Solving the Cold Start Problem in Edge AI: A Guide to Data-Saving Learning
Update edge AI models efficiently using Mix Up and contribution sampling to overcome domain shift with minimal data, ensuring continuous evolution without forgetting.
Join the DZone community and get the full member experience.
Join For FreeWe have all seen the demo: a computer vision model achieves 99% accuracy on a test dataset. Then, we deploy it to an edge device — a drone, a security camera, or an industrial robot — and performance crashes.
The problem is domain shift. The lighting is different, the camera angle is skewed, or the background noise has changed. In traditional MLOps, the solution is to collect thousands of new images from the edge device, label them manually, and retrain the model from scratch.
In the real world, however, we rarely have the luxury of "big data" at the edge. We have "small data."
Based on recent research into high-stakes environments (such as aerial surveillance and remote sensing), this article explores data-saving learning. We will look at two specific techniques — Practical Domain Adaptation and Contribution-Based Incremental Learning — that allow engineers to maintain high model performance with only a fraction of the data and training time usually required.
The Challenge: The Data Dependency Trap
Deep learning models are notoriously data-hungry. When a deployed model encounters a new environment (the target domain) that differs from its training environment (the source domain), it often fails to generalize.
Standard approaches to fix this include:
- Fine-tuning: Requires a significant amount of labeled data to prevent overfitting.
- Unsupervised domain adaptation: Often fails in real-world scenarios where class distributions are unbalanced (e.g., seeing 100 cars but only 1 truck).
To build a robust "self-updating" AI pipeline, we need an architecture that solves two specific problems:
- Early performance: Getting the model to work immediately upon deployment with minimal examples.
- Continuous evolution: Updating the model over time without catastrophic forgetting (erasing old knowledge).
Solution 1: Practical Domain Adaptation (DA)
The research suggests that standard unsupervised DA is insufficient for high-stakes edge deployments. Instead, a semi-supervised approach utilizing data augmentation and parameter regularization yields better results.
The Algorithm: MixUp and Regularization
To handle the scarcity of data in the new environment, we can use a technique called MixUp. This involves taking pairs of images (one from the source domain and one from the target domain) and mathematically blending them. This forces the model to learn linear relationships between classes and domains, making it more robust to noise.
Simultaneously, we apply parameter regularization. This constrains the model weights during retraining so they do not drift too far from the original pre-trained knowledge base.
Python Pseudocode for Mix Up Implementation:
import torch
import numpy as np
def mixup_data(x, y, alpha=1.0):
'''
Returns mixed inputs, pairs of targets, and lambda
'''
if alpha > 0:
lam = np.random.beta(alpha, alpha)
else:
lam = 1
batch_size = x.size()[0]
index = torch.randperm(batch_size).cuda()
mixed_x = lam * x + (1 - lam) * x[index, :]
y_a, y_b = y, y[index]
return mixed_x, y_a, y_b, lam
def mixup_criterion(criterion, pred, y_a, y_b, lam):
return lam * criterion(pred, y_a) + (1 - lam) * criterion(pred, y_b)
# In your training loop:
# inputs, targets_a, targets_b, lam = mixup_data(inputs, targets)
# outputs = model(inputs)
# loss = mixup_criterion(criterion, outputs, targets_a, targets_b, lam)Results: By using this approach, deployments with highly unbalanced classes (e.g., missing data for certain object types) can achieve accuracy comparable to models trained on full datasets, even when the new target dataset is 1/100th the size of the original.
Solution 2: Incremental Learning Without Forgetting
Once the model is running, it encounters new objects over time. We want to teach the model these new classes (incremental learning) without it forgetting the old ones (catastrophic forgetting).
A common technique is iCaRL (Incremental Classifier and Representation Learning), which keeps a small buffer of old data to replay during training. However, standard iCaRL uses random sampling, which is dangerous when real-world data is biased. If you randomly sample a dataset that is 90% "sky" and 10% "drone," you might accidentally drop all the "drone" examples from your memory buffer.
The Fix: Learning Contribution Sampling
Instead of random sampling, we use contribution sampling. We analyze the feature space of the old data and select specific samples that define the shape of the class distribution.
- Feature extraction: Run old data through the model to obtain feature vectors.
- Distribution mapping: Calculate the mean and spread of these features.
