SmartXML: An Alternative to XPath for Complex XML Files
We'll discuss SmartXML, an XPath alternative for parsing complex XML files, converting them to SQL, and loading the results into a database seamlessly.
Join the DZone community and get the full member experience.
Join For FreeXML is one of the most widely used data formats, which in popularity can compete only with JSON. Still, very often, this format is used as an intermediate representation of data that needs to be transferred between two information systems. And like any intermediate representation the final storage point of XML is a database.
Usually, XPath is used to parse XML because it represents a set of functions that allows you to extract data from an XML tree. However, not all XML files are formed correctly, which creates great difficulties when using XPath.
Typical Problems When Working With XPath
- Differences in node naming. You may have an array of documents with a similar logical structure, but they may have differences in the way node names are spelled.
- Missing nodes. If bad XML generators are used on the server side, they may skip some nesting levels for some of the data in the resulting XML.
- Object or array? XPath does not allow you to explicitly specify whether the contents of a particular node are an object or an array of objects.
- Inability to extend syntax. XPath is just a node traversal tool with no syntax extension capability.
In this article, I will discuss a tool called SmartXML that solves these problems and allows you to upload complex XML documents to a database.
Project Structure
SmartXML uses an intermediate representation when processing data — SmartDOM. Unlike traditional DOM, this structure controls the level of element hierarchy and can complete its nodes.
SmartDOM consists of the declarative description itself and sets of rules for its transformation.
Three Examples of Documents With a Divergent Structure
Example 1
The document has a relatively correct structure. All sections have correct nesting.
<doc>
<commonInfo>
<supplyNumber>100480</supplyNumber>
<supplyDate>2025-01-20</supplyDate>
</commonInfo>
<lots>
<lot>
<objects>
<object>
<name>apples</name>
<price>3.25</price>
<currency>USD</currency>
</object>
<object>
<name>oranges</name>
<price>3.50</price>
<currency>USD</currency>
</object>
</objects>
</lot>
<lot>
<objects>
<object>
<name>bananas</name>
<price>2.50</price>
<currency>EUR</currency>
</object>
<object>
<name>strawberries</name>
<price>5.00</price>
<currency>USD</currency>
</object>
<object>
<name>grapes</name>
<price>3.75</price>
<currency>USD</currency>
</object>
</objects>
</lot>
</lots>
</doc>Example 2
The nesting of sections is broken. The object does not have a parent.
<doc>
<commonInfo>
<supplyNumber>100593</supplyNumber>
<date>2025-01-21</date>
</commonInfo>
<lots>
<lot>
<object>
<name>raspberry</name>
<price>7.50</price>
<currency>USD</currency>
</object>
</lot>
</lots>
</doc>Example 3
The nesting is correct, but the node names do not match the other sections.
<doc>
<commonInfo>
<supplyNumber>100601</supplyNumber>
<date>2025-01-22</date>
</commonInfo>
<lots>
<lot>
<objects>
<obj>
<name>cherries</name>
<price>3.20</price>
<currency>EUR</currency>
</obj>
<obj>
<name>blueberries</name>
<price>4.50</price>
<currency>USD</currency>
</obj>
<obj>
<name>peaches</name>
<price>2.80</price>
<currency>USD</currency>
</obj>
</objects>
</lot>
</lots>
</doc>As you can see, all three of these documents contain the same data but have different storage structures.
Intermediate Data View
The full structure of the SmartDOM view from data-templates.red:
#[
sample: #[ ; section name
supply_sample: #[ ; subsection name
supply_number: none
supply_date: none
delivery_items: [
item: [
name: none
price: none
currency: none
]
]
]
]
]Project Setup
Create a project and set up a mapping between SmartDOM and XML tree nodes for each XML file.
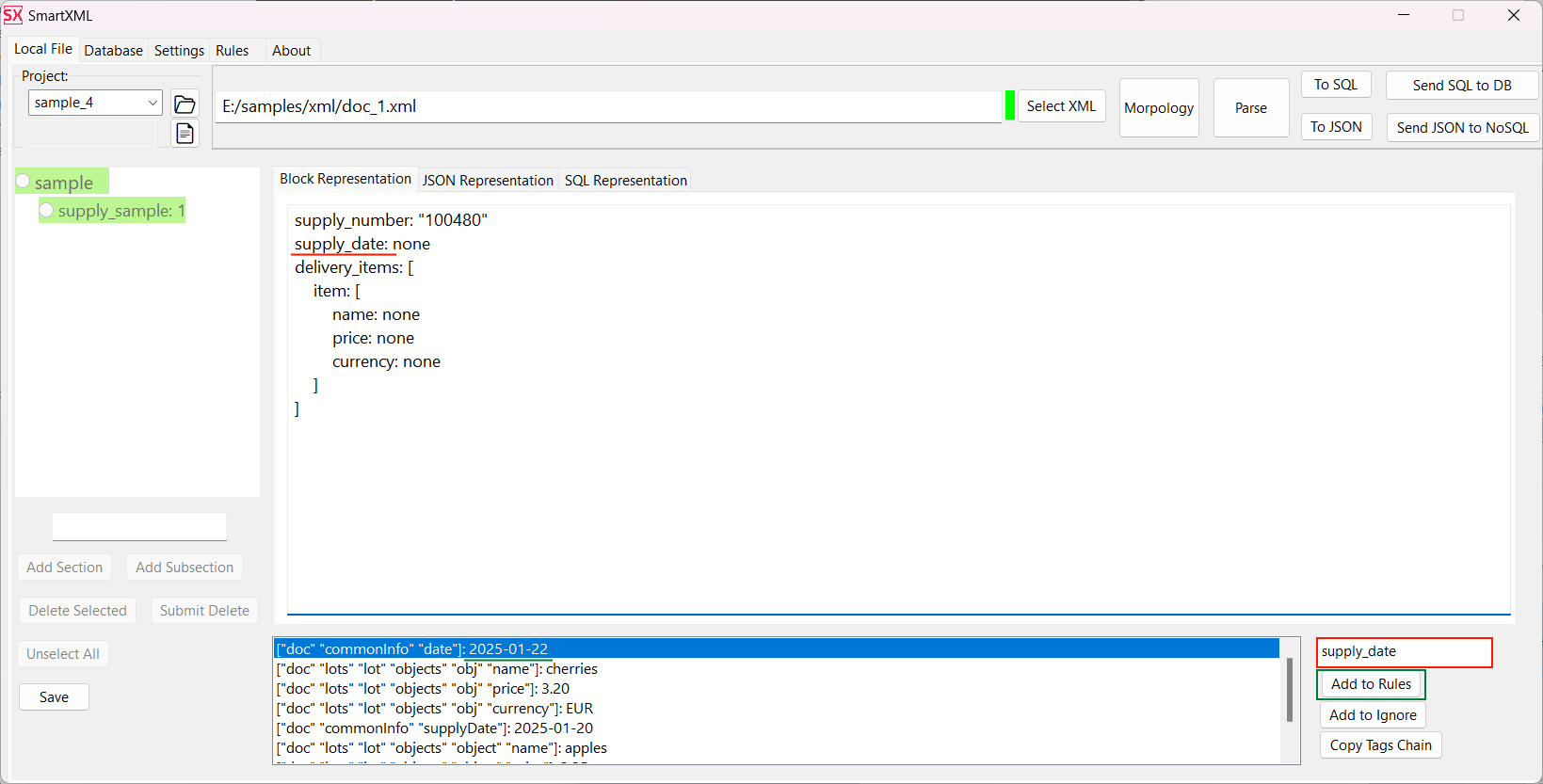
Now, we need to specify how XML nodes are mapped to SmartDOM. This can be done either in the interface on the Rules tab or in the configuration file grow-rules.red, making it look as follows:
sample: [
item: ["object" "obj"]
]For correct linking of tables, we also need to specify the name of the tag from the root element, which should be passed to the descendant nodes. Without this, it will be impossible to link two tables.
Since we have a unique supply_number, it can be used as a similar key.
To do this, let's add it to the injection-rules.red rule:
sample: [
inject-tag-to-every-children: [supply_number]
enumerate-nodes: []
injection-tag-and-recipients: []
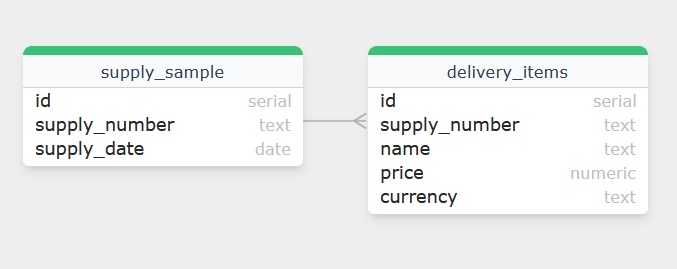
]Now, it remains to create the necessary tables in the database and insert there the results of processing XML files:
PRAGMA foreign_keys = ON;
CREATE TABLE supply_sample (
id INTEGER PRIMARY KEY AUTOINCREMENT,
supply_number TEXT NOT NULL UNIQUE,
supply_date TEXT NOT NULL
);
CREATE TABLE delivery_items (
id INTEGER PRIMARY KEY AUTOINCREMENT,
supply_number TEXT NOT NULL,
name TEXT NOT NULL,
price REAL NOT NULL,
currency TEXT NOT NULL,
FOREIGN KEY (supply_number) REFERENCES supply_sample(supply_number)
);
Result
The result of converting three XML files to SQL:
INSERT INTO supply_sample ("supply_number", "supply_date")
VALUES ('100480', '2025-01-20');
INSERT INTO delivery_items ("supply_number", "name", "price", "currency")
VALUES ('100480', 'apples', '3.25', 'USD'),
('100480', 'oranges', '3.50', 'USD'),
('100480', 'bananas', '2.50', 'EUR'),
('100480', 'strawberries', '5.00', 'USD'),
('100480', 'grapes', '3.75', 'USD');
--
INSERT INTO supply_sample ("supply_number", "supply_date")
VALUES ('100593', '2025-01-21');
INSERT INTO delivery_items ("supply_number", "name", "price", "currency")
VALUES ('100593', 'raspberry', '7.50', 'USD');
--
INSERT INTO supply_sample ("supply_number", "supply_date")
VALUES ('100601', '2025-01-22');
INSERT INTO delivery_items ("supply_number", "name", "price", "currency")
VALUES ('100601', 'cherries', '3.20', 'EUR'),
('100601', 'blueberries', '4.50', 'USD'),
('100601', 'peaches', '2.80', 'USD');This is what the result looks like in tabular form:
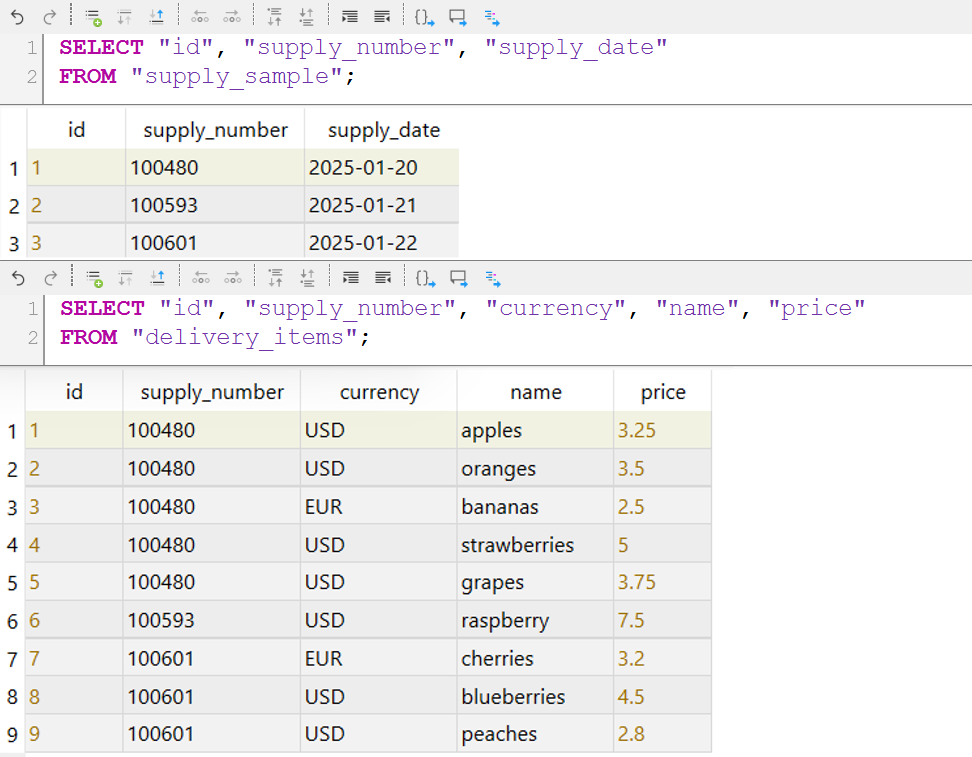
Conclusion
So, we have demonstrated how you can parse and upload to a database quite complex XML files without writing program code. This solution can be useful for system analysts, as well as other people who often work with XML.
In the case of parsing using popular programming languages such as Python, we would have to process each separate file with a separate script, which would require more code and time.
You can learn more about the SmartXML project structure in the official documentation.
Opinions expressed by DZone contributors are their own.
Comments