Evaluating Similariy Digests: A Study of TLSH, ssdeep, and sdhash Against Common File Modifications
Traditional hashes miss unknown malware. Similarity digests like TLSH, ssdeep, and sdhash improve detection by comparing file similarities. This article benchmarks them.
Join the DZone community and get the full member experience.
Join For FreeThe field of digital forensics often uses signatures to identify malicious executables. These signatures can take various forms: cryptographic hashes can be used to uniquely identify executables, whereas tools like YARA can help malware researchers identify and classify malware samples. The behavior of files— functions exported, functions called, IP addresses and domains they connect to, files written or read—also provide useful indicators that a system has been compromised.
Cryptographic hashes, YARA rules and indicators of compromise are usually compared against curated databases of trusted or malicious signatures, such as those maintained by the National Software Reference Library and MalwareBazaar. Hashes like MD5 and SHA256 are designed to change drastically even with minor modifications to the original executable, making it easy for malware authors to evade. Modern cloud environments make it easy to evade behavioral detection as well, allowing threat actors to tailor their malware to specific platforms. In general, matching against feeds of known indicators misses unknown or undiscovered threat vectors.
Security researchers have proposed “similarity digests” to improve file identification rates. These digests attempt to produce compressed representations of the original data that are suitable for similarity comparisons. Similarity digests protect against unknown threats by associating them with known malicious behavior.
Several similarity digests have been proposed in literature, but the most popular in practice are TLSH, ssdeep and sdhash. This article evaluates these three digests against common file modifications in an attempt to give security researchers a practical benchmark to decide which digest(s) may be right for their specific use case.
Experimental Setup
The dataset curated for this experiment attempts to cover the different types of file modifications security practitioners may see in the wild.
Dataset
Plain Text Documents
Simple text overlap is a useful baseline to evaluate similarity digests. A randomly generated set of 50 paragraphs (approximately 3,300 words) of English text were saved in Microsoft Word document format. Variations of the document were generated by removing 5 paragraphs at a time, resulting in 10 total documents, ranging from 5 paragraphs through 50 paragraphs.
Executable Files
Security practitioners are most interested in detecting malware binaries that are slightly different from known binaries. For this benchmark, several builds of the game Dwarf Fortress are evaluated against each other. Specifically, similarity digests are computed on the last 13 Windows releases and the last 7 Linux releases (both spanning major versions 51.xx and 50.xx) and evaluated for similarity. The intuitive expectation is that minor versions that are closer to each other are more similar than minor versions that are farther away, which in turn are more similar than comparison across major versions.
Compressed Files
Often, malware authors compress malicious executables along with other files to evade detection. To evaluate the effectiveness of similarity digests in detecting this particular attack technique, the zipped and tarballed Dwarf Fortress bundles are compared with the main executable file. The compressed bundles contain the main executable along with several other game assets like images, bitmaps and configurations.
Embedded Files
Malware authors also embed malicious executable content in benign looking file formats like Microsoft Word documents or PDFs. This is the primary attack vector in Business Email Compromise (BEC), and is responsible for the majority of phishing attacks today. The following steps are used to generate a dataset that measures the effectiveness of similarity digests against embedded content:
- 100 paragraphs (10,000 words) of English text is saved in a Microsoft Word document
- 10 random images of size 500 x 500 and 10 random images of size 1200 x 1200 are generated
- 10 of the random images (5 of size 500 x 500 and 5 of size 1200 x 1200) are embedded at random places in the Word document
- The evaluation algorithm compares the Word document against all 20 images to measure similarity
Similarity Digests
TLSH
py-tlsh is the official Python library for TLSH, and provides extensions for the original TLSH library released by TrendMicro.
TLSH digest for a file is computed as follows, returning a 35-byte digest:
import tlsh
def tlsh_digest(file):
return tlsh.hash(open(file, 'rb'))Two TLSH digests hash1 and hash2 are compared by:
def tlsh_distance(hash1, hash2):
return tlsh.diff(hash1, hash2)tlsh.diff measures the distance between two digests, with 0 indicating an exact match, and higher values indicating lower similarity between the digests.
ssdeep
The ssdeep Python library provides a wrapper around the original ssdeep implementation by Jesse Kornblum.
The ssdeep digest for a file is computed a follows:
import ssdeep
def ssdeep_digest(file):
return ssdeep.hash(open(file, 'rb'))Two ssdeep digests hash1 and hash2 are compared by:
def ssdeep_distance(hash1, hash2):
return 100 - ssdeep.compare(hash1, hash2)
ssdeep.compare emits a similarity score from 0 (no match) and 100, and we convert this into a proxy for distance by subtracting the score from 100.
sdhash
The official sdhash library is written in C++, and uses SWIG to create Python extensions. For these tests, the Golang sdhash package is used since it is easier to use across platforms, and easier for readers to reproduce.
The sdhash digest for a file is computed as follows, generating a digest that is around 2.6% of the input data size.
import "github.com/eciavatta/sdhash"
factory := sdhash.CreateSdbfFromFilename(filePath)
hash := factory.Compute()Two sdhash digests hash1 and hash2 are compared by
distance := 100 - hash1.Compare(hash2)The Compare(...) method returns a similarity score from 0 to 100. A score of 0 means that the two files are very different, a score of 100 means that the two files are equal. Same as ssdeep, this score is converted into a distance measure by subtracting from 100.
Pairwise Distances
The file dataset is divided into the 6 datasets described in the previous section. First, a dictionary of digests is computed for each dataset. This maps each dataset name to an array of (filename, digest) pairs. Here, digest_fn computes the similarity digest.
# Dictionary of dataset name to an array of (filename, digest) pairs
digests = {}
# Iterate over the datasets
for i, obj in enumerate(os.listdir(DATASET_DIR)):
print(f'({i+1}) Computing digests for {obj}')
obj_digests = []
# Iterate over files within a dataset and compute their digests
for file_name in os.listdir(DATASET_DIR/obj):
with open(DATASET_DIR/obj/file_name, 'rb') as f:
contents = f.read()
obj_digests.append((file_name, digest_fn(contents)))
obj_digests = np.array(obj_digests)
obj_digests = obj_digests[obj_digests[:,0].argsort()]
digests[obj] = obj_digests
digests.keys()
# Output: ['paragraphs', 'dwarf_fortress_win_zip', 'dwarf_fortress_win', 'doc_with_images', 'dwarf_fortress_linux', 'dwarf_fortress_linux_zip']Pairwise distances between files can be evaluated across multiple datasets, or within a single dataset. Here, the metric_fn computes the distance between two digests.
from sklearn.metrics.pairwise import pairwise_distances
paragraphs = digests['paragraphs']
df_win = digests['dwarf_fortress_win']
df_win_zip = digests['dwarf_fortress_win_zip']
df_linux = digests['dwarf_fortress_linux']
df_linux_zip = digests['dwarf_fortress_linux_zip']
doc_with_images = digests['doc_with_images']
# Concatenate the datasets we want to evaluate
combined_digests = np.concatenate((df_win, df_linux,))
D = pairwise_distances(combined_digests[:,1], metric=metric_fn)For a list of N files F1… FN, this generates an N x N matrix D, where D[i, j] is a measure of the distance between files Fi and Fj.
Visualizing Similarity
We can get a better intuition for the similarity of files with a dataset or between datasets by visualizing the distance / similarity matrices. The pairwise distance matrix D is normalized so its values fall in the range [0, 1], and the normalized distance matrix is visualized using a colormap. This gives us an intuitive understanding of how intra-dataset file similarity varies with the magnitude and type of modifications.
Visualizing with a colormap also gives an intuitive idea of the statistical distribution of distances, showing how the inter-dataset file similarity varies with the magnitude and type of modifications.
cmap = plt.get_cmap('viridis')
length = len(D)
min_dist = np.min(D)
max_dist = np.max(D)
norm_D = D / np.max(max_dist)
plt.figure(figsize=(10, 6))
plt.imshow(cmap(norm_D))
plt.colorbar()
plt.title('Distance Matrix')
plt.xticks(range(length), file_names, rotation='vertical')
plt.yticks(range(length), file_names)
plt.show()Results and Analysis
This section presents the results of evaluating the intra-dataset and inter-dataset similarities
Dataset 1: Paragraphs (Plain Text Documents)
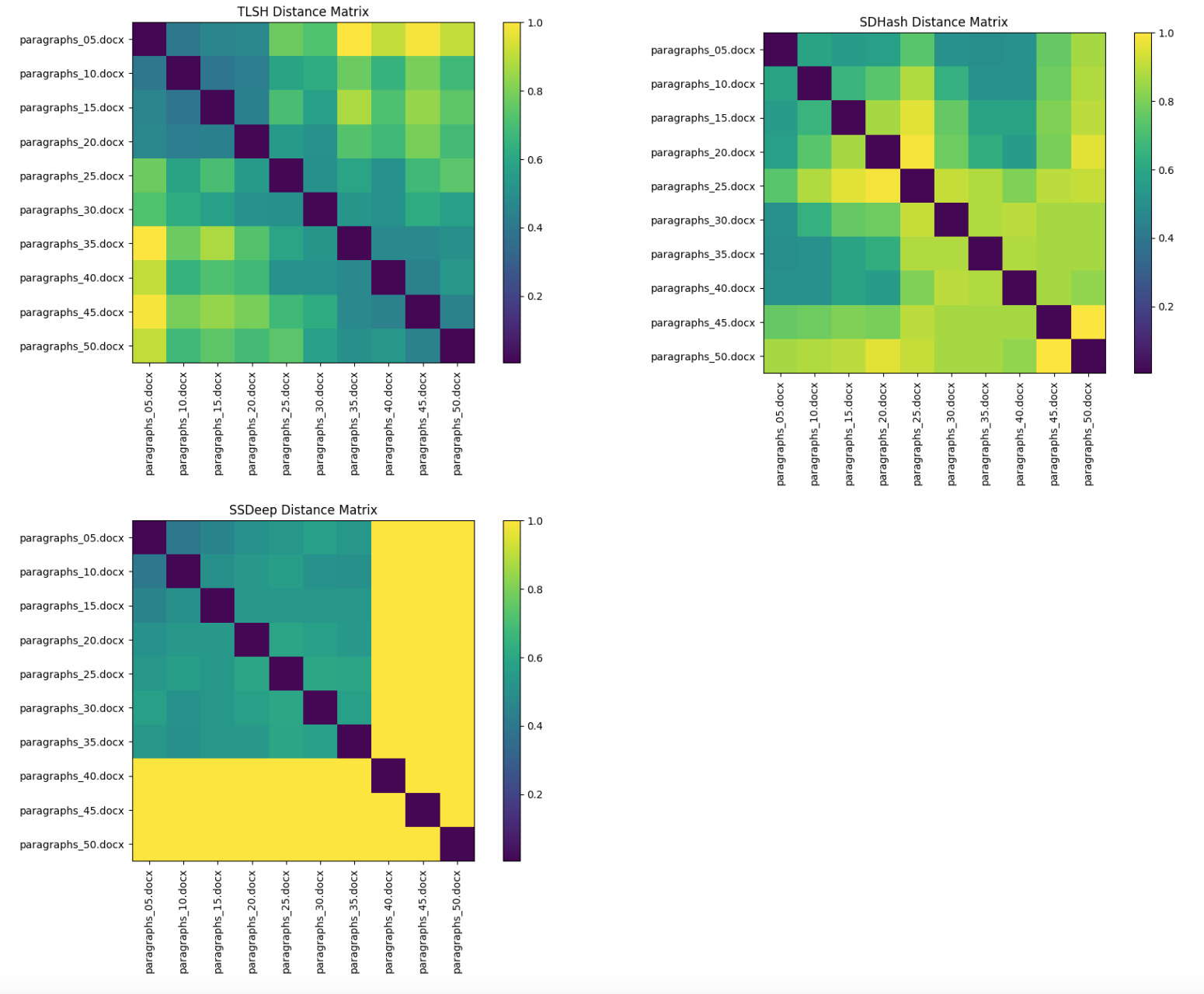
TLSH shows the best performance here, returning low distances (i.e. high similarity) close to the diagonal, and higher distances away from the diagonals. The distances increase gradually with the magnitude of modifications, which is also observed in the histogram distribution of the distances that shows high standard deviation.
SSDeep does not perform very well, with very low variation in distances (reflected in the low standard deviation in the distances histogram) and high distances (low similarity) for larger files. In fact, this is a known weakness of ssdeep: it works only for relatively small objects of similar sizes.
SDHash does not fare any better, with unexpected low similarity scores along the diagonals and high similarity scores when comparing dissimilar small files.
Dataset 2: Dwarf Fortress Windows Executables
The Dwarf Fortress Windows executables are compared against each other for similarity.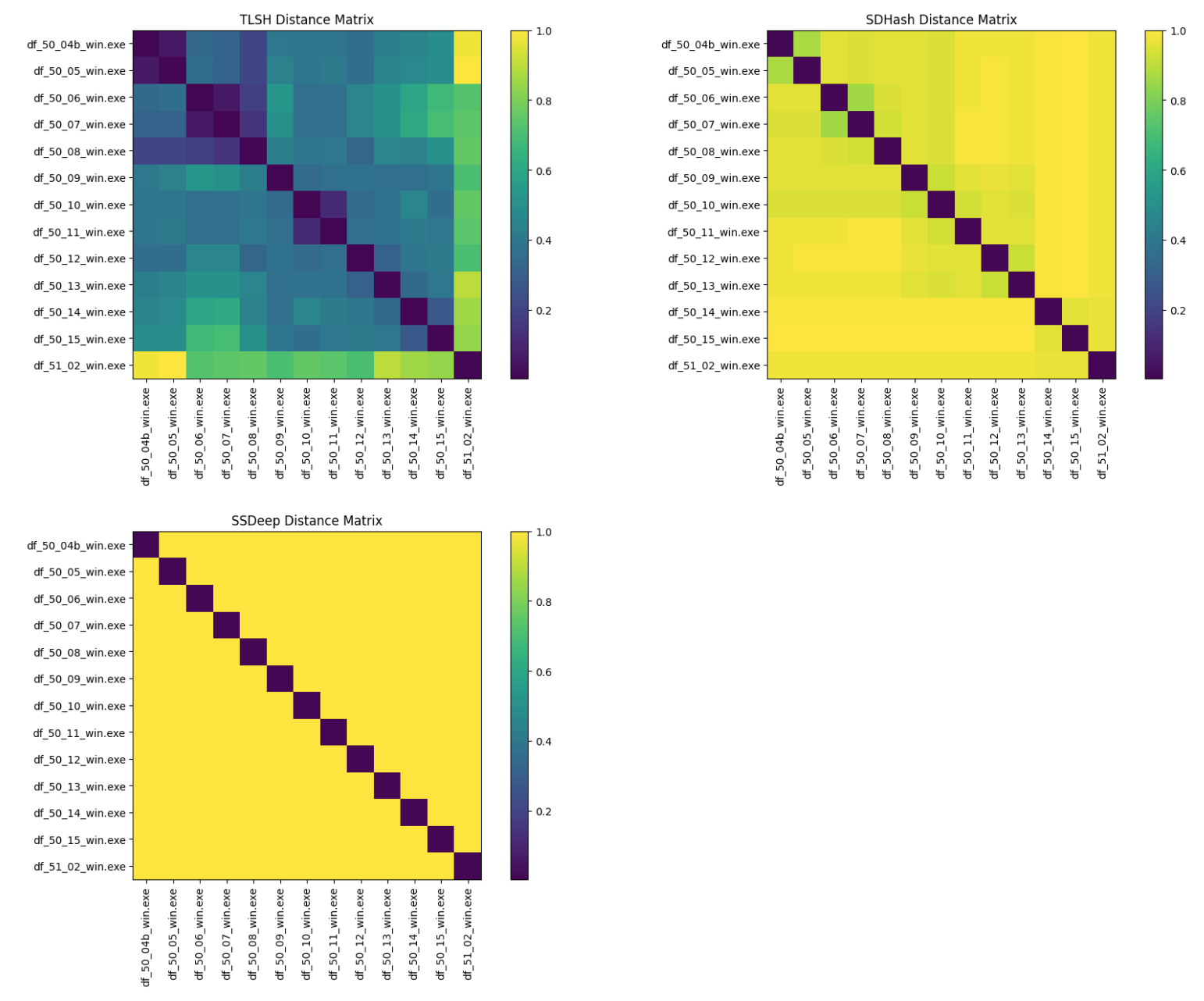
TLSH again performs the best among the three digest algorithms. From the distance heat map, it’s clear that 50.xx versions are more similar to each other than to the 51.xx version, as expected. The Dwarf Fortress Windows executables are around 22 MB in size, and SSDeep struggles with larger files, as expected. SDHash only performs slightly better, showing some similarity along the diagonals, but is not as nuanced and detailed as TLSH.
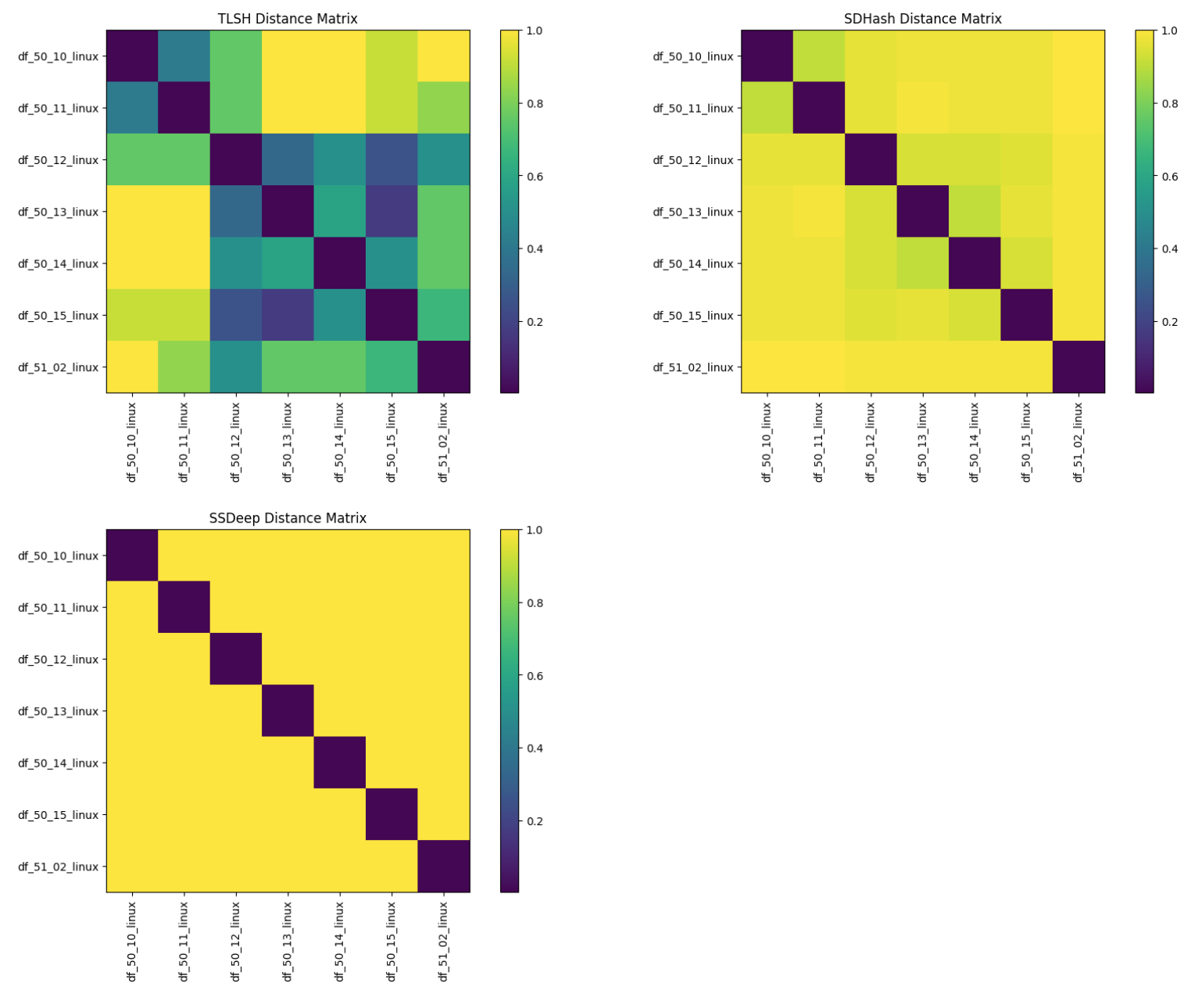
For completeness, here are the distance matrices for Dwarf Fortress’s 7 Linux executable versions. Results are similar to the Windows versions.
Dataset 3: Compressed Files
The 13 Windows versions of Dwarf Fortress executables are compared against the 13 compressed bundles they were packaged in.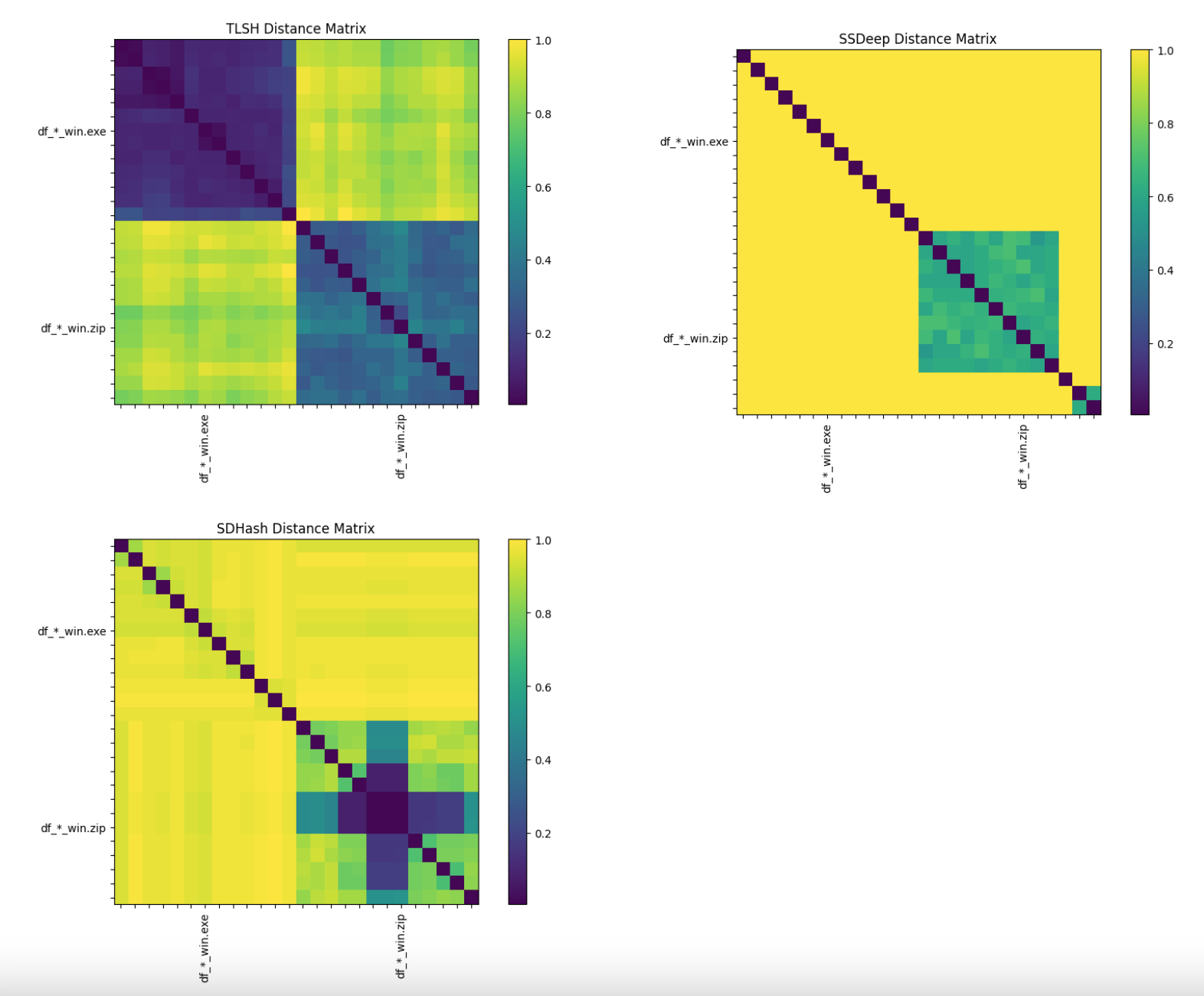
The top-right and bottom-left quadrants of the distance matrices show the similarity scores between the executables and the compressed files they were bundled in. They show that all 3 similarity digests fail to detect any meaningful similarity between them. At best, these two quadrants of the heatmaps are random noise.
The bottom-right quadrant shows the similarity between different versions of the compressed game bundles. Interestingly, TLSH struggles the most here, generating similarity scores that are essentially random, whereas sdhash especially seems to have extracted some degree of similarity between the files.
Dataset 4: Embedded Files
As a reminder, there are 20 JPEG images, and the .docx file has half of the images embedded in it. A security analyst would expect similarity to get detected between the embedded images and the Word document.
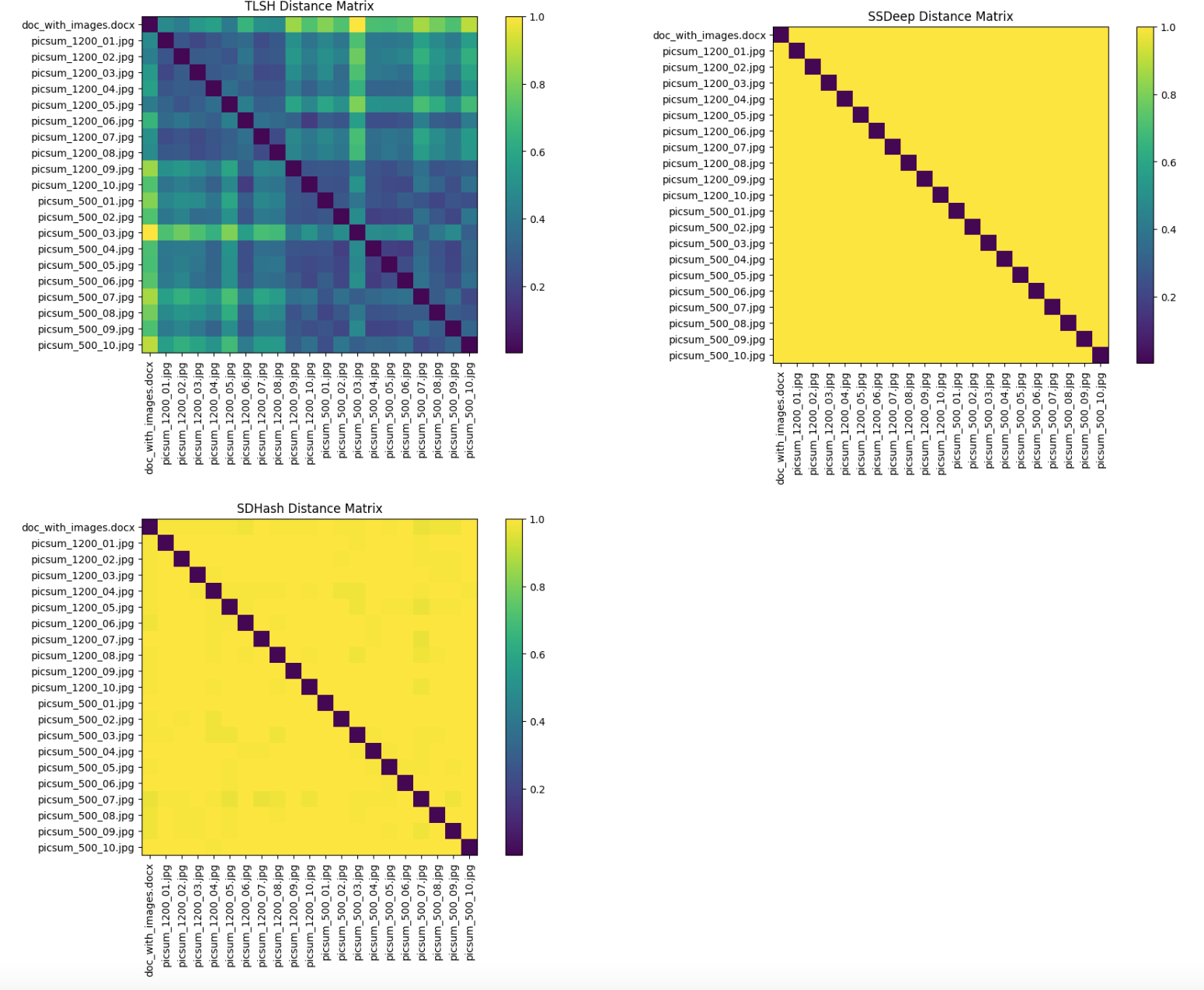
None of the three similarity digest algorithms manage to detect any meaningful similarity between the document with the embedded images and the images themselves. TLSH shows some variation, but closer inspection shows that it emits the same distribution of distances for embedded and non-embedded images.
Conclusion
- TLSH is overall the best performer in terms of similarity detection in regular files like plaintext and executables. However, it doesn’t perform well when detecting embedded files or similarity between compressed files.
- SDHash doesn’t detect similarity between executables and plaintext files as well as TLSH, but it performs better than TLSH on compressed files
- SSDeep’s major flaw with only working on small files has affected the results in these experiments, where it shows significantly worse performance than TLSH and SDHash.
Like any robust system, security practitioners are best served by employing hybrid approaches, using multiple types of similarity digests in order to detect a diverse range of similar files. Between TLSH and SDHash, most file modification types are covered, but the compressed files and embedded files experiments show that there are still gaps that can be used by threat actors to evade detection to a significant extent.
Opinions expressed by DZone contributors are their own.
Comments