Securing Parquet Files: Vulnerabilities, Mitigations, and Validation
Parquet files are widely used in big data ecosystems, but vulnerabilities like CVE-2025-30065 highlight the importance of secure handling.
Join the DZone community and get the full member experience.
Join For FreeApache Parquet in Data Warehousing
Parquet files are becoming the de facto standard for columnar data storage in big data ecosystems. This file format is widely used by both sophisticated in-memory data processing frameworks like Apache Spark and more conventional distributed data processing frameworks like Hadoop due to its high-performance compression and effective data storage and retrieval.
Major companies like Netflix, Uber, LinkedIn, and Airbnb rely on Parquet as their data storage file format for large-scale data processing.
The Rise of Vulnerabilities
Although open-source Java libraries are essential for contemporary software development, they frequently introduce serious security flaws that put systems at risk. The risks are highlighted by recent examples:
- Deep Java Library (CVE-2025-0851): Attackers can write files outside of designated directories due to a path traversal vulnerability in DJL's archive extraction tools. Versions 0.1.0 through 0.31.0 are affected by this vulnerability, which may result in data corruption or illegal system access. Version 0.31.1 has a patch for it.
- CVE-2022-42003, Jackson Library: Unsafe serialization/deserialization configurations in the well-known JSON parser cause a high-severity problem (CVSS 7.5) that could result in denial-of-service attacks.
These illustrations highlight how crucial it is for open-source libraries to have careful dependency management, frequent updates, and security audits. Companies should enforce stringent validation and use automated vulnerability scanning tools.
Parquet-Avro Module of Apache Parquet (CVE-2025-30065):
During the life cycle of data load into the Enterprise data lake, we use file format conversions like ORC to Avro, Avro to Parquet, and Parquet to Avro. To achieve this conversion, Spark, in this case, uses underlying jars like parquet-avro.
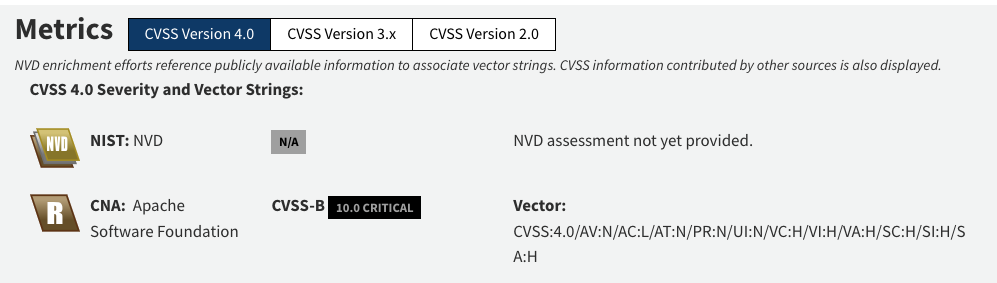
On April 2nd, 2025, one such vulnerability was reported on the parquet-avro module with the highest severity rating (CVSS 10.0, “Critical”). When the parquet-avro module deserializes untrusted schemas embedded in Parquet files, it creates a vulnerability known as the Deserialisation of Untrusted Data (CWE-502).
In order to cause arbitrary code execution during file parsing, attackers can insert malicious code into these schemas. Since many systems implicitly trust Parquet files in data workflows, this gets around common security controls.
Example of an Attack Scenario
Exploiting CVE-2025-30065 in Apache Parquet:
Step 1: Crafting the Malicious File
The attacker first creates a Parquet file embedded with a corrupted Avro schema. This schema includes malicious payloads that are meant to run when ingested, like binary code or scripts. Targeting systems that depend on external or unreliable data sources, the attacker may pose this file as authentic data in order to evade detection.
Step 2: Delivery to the Target System
The malicious Parquet file is delivered to the victim's system by the attacker. Phishing emails, compromised third-party data providers, or direct uploads to shared repositories could all be used to accomplish this. Files are frequently processed automatically in settings like cloud data pipelines or big data platforms (like Hadoop and Spark), which makes exploitation more likely.
Step 3: Exploitation During File Processing
The parquet-avro module tries to parse the schema of the Parquet file when it is processed by the vulnerable system. The embedded exploit payload is executed as a result of the deserialisation process's incorrect handling of untrusted data. This gives the attacker the ability to execute arbitrary commands or scripts on the system through remote code execution (RCE).
Step 4: Impact on the Victim System
Once control is gained, attackers can:
- Install malware: Deploy ransomware or crypto miners.
- Exfiltrate data: Steal sensitive datasets stored in the system.
- Tamper with data pipelines: Inject false data or disrupt workflows.
- Cause service disruption: Shut down critical services or corrupt files.
Mitigation Steps
1. Dependency Audit
Investigate
To find out which dependencies in your projects are out of date, use tools such as Maven. For example:
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.15.0</version> <!-- vulnerable version -->
</dependency>
Mitigate
Upgrade immediately — patch to the latest stable release, i.e., Apache Parquet 1.15.1, which resolves the issue. Explicitly mentioning the version in the dependencies forces the project to use the patched jar.
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>1.15.1</version> <!-- patched -->
</dependency>
2. Validate File Sources
Investigate
- Magic number checks: Although this isn't a security measure in and of itself, make sure Parquet files start and end with "PAR1" in order to identify non-Parquet files early
- Schema validation: To stop deserialization attacks, reject files with unexpected or distorted schemas.
Mitigate
Wait until systems have been updated with the patched version of Parquet jars before processing Parquet files from untrusted sources.
3. Audit and Monitor Logs
Investigate
- Anomaly detection: Keep track of all Parquet file ingestions and keep an eye out for odd activity, such as unexpected file sources.
- Sensitive data scanning: Identify and categorize PII, financial information, or medical records in Parquet files
Mitigate
To identify unusual activity, enable thorough logging for Parquet file ingestion.
4. Restrict Access and Permissions
Investigate
- Role-based access control (RBAC): Use tools such as AWS IAM or Azure AD to restrict file access while upholding the least privilege principle.
- Network segmentation: To lessen attack surfaces, separate Parquet processing systems from open networks.
Mitigate
Implement RBAC, zero-trust principles, and network segmentation.
// AWS IAM policy snippet for Parquet file access
{
"Effect": "Allow",
"Action": "s3:GetObject",
"Resource": "arn:aws:s3:::data-lake/*",
"Condition": {
"StringEquals": {"aws:MultiFactorAuthPresent": "true"}
}
}
5. Secure File Sources
Investigate
- Trusted origins only: Unless it's absolutely required, do not process files from sources that are not trustworthy.
- Sandbox testing: Examine untrustworthy Parquet files in different environments ahead of ingesting them into production.
Mitigate
Report and remove impacted Parquet files from processing. Adhere to business policies when implementing vulnerability mitigation techniques.
Conclusion
Organizations dealing with critical data must prioritize the security of their data pipelines to protect against threats such as tampering, exfiltration, and ransomware. As data pipelines often process sensitive information across distributed systems, they are prime targets for attackers seeking to exploit vulnerabilities, disrupt operations, or steal valuable data.
Following industry standards and implementing robust security measures is essential to ensure resilience and trustworthiness.
Published at DZone with permission of Vamshidhar Morusu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments