Software Engineers Need to Know DevOps Too, and That Starts with CI/CD
In this world of cross-functional teams and microservice architecture, DevOps skills become increasingly important. Learn about continuous integration, continuous delivery, continuous deployment, and more.
Join the DZone community and get the full member experience.
Join For FreeDevOps is hot right now. It seems like every software engineering job posting requires DevOps experience and expertise regardless of the actual job title.
When a tech company breaks up its monolith into microservices, each of its engineering teams now owns their portion of the application from start to finish. Software engineers no longer just build the application; they also own repo maintenance, set up continuous integration, configure build pipelines, and deploy their application.
In this world of cross-functional teams and microservice architecture, DevOps skills become increasingly important, and that starts with understanding CI/CD (continuous integration, continuous delivery, and continuous deployment).
In this article we’ll talk about best practices for CI/CD and how platforms like Armory can help manage some of the complexity involved.
Continuous Integration (CI)
Continuous integration (CI) is the “practice of automating the integration of code changes from multiple contributors into a single software project.”
As multiple developers are merging code into the master branch daily, it’s important to have automated checks in place to ensure that the code is always in a good working state. This means that code formatters, code linters, and unit tests should be run prior to merging new code. Rather than relying on developers to remember to use these tools locally, CI pipelines help automate running each required job, preventing bad code from being merged into the master branch.
Good CI pipelines should be fast. That means running pipeline jobs in parallel when possible and having a fast test suite.
Good CI pipelines should also be reliable. If the build is broken, engineers should work to fix it immediately, as a build failure would block all open merge requests from being merged. If a test is flaky, it should be temporarily disabled and fixed as soon as possible.
The app should be built once near the beginning of the CI pipeline, after any formatters, linters, and unit tests are run. This way, the build artifact is ready to be used anywhere in subsequent stages of the pipeline. The build artifact can then be deployed in a containerized environment and used as a review app for code reviewers to quickly validate changes when needed.
When CI pipelines are successfully set up for a code repo, developers can commit to the master branch daily (or even several times per day). No more long-running feature branches that live for months waiting for the day that they can finally be merged!
Following these CI practices helps keep everything in the master branch clean and in a deployable state at all times, which leads us to the second half of the CI/CD acronym.
Continuous Delivery and Continuous Deployment (CD)
As a brief aside, let’s talk about the differences between “continuous delivery” and “continuous deployment.” Continuous delivery is a natural result of generating a build artifact as part of continuous integration. This build artifact is a working copy of the app that can be deployed to an environment. That means, you’re ready to deploy to production anytime! As an engineering organization, you can decide whether to deploy daily, weekly, every two weeks, and so on. In continuous delivery, while you’re prepared to deploy your app at any moment, a human still needs to kick off the process to start the deployment.
Continuous deployment, however, goes a step further than continuous delivery in that every change that gets merged into the master branch will immediately begin the deployment process without any further human interaction. This is exciting because developers can see their code in production just minutes after they’ve merged it! (Assuming, of course, that the deployment isn’t blocked by any failing automated checks which would prevent the new build from being released into the production environment.)
Whether your organization chooses continuous delivery or continuous deployment, the intent of both practices is the same: deliver value to your customers as quickly and as frequently as possible. No more big quarterly releases! This is what being agile is all about.
One of the most important things to get right with continuous delivery is that the app should be able to be deployed with the click of a single button. In other words, the deployment process should be automated. If this practice isn’t followed, and there are multiple complicated steps in the deployment process that must be carried out by a human, the deployment process becomes more prone to error. After all, we are human, and humans make mistakes.
Another key principle of both continuous delivery and continuous deployment is that you should use multiple levels of environments in which the app can run. For instance, you might have a development environment, a staging environment, and a production environment. The build artifact can then be promoted from one environment to the next during the deployment process. The infrastructure in these various environments should be as similar as possible so that you don’t run into major surprises once the app gets into production.