- Selection: Select the specific images that, when combined, best reconstruct the original feature mean. These are the high contributors.
This ensures that even if we keep only 20% of the historical data, we retain the mathematical essence of the previous knowledge.
Visualizing the Pipeline
Here is what the data-saving MLOps pipeline looks like. It differs from standard pipelines by introducing a specialized sampling and regularization layer.
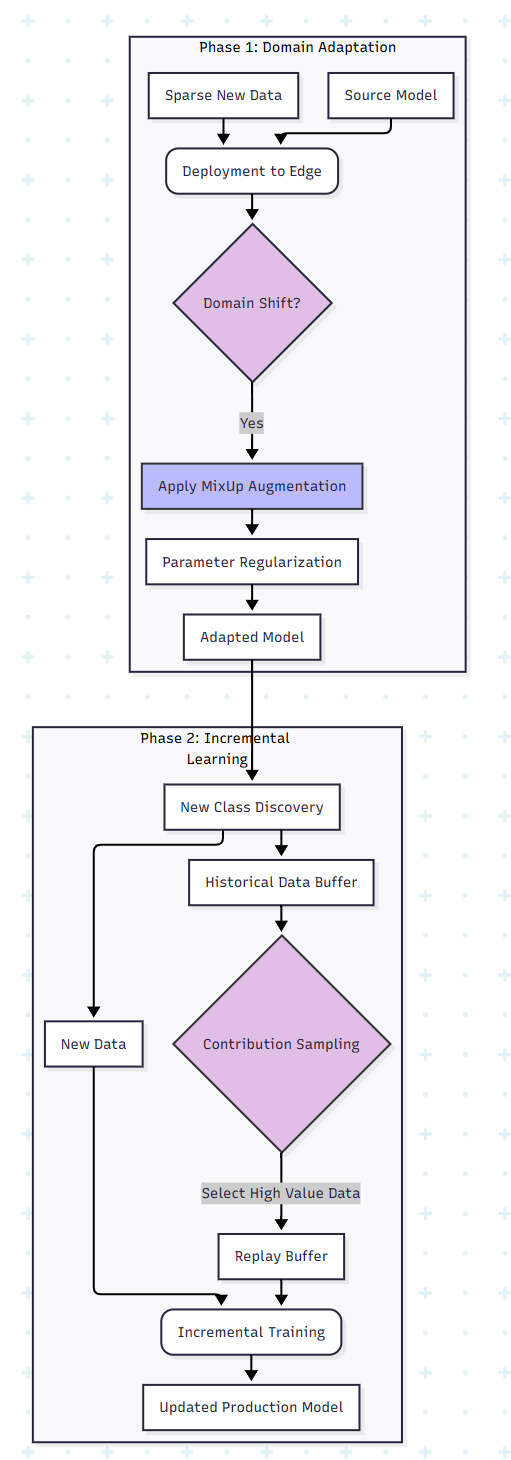
Benchmarks and ROI
Implementing this architecture in real-world scenarios has demonstrated significant efficiency gains compared to "retrain-from-scratch" or standard transfer learning methods:
- Training time: Reduced to one-third of the original time because the model converges faster using high-contribution samples.
- Data storage: High accuracy maintained while discarding 80% of historical raw data, significantly reducing storage costs at the edge.
- Accuracy: In scenarios with fewer than five samples per class, this method improved classification accuracy by 12–27% over standard baseline learning.
Conclusion
The future of AI isn’t just about bigger models; it’s about smarter lifecycles. For organizations deploying AI to dynamic environments — whether manufacturing floors, autonomous vehicles, or remote sensing — relying on massive labeled datasets is a bottleneck.
By adopting data-saving learning — specifically through MixUp-enhanced domain adaptation and contribution-based incremental learning — engineers can build systems that adapt to the real world in real time, delivering the promise of DX (Digital Transformation) without the crushing overhead of big data management.
Key Takeaways
- Don’t trust random sampling: When buffering data for future retraining, use feature-based selection to keep only the data that matters.
- Augment aggressively: When target data is scarce, techniques like MixUp bridge the gap better than standard rotation or flipping.
- Regularize: Prevent your model from forgetting its source knowledge by constraining weight updates during the adaptation phase.
Opinions expressed by DZone contributors are their own.
Comments