary solutions for specific websites or applications, to generic and rather simple variants.

Some good recommendation engines take advantage of Big Data to deliver personalized recommendations based on a visitor's previous activities and those of other similar customers.
Amazon provides a good example of a more sophisticated recommendation system (built in-house), which (among other things) suggests accessories for products the visitor is about to purchase, based on what other customers have bought together with the item.
This is, of course, a powerful tool to increase average order values, but requires significant amounts of customer data to function automatically. An amount of data most retailers - aside from Amazon - don't have, and most third-party recommendation engines can't handle.

Most 3rd party recommendation engines will make suggestions by analyzing shopping behavior alongside the relationships between products and product categories. It uses a large amount of behavior data to draw conclusions about a single product or a small set of products.
In order to create customer segments and use those segments to predict what a visitor may be interested in, the engine finds a set of customers whose purchased items overlap with the visitor's previously purchased items. The algorithm aggregates items from these similar customers, eliminates items the visitor has already purchased, and recommends the remaining items to the visitor. A technique referred to as "collaborative filtering".
The engine then offers a series of recommendation lists to be used at different points in the customer journey (e.g. product page, checkout page, search results page, category page, post-visit-emails, etc.). These separate recommendation lists are typically based on the following data:
- The visitors' past browsing behavior (page views, clicks, add-to-carts, purchases)
- Category best sellers or most popular items (most clicked, most purchased by other visitors)
- High-margin items from the same category as the item being viewed
- Shipping costs (i.e. listing products with no shipping costs)
- Search query (i.e. displaying the products that other visitors purchased following the same query)
- Note: this usually just leads to a redundant list of products already provided as search results. Acting more to reinforce which search result to choose.
- Complementarity (i.e like Amazon's suggested accessories lists)
- Note: Amazon has enough data that it can determine what is potentially an accessory by looking at what past customers bought together with the item in question. Retailers that do not have Amazon level data will need to create the associations between products manually - more often relying on basic category structure (e.g. showing a list of shirts when viewing a pair of pants)

Most recommendation solutions will also provide a configuration interface for creating IF-Then business logic filters that help to promote sale, high-margin, low-priced etc. items more prominently in recommendation lists.

Finally, nearly all proprietary recommendation solutions will provide functionality for promoting those recommended products through email campaigns as well as through on-site banners and navigation. The better tools will include a way to use the recommended items in display advertising.

Why Product Search Engines Are Not Good Product Recommendation Engines
Conventional product search engines barely require a detailed introduction. Basic site-search is available as a standard plugin for, or built into, all modern eCommerce platforms. Most of them are relatively simple and easy to use, featuring basic text-matching. They typically support indexing of product titles, descriptions and category structure, auto-correct, fuzzy-match (handle plural queries and stemming) and recognize synonyms (often through a configurable dictionary).
The classic search problem involves things such as language processing (tokenization, stemming etc), indexing, query expansion, product ranking and so on. Advanced search engines can focus on word similarities and word clustering.
The most basic search algorithms available do something like the following:
- Break query string into words
- Compose the search query by targeting known data fields like title, description, features, word by word. The where statement will look like ‘where (description like ‘%red%’ or features like ‘%red%’ or title like ‘%red%’) and (description like ‘%bag’ … etc etc)‘
3. Display results in rank order depending on where the query term appeared in the product metadata (e.g. a match found in the product title has more weight than a match found in the description).
While a recommender engine could use a method to find similar products that resembles a search algorithm, the input for such a system is completely different than what an actual search engine uses as an input (i.e. search engines use text string as input, not products).
The recommender system will treat the recommendation problem as a search for related items - using the product being viewed or bought by the visitor as the input. So, given the product as an input, the algorithm creates a search query with a set of query rules to find other products by the same brand, within the same category or with similar keywords.
Unfortunately, this search-based recommender system scales poorly for customers with numerous purchases/visits and typically offers either too broad or to narrow recommendations. Since recommendations are designed to help visitors find and discover new, relevant, and interesting items, products from the same brand or category found through a search-like method don't often meet this objective.
Why Product Recommendation Engines Are Not Good Product Search Engines
Providing a list of popular items, high-margin or sale items as search results hardly leads to a "relevant search experience". Searching visitors have something specific in mind and expect search results to reflect that intent exactly. This is a very different customer journey than a visitor simply browsing.
Unlike recommender systems that use behavior data to draw conclusions about a single product or small set of products, search systems must find and rank all products against a text string (i.e. the search query), not against a product or set of products.
So although the difference between the query string 'blue hat ' and an actual Blue Hat product seem small at first, they are completely different input.
 This retailer's recommended sale items have no connection to the search query "blue hat" and therefore lead to completely irrelevant search results.
This retailer's recommended sale items have no connection to the search query "blue hat" and therefore lead to completely irrelevant search results.
If the search results page includes a secondary list of popular items from the same category as the top search results, it's a nice bonus and can help increase basket size. But, it's not likely to have any bonus effect if the search results aren't relevant to begin with.
In this instance, the visitor is likely to assume the retailer does not carry what they are looking for and leave the site altogether.
Unfortunately, more often than not, the only reason the search returned irrelevant or null results is because the visitor made a small typo in their query or they used a different taxonomy than what the retailer uses.
Recommended Results and the Future of Product Search
When using the default solutions provided by eCommerce platforms like Magento, product recommendations and product search are separate features, both of which often require manual configuration and maintenance to function properly.
Even with a moderate product range, countless hours can be spent on tweaking and redirecting search results, or adding related products on the individual product level. It often becomes time-consuming up to a point where the functionality is partly or entirely neglected, which in turn leads to lower conversion rates and a sub-par user experience.
Fortunately, opting for a quality third-party provider can mitigate all of these issues. But it is important to keep in mind that search engines and recommendation engines are very different beasts - the algorithms function very differently.
While recommender systems tend to focus on solving problems such as:
- Data sparsity: in order to have an effective system you usually need to have a large number of users that have interacted heavily with the website. This group of people will have a large influence in how the recommender engine works
- Cold-start: when fresh, the engine has no, or very little, behaviour data. Depending on the retailer, it can take months to accumulate enough behaviour data.
- Huge amounts of data
Search engines typically focus on things like:
- Efficient indexing: used to quickly locate data without having to search every row in a database table every time a database table is accessed
- Attribute ranking rules: rank results by their expected relevance to a user's query using a combination of query-dependent and query-independent methods
- Fuzzy query matching: approximate string matches (e.g. “rmabo” vs “rambo”)
- Stemming: getting words to match each other even if they are not in the exact same form (e.g. run/runs/running/ran or cat/cats)
- Tokenization: the process of breaking a stream of text up into words, phrases, symbols, or other meaningful elements called tokens
One of the most critical differences between these two types of engines is that visitor behaviour is at the center of a recommender system, but is an added dimension for a search engine.
In advent of Machine Learning, search algorithms have been able to make great strides when it comes to using behavior data. Allowing click, add-to-cart and purchase behavior to influence the sorting of results (i.e. no more sorting based only on where the text-match was found in the product metadata).
Deep Learning has brought forward the ability for search engines to understand the relationships between products - before any query has been made or any behavior data has been gathered. In this way, the search engine can locate similar or related products beyond a basic shared category or brand. It can identify complex patterns within all the metadata and build a deep architecture to the product catalog.
From this foundation, a Deep Learning search engine can produce a list of recommended products that have no relation to the actual search query. Although these recommended products are generated differently than those generated by classic recommender systems, they can have the same effect on the customer experience.
Providing a list of 'recommended products' that are similar to the product being looked at or searched for can — and will – lead to increased conversion rates and basket size.
Deep Learning Product Search and Recommendations
Deep Learning enables a search engine to map relationships between products that never existed before. In doing so, it can produce an intelligent, self-optimising list of 'recommended results' that are completely unlike those provided by recommender systems.
Moreover, this type of engine requires basically zero behavior data to function - nearly eliminating the cold start problem (Note: behavior data should be added to the engine to help refine the sorting of products for greater relevancy).
Loop54 does precisely this. Our Related Search Results (named as such to avoid confusing our service with Product Recommendations), are a list of products that have nothing to do with actual search query. They are instead related to the products found through search.
Our Related Results typically relate to the direct search results in one of three ways:

Not only can our Deep Learning search engine identify related or similar items automatically (i.e. no more manual backend If Then rule setting), it can also use much smaller amounts of behavioral data to refine the relevancy and order of products in the list.
How can it do that? Well, because each behavioral data point is attached to a network of products, not a single SKU. Learn more about how this works.
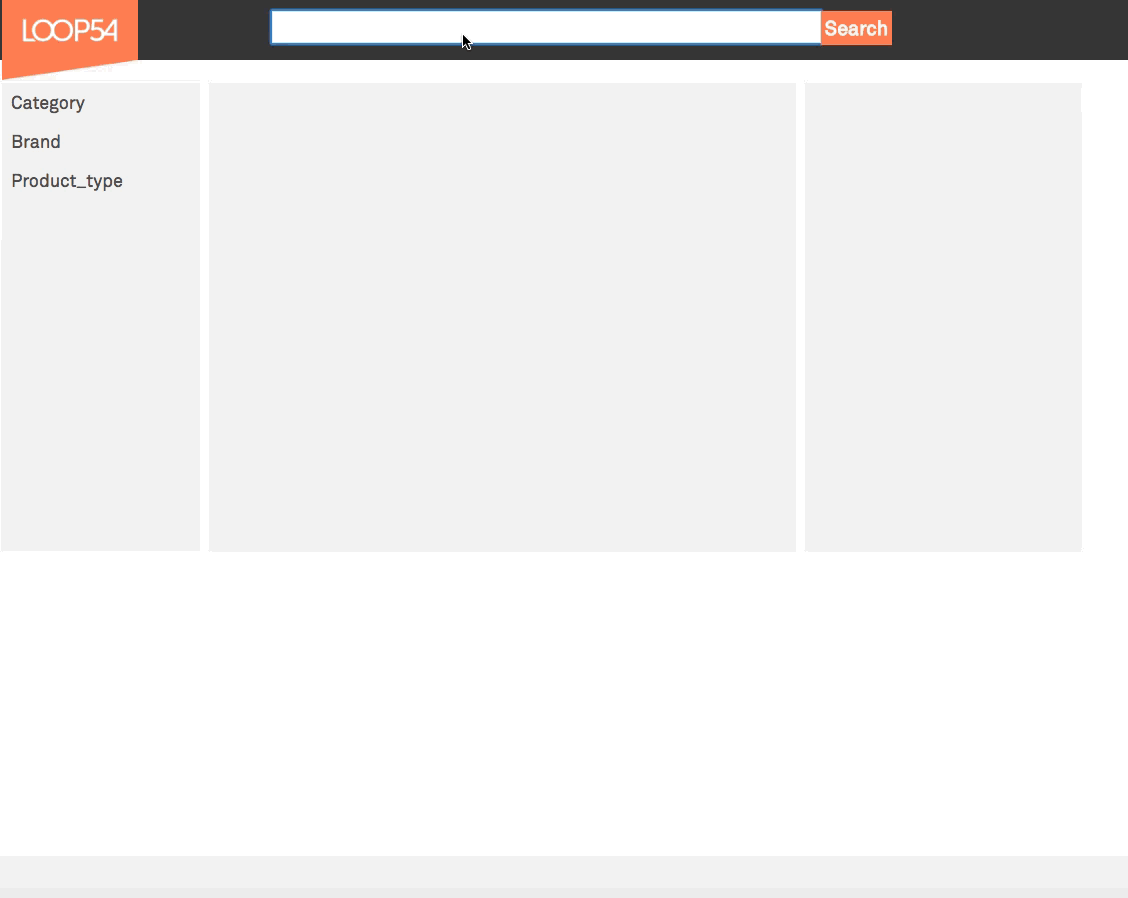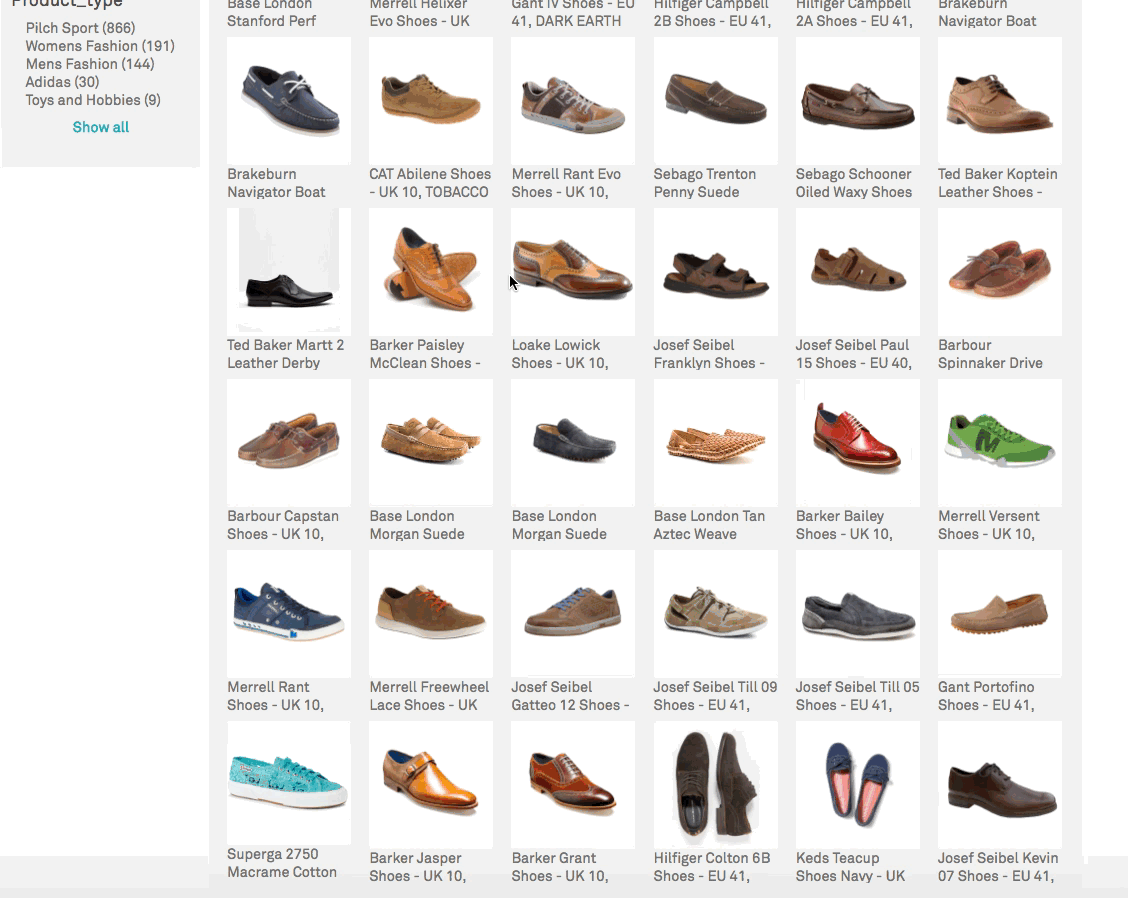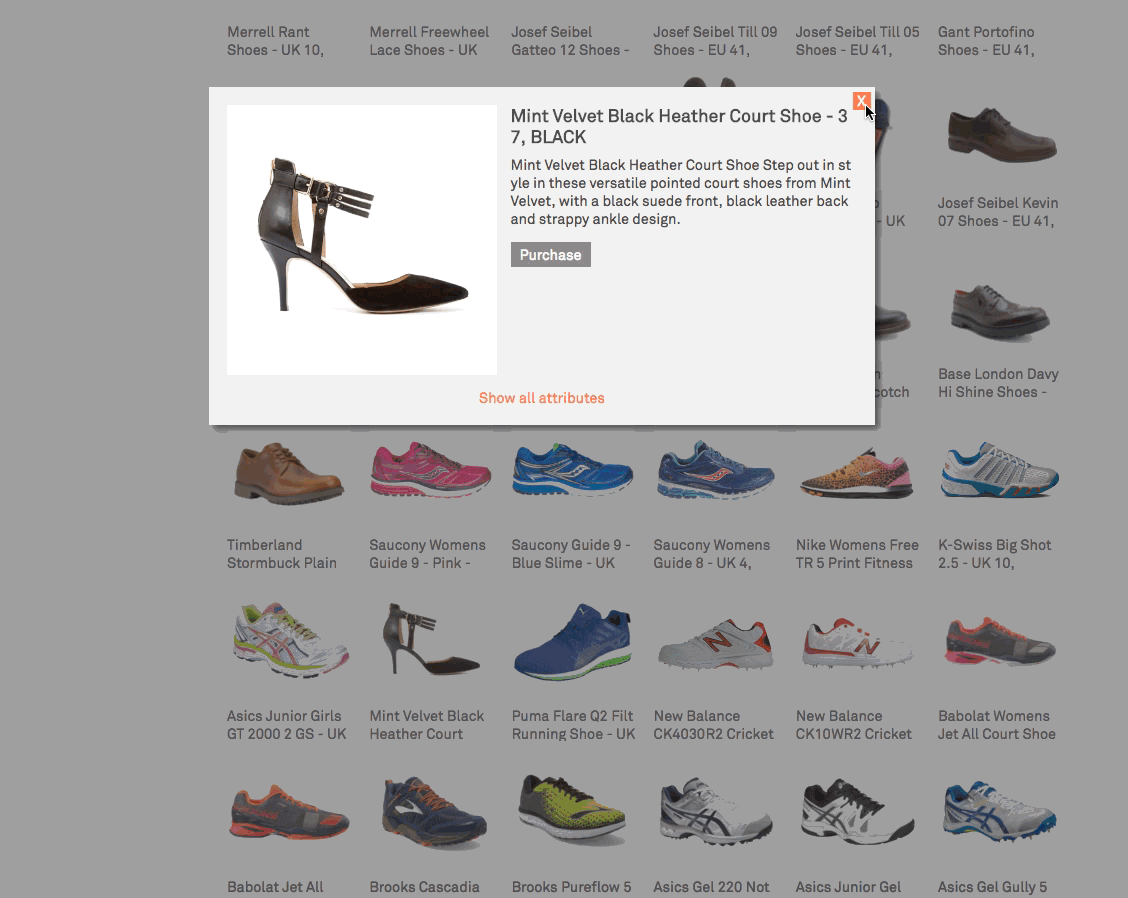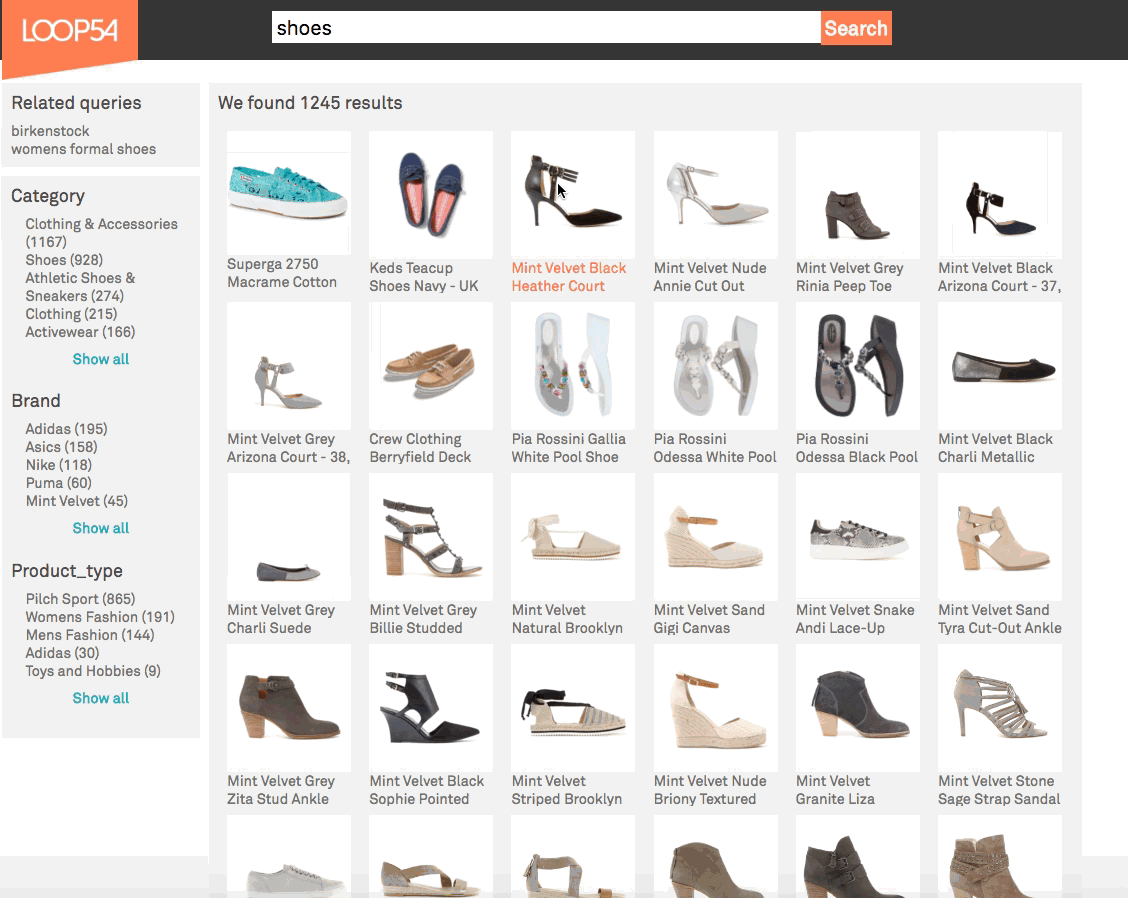
This GIF example shows how even a single behavioral data point can influence the sorting of all results. A purchase of women's shoes out of a list of results dominated by men's shoes influences the sorting of results for the next search. Putting more women's shoes at the top of results (i.e. not just that one pair of shoes that was previously purchased). This allows for behavior to influence relevance at the general level (i.e. popularity) and the personal level (i.e. personalisation).
Published at DZone with permission of Vanessa Meyer. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments