Simple Text Summarizer Using Extractive Method
In this article, we will build a text summarizer with an extracted method that is super easy to build and very reliable when it comes to results.
Join the DZone community and get the full member experience.
Join For Free
Have you seen applications like inshorts that converts the articles or news into 60 words summary. Yes, that’s what we are going to build today. In this article, we will build a text summarizer with extracted method that is super easy to build and very reliable when it comes to results. Don't worry, I will also explain what this extracted method is?
You may found many articles about text summarizers but what makes this article unique is the short and beginners friendly high-level description of the code snippets.
So, Text summarization can be done in two ways:
- Extractive method — Selecting the n numbers of most important sentences from the article that most probably convey the message of the article. This approach is very easy to implement and beginners friendly. That's the main reason of choosing this method for this tutorial.
- Abstractive method — This method uses concepts of deep learning like encoder-decoder architecture, LSTM(Long Short Term Memory) networks that are very difficult for beginners to understand. This method generates the whole new summary of the article and contains sentences that are not even present in the original article. This method may lead to the creation of sentences that don't have any meaning at all.
Now, as we are clear about why we have chosen the extracted method, Lets directly jump to the coding section.
Prerequisites
I assume that you are familiar with python and already have installed the python 3 in your systems. I have used jupyter notebook for this tutorial. You can use the IDE of your like.
Installing Required Libraries
For this project, you need to have the following packages installed in your python. If they are not installed, you can simply usepip install PackageName . The scraping part is optional, you can also skip that and use any local text file for which you want a summary.
- bs4 — for BeautifulSoup that is used for parsing Html page.
- lxml — it is the package that is used to process Html and XML with python.
- nltk — for performing natural language processing tasks.
- urllib — for requesting a webpage.
Let's Start Coding
First, we have to import all the libraries that we will use. bs4 and urllib will be used for scraping of the article. re(regular expression) is used for removing unwanted text from the article. The 4th line is used to install the nltk(natural language toolkit) package that is the most important package for this tutorial. After that, we have downloaded some of the data that is required for the text processing like punkt (used for sentence tokenizing) and stopwords(words like is,the,of that does not contribute).
xxxxxxxxxx
import bs4
import urllib.request as url
import re
#!pip3 install nltk
import nltk
nltk.download('punkt')
nltk.download('stopwords')
from nltk import sent_tokenize
from nltk.corpus import stopwords
from nltk import word_tokenize
stop_word = stopwords.words('english')
import string
Here, I have simply taken the URL of the article from the user itself.
xxxxxxxxxx
url_name = input("Enter url of the text you want to summerize:")
In this snippet of code, we have requested the page source with urllib and then parse that page with BeautifulSoup to find the paragraph tags and added the text to the articlevariable.
xxxxxxxxxx
web = url.urlopen(url_name)
page = bs4.BeautifulSoup(web,'html.parser')
elements = page.find_all('p')
article = ''
for i in elements:
article+= (i.text)
article
Now, we remove all the special characters from that string variable articlethat contains the whole article that is to be summarized. For this, we have simply used inbuilt replacefunction and also used a regular expression (re) to remove numbers.
xxxxxxxxxx
processed = article.replace(r'^\s+|\s+?$','')
processed = processed.replace('\n',' ')
processed = processed.replace("\\",'')
processed = processed.replace(",",'')
processed = processed.replace('"','')
processed = re.sub(r'\[[0-9]*\]','',processed)
processed
Here, we have simply used the sent_tokenizefunction of nltk to make the list that contains sentences of the article at each index.
xxxxxxxxxx
sentences = sent_tokenize(processed)
After that, we convert the characters of article to lowercase. Then we loop through every word of the article and check if it is not stopword or any punctuation(we have already removed the punctuations but we still use this just in case). And if the word is none of them we just added that word into the dictionary and then further count the frequency of that word.
In the screenshot, you can see the dictionary containing every word with its count in the article(higher the frequency of the word, more important it is). Now you know why we have removed stopwords like of the for otherwise, they will come on top.
xxxxxxxxxx
frequency = {}
processed1 = processed.lower()
for word in word_tokenize(processed1):
if word not in stop_word and word not in string.punctuation:
if word not in frequency.keys():
frequency[word]=1
else:
frequency[word]+=1
frequency

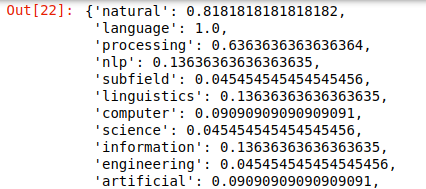
Here, we have calculated the importance of every word in the dictionary by simply dividing the frequency of every word with the maximum frequency among them. In the screenshot, you can clearly see that importance of word languagecomes on top as it has the max frequency that is 22.
xxxxxxxxxx
max_fre = max(frequency.values())
for word in frequency.keys():
frequency[word]=(frequency[word]/max_fre)
frequency
After doing that, now we have to calculate the importance of every sentence of the article. And for doing this, we iterate through every sentence of the article, then for every word in the sentence added the individual score or importance of the word to give the final score of that particular sentence.
In the screenshot, you can clearly see that every sentence now has some score that represents how important that sentence is.
xxxxxxxxxx
sentence_score = {}
for sent in sentences:
for word in word_tokenize(sent):
if word in frequency.keys():
if len(sent.split(' '))<30:
if sent not in sentence_score.keys():
sentence_score[sent] = frequency[word]
else:
sentence_score[sent]+=frequency[word]
sentence_score

In the end, We have used heapq to find the 4 sentences with the highest scores. You can choose any number of sentences you want. Then simply joined the list of selected sentences to form a single string of summary.
The final output summary for the Natural Language Processing article can be seen in the screenshot attached.
xxxxxxxxxx
import heapq
summary = heapq.nlargest(4,sentence_score,key = sentence_score.get)
summary = ' '.join(summary)
final = "SUMMARY:- \n " +summarytextfinal = 'TEXT:- '+processed
textfinal = textfinal.encode('ascii','ignore')
textfinal = str(textfinal)
final


The extracted summary may be not up to the mark but it is capable enough of conveying the main idea of the given article. Also, it is more reliable as it only outputs the selected number of sentences from the article itself rather than generating the output of its own.
I will also try to make the tutorial for the abstractive method, but that will be a great challenge for me to explain.
Thank you for your time, and I hope you like this tutorial.
Opinions expressed by DZone contributors are their own.
Comments