Backlog Black Hole: Engineering a Semantic Triage Engine at Scale
Learn to reduce duplicate bug reports with semantic search: embeddings, FAISS, and GPT-4o streamline triage, saving engineers hours on large ticket backlogs.
Join the DZone community and get the full member experience.
Join For FreeOur bug tracker manages more than 150 million issues. It’s growing at 20% compounding annually. Roughly 25% of issues are duplicates. That is approximately 35 million issues and growing. Due to the large amount of duplicates in the system, it takes an enormous amount of time to go over them. This results in huge productivity loss. Last quarter, this led to hundreds of duplicate issues being triaged separately, even when they shared the same root cause. Engineers spent days re-investigating problems that had already been diagnosed elsewhere. Keyword search helps, but most of the time, it lacks in surfacing issues that are not an exact match, but are semantically similar.
As ticket volume increased, manual triage became an absolute mess and cumbersome. Incoming issues were categorized independently by different teams, with no reliable mechanism to detect semantic overlap. We observed multiple reports describing the same failure using different surface language, such as transport-layer timeouts versus UI authentication hangs, which were treated as unrelated by the keyword index. Because ownership was assigned per ticket rather than per underlying defect, these reports diverged into separate investigation paths. The result was duplicated debugging effort and delayed resolution, even when the root cause was already understood elsewhere in the system.
To address this, I implemented a semantic clustering pipeline (also calling it Semantic Grooming Agent) for incoming tickets. Each issue is embedded at ingestion time and compared against existing reports using cosine similarity rather than token overlap. Issues that exceed a similarity threshold are grouped under a shared defect identifier, allowing ownership and investigation to converge early. This reduced duplicate triage and made related failures discoverable even when described at different layers of the stack. In practice, engineers now search by intent and retrieve prior investigations instead of starting from scratch.
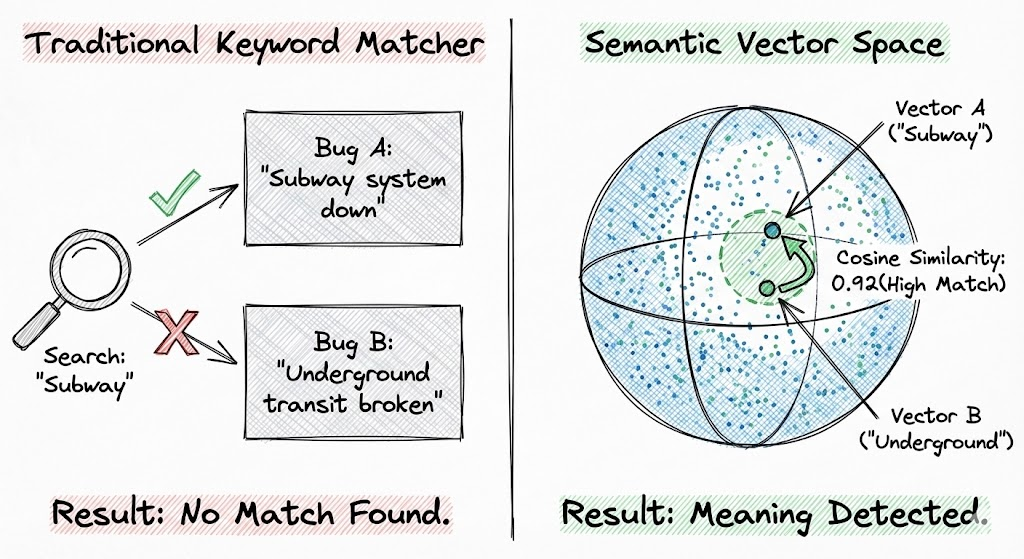
Core Problem: The Keyword Search
In the past, keyword search, or lexical search, worked well when there were fewer issues and most of them were created manually. However, over time, as automation increased and the number of issues increased, the quality of results that were surfaced by keyword search produced subpar results. If you search for "Subway," but the original ticket uses the word "Underground Transit," the system returns zero results.
We solved this gap using smart search. Smart search is built using vector embeddings. By converting every ticket into a high-dimensional vector (using 3072-dimensional embeddings), we can measure the mathematical "distance" between ideas. In this space, "Authentication failure" and "Login timeout" exist in the same neighborhood, regardless of their specific vocabulary. This cosine similarity produced amazing results. I’ll talk more about this later.
The primary metric for comparison is cosine similarity, which measures the cosine of the angle between two vectors.
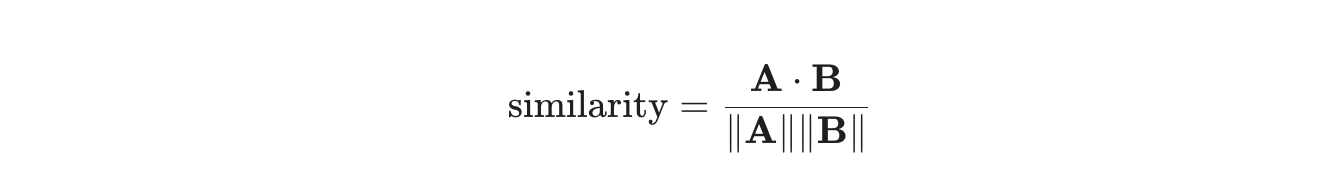
In Python, leveraging NumPy for this calculation ensures that we aren't throttled by raw interpreter speeds:p
import numpy as np
def calculate_similarity(vec1: list[float], vec2: list[float]) -> float:
"""
High-speed similarity check.
At enterprise scale, raw Python loops are a non-starter.
"""
a, b = np.array(vec1), np.array(vec2)
return float(np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b)))Scaling to Millions: From $O(n^2) to $O(log n)
Calculating $O(n^2)$ comparisons for a "small" subset of 50,000 issues involves 1.25 billion calculations. For a backlog of over a million, this approach hits a computational wall.
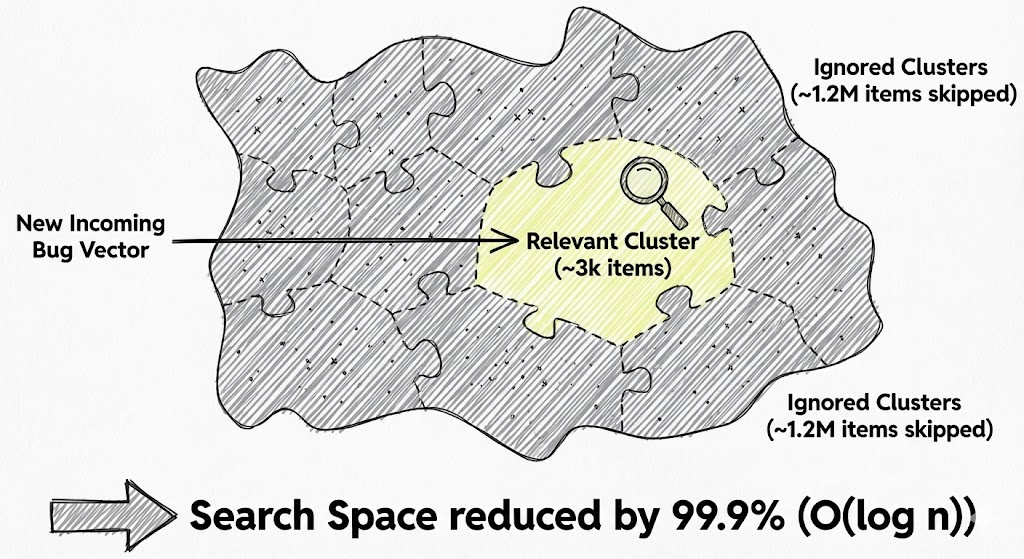
To achieve sub-second retrieval, we implemented Approximate Nearest Neighbor (ANN) search using FAISS (Facebook AI Similarity Search). Instead of a linear scan, we use an Inverted File Index (IVF) to cluster the vectors into Voronoi cells. When a new ticket is submitted, the engine only searches the most relevant clusters, reducing the search space by 99.9%.
import faiss
class SemanticIndex:
def __init__(self, dimension: int = 3072):
# Using IndexIVFFlat for balance between speed and accuracy
quantizer = faiss.IndexFlatIP(dimension)
self.index = faiss.IndexIVFFlat(quantizer, dimension, 1000)
def add_to_index(self, embeddings: np.ndarray):
if not self.index.is_trained:
self.index.train(embeddings)
self.index.add(embeddings)Reasoning Layer: GPT-4o as a Triage Assistant
Finding "mathematically close" issues is not the end. High similarity doesn't always mean a duplicate; two issues might be 94% similar but refer to different hardware revisions or OS versions.
We use GPT-4o as the "Reasoning Layer." Once the FAISS index identifies the top five candidate duplicates, the LLM analyzes the technical context of both to suggest a specific action: merge, link, or ignore.
async def get_triage_suggestion(self, issue_a: dict, issue_b: dict) -> dict:
prompt = f"""
Compare these two technical reports:
A: {issue_a['summary']} - {issue_a['description']}
B: {issue_b['summary']} - {issue_b['description']}
Determine if they share a root cause. Provide a 'confidence_score'
and a 'recommended_action' (MERGE/LINK/KEEP).
"""
# Utilizing JSON mode for structured integration
response = await self.openai_client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"}
)
return responseOvercoming the "JSON Schema" Trap
A significant hurdle in building this was data ingestion. Our internal bug tracking system uses a deeply nested JSON schema (similar to Atlassian Document Format) for descriptions. Embedding the raw JSON resulted in "noisy" vectors because the model was weighting UI metadata as heavily as the technical content.
We implemented a recursive parser to flatten the document tree and isolate the human-written technical signals before the embedding phase.
Real-World Results
We deployed this engine against a localized backlog of roughly 10,000 issues that had already been "manually" groomed.
- Discovery: The tool identified 450 duplicate pairs above the 0.88 threshold.
- Precision: Upon human review, 92% of the AI's suggestions were correct.
- Efficiency: A manual review of this volume typically takes a senior lead 40+ hours. The semantic engine completed the scan and generated merge summaries in less than 4 minutes.
Architecture Overview
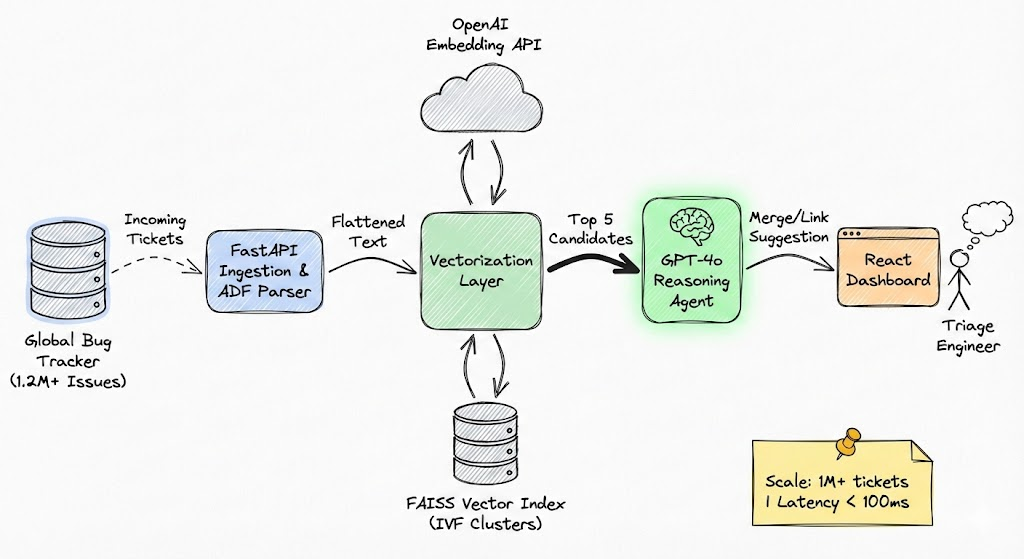
- Ingestion: A FastAPI worker pulls new tickets from the Bug Tracking API.
- Vectorization: Tickets are converted to embeddings via OpenAI’s
text-embedding-3-large. - Indexing: Vectors are stored in a FAISS IVF index.
- Retrieval: Incoming tickets trigger a similarity search against the index.
- Refinement: Candidates are passed to GPT-4o for a final "human-like" reasoning check.
- Human-in-the-Loop: A React dashboard presents the side-by-side comparison for final engineer approval.
Conclusion
At enterprise scale, the backlog is a data problem, not just a management problem. By shifting from keyword-based (aka lexical search) tools to a semantic architecture, we’ve effectively eliminated the "Black Hole." The goal isn't to replace the engineer’s judgment, but to automate the noise reduction so that engineers can focus on what they do best: solving the bugs, not just sorting them.
The icing on the cake, even if issues surfaced using semantic search were not exact duplicates, many times we have seen finding similar issues resulted in solving the issue at hand faster, cheaper, and avoiding repeated common pitfalls.
Opinions expressed by DZone contributors are their own.
Comments