Deployment Strategies
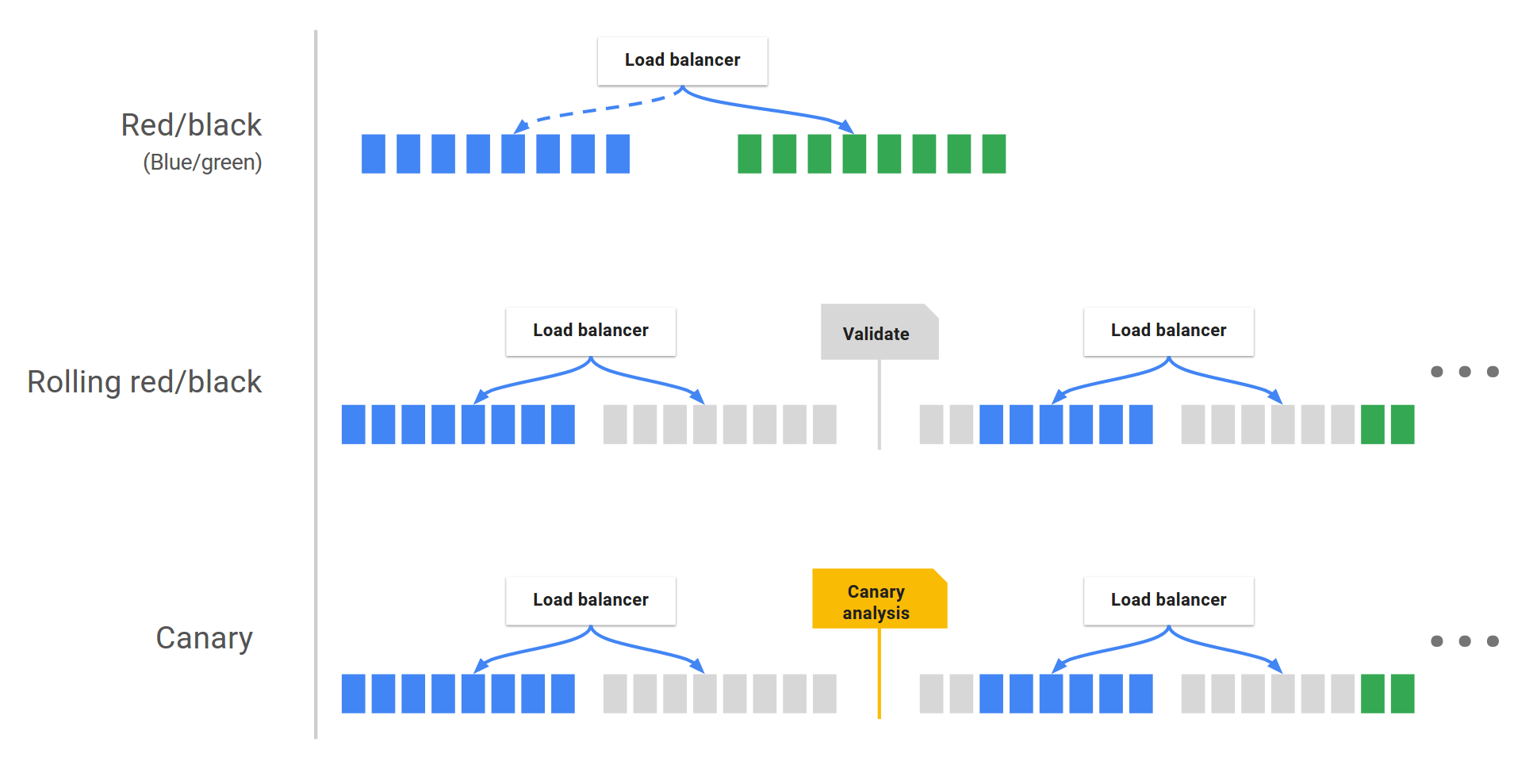
Deployment strategies can vary, but some commonly used techniques are canary deployments, blue/green deployments, and rolling blue/green deployments.
In a canary deployment, you first release the new version of your app to a small subset of users. Once you are comfortable that the changes work properly for those users, you release the changes to the rest of your users as well. This is considered a cautious way to release code as you don’t initially apply the changes for everyone all at once.
In a blue/green deployment, you use two production-grade environments. One environment is actively used in production and contains the current version of the app. The second environment is on standby and has no traffic routed to it. You deploy the new version of your app to the standby environment and then route all traffic to this environment, which makes it the new production environment. The old production environment then no longer receives traffic and becomes the standby environment. This makes it very easy both to deploy a new release and also to rollback a release when needed, because both processes are as simple as redirecting where the user traffic goes.
A rolling blue/green deployment can be used when you have multiple instances of your application all running in the same environment. For example, if you have six nodes used in production, swap out the first node with another node that is running the new version of the application. So, now you have five nodes running the old version of the app and one node running the new version of the app. Then you do it again so that the ratio becomes four old and two new. After four more node replacements, now all six of your nodes are running the new version of the application.
The rolling nature of the deployment is both a pro and a con. The deployment is less risky as you don’t deploy everything at once, but it also takes more time to complete the full release since it’s done one node at a time.
How Tools Can Help with CI/CD
Now that we understand best practices for CI/CD, what tools can we use to help us? For CI, there are many good open source options like Travis CI or CircleCI. You can even use the built-in features of GitHub (with GitHub Actions) or GitLab (with GitLab CI). Most of these tools specialize in the CI part of CI/CD but also include some features for CD. With these CI tools, you can create pipelines that take care of running your linters and tests on every new merge request.
When it comes to CD, one of the most popular open source tools that helps automate deployments is Spinnaker. Spinnaker was originally developed internally by Netflix before it was released to the broader developer community. One of the best things about Spinnaker is its flexibility in supporting just about every cloud provider from AWS to Azure to GCP. Spinnaker can be integrated with your CI tool of choice and can deploy your app using your chosen deployment strategy. (I already mentioned that it’s flexible, right?)
An example pipeline for a canary deployment using Spinnaker might look a little something like this:
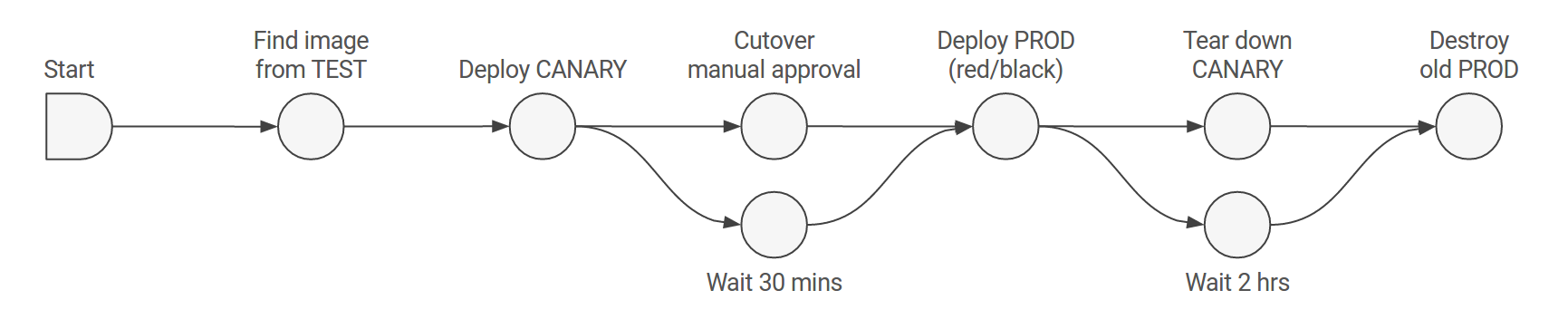
In this workflow, we see the build artifact deployed to a small cluster of server groups for the initial canary deployment. After the functionality changes in the canary deployment have been manually reviewed and approved, a blue/green deployment is done (or red/black deployment as Netflix calls it) by deploying a new prod cluster and using the load balancer to direct traffic to this new group. The canary cluster is then torn down, and — after everyone is comfortable that the new prod cluster is working well — the old prod cluster is destroyed, too.
Armory is a platform that takes this idea one step further by providing an enterprise-grade offering of Spinnaker for better visibility, developer empowerment, and resilience. Armory’s dashboards, logging, and live metrics help give developers more visibility into their app deployments. With much of the complexity abstracted away into a nice GUI, deployments and rollbacks can be executed with the click of a button. This enables even those developers without much DevOps experience to own their app from start to finish. And just to give you an added measure of confidence, Armory’s Policy Engine allows you to configure guardrails to ensure that every deployment follows your company’s best practices and agreed-upon rules.
Conclusion
So, what have we learned? First, developers need to be acquainted with CI/CD best practices. Second, engineering organizations need to provide their developers with the right tools to help increase productivity and reduce errors. As we’ve seen, one of the best tools used for CD is Spinnaker, now enhanced by Armory. By working together to implement these DevOps principles, engineering teams will have greater confidence in their code and will be enabled to deliver value to their customers faster.
Published at DZone with permission of Tyler Hawkins. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments