Sorting Text Files with MapReduce
Join the DZone community and get the full member experience.
Join For Freein my last post i wrote about sorting files in linux. decently large files (in the tens of gb’s) can be sorted fairly quickly using that approach. but what if your files are already in hdfs, or ar hundreds of gb’s in size or larger? in this case it makes sense to use mapreduce and leverage your cluster resources to sort your data in parallel.
mapreduce should be thought of as a ubiquitous sorting tool, since by design it sorts all the map output records (using the map output keys), so that all the records that reach a single reducer are sorted. the diagram below shows the internals of how the shuffle phase works in mapreduce.
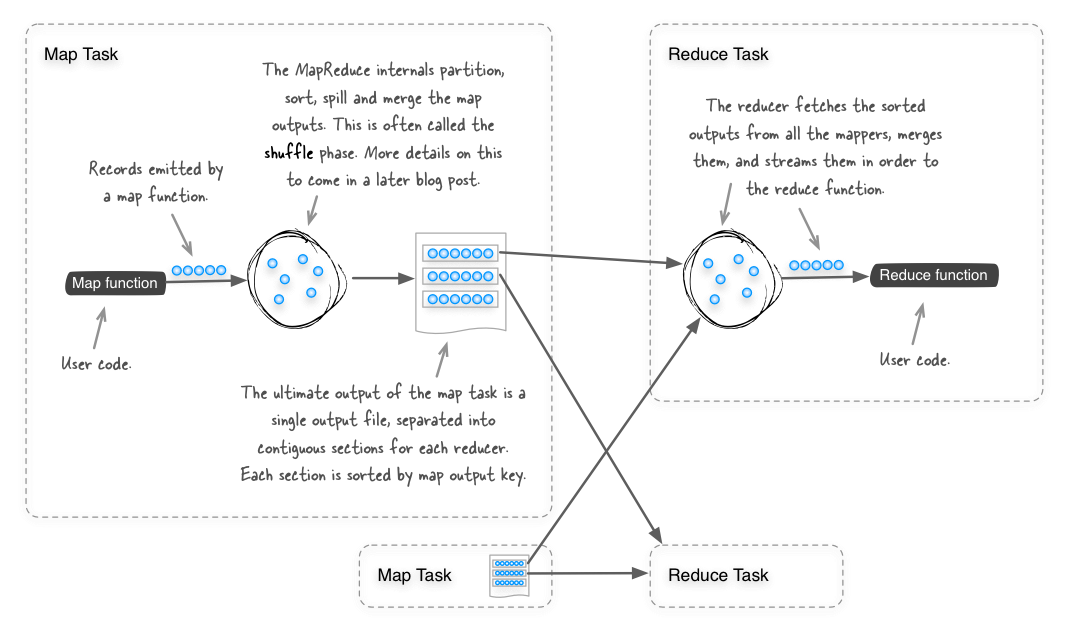
given that mapreduce already performs sorting between the map and reduce phases, then sorting files can be accomplished with an identity function (one where the inputs to the map and reduce phases are emitted directly). this is in fact what the sort example that is bundled with hadoop does. you can look at the how the example code works by examining the org.apache.hadoop.examples.sort class. to use this example code to sort text files in hadoop, you would use it as follows:
shell$ export hadoop_home=/usr/lib/hadoop
shell$ $hadoop_home/bin/hadoop jar $hadoop_home/hadoop-examples.jar sort \
-informat org.apache.hadoop.mapred.keyvaluetextinputformat \
-outformat org.apache.hadoop.mapred.textoutputformat \
-outkey org.apache.hadoop.io.text \
-outvalue org.apache.hadoop.io.text \
/hdfs/path/to/input \
/hdfs/path/to/outputthis works well, but it doesn’t offer some of the features that i commonly rely upon in linux’s sort, such as sorting on a specific column, and case-insensitive sorts.
linux-esque sorting in mapreduce
i’ve started a new github repo called hadoop-utils , where i plan to roll useful helper classes and utilities. the first one is a flexible hadoop sort. the same hadoop example sort can be accomplished with the hadoop-utils sort as follows:
shell$ $hadoop_home/bin/hadoop jar hadoop-utils-<version>-jar-with-dependencies.jar \
com.alexholmes.hadooputils.sort.sort \
/hdfs/path/to/input \
/hdfs/path/to/output
to bring sorting in mapreduce closer to the linux sort, the
--key
and
--field-separator
options can be used to specify one or more columns that should be used for sorting, as well as a custom separator (whitespace is the default). for example, imagine you had a file in hdfs called
/input/300names.txt
which contained first and last names:
shell$ hadoop fs -cat 300names.txt | head -n 5
roy franklin
mario gardner
willis romero
max wilkerson
latoya larsonto sort on the last name you would run:
shell$ $hadoop_home/bin/hadoop jar hadoop-utils-<version>-jar-with-dependencies.jar \
com.alexholmes.hadooputils.sort.sort \
--key 2 \
/input/300names.txt \
/hdfs/path/to/output
the syntax of
--key
is
pos1[,pos2]
, where the first position (pos1) is required, and the second position (pos2) is optional - if it’s omitted then
pos1
through the rest of the line is used for sorting. just like the linux sort,
--key
is 1-based, so
--key 2
in the above example will sort on the second column in the file.
lzop integration
another trick that this sort utility has is its tight integration with lzop, a useful compression codec that works well with large files in mapreduce (see chapter 5 of
hadoop in practice
for more details on lzop). it can work with lzop input files that span multiple splits, and can also lzop-compress outputs, and even create lzop index files. you would do this with the
codec
and
lzop-index
options:
shell$ $hadoop_home/bin/hadoop jar hadoop-utils-<version>-jar-with-dependencies.jar \
com.alexholmes.hadooputils.sort.sort \
--key 2 \
--codec com.hadoop.compression.lzo.lzopcodec \
--map-codec com.hadoop.compression.lzo.lzocodec \
--lzop-index \
/hdfs/path/to/input \
/hdfs/path/to/outputmultiple reducers and total ordering
if your sort job runs with multiple reducers (either because
mapreduce.job.reduces
in
mapred-site.xml
has been set to a number larger than 1, or because you’ve used the
-r
option to specify the number of reducers on the command-line), then by default hadoop will use the
hashpartitioner
to distribute records across the reducers. use of the hashpartitioner means that you can’t concatenate your output files to create a single sorted output file. to do this you’ll need
total ordering
, which is supported by both the hadoop example sort and the hadoop-utils sort - the hadoop-utils sort enables this with the
--total-order
option.
shell$ $hadoop_home/bin/hadoop jar hadoop-utils-<version>-jar-with-dependencies.jar \
com.alexholmes.hadooputils.sort.sort \
--total-order 0.1 10000 10 \
/hdfs/path/to/input \
/hdfs/path/to/outputthe syntax is for this option is unintuitive so let’s look at what each field means.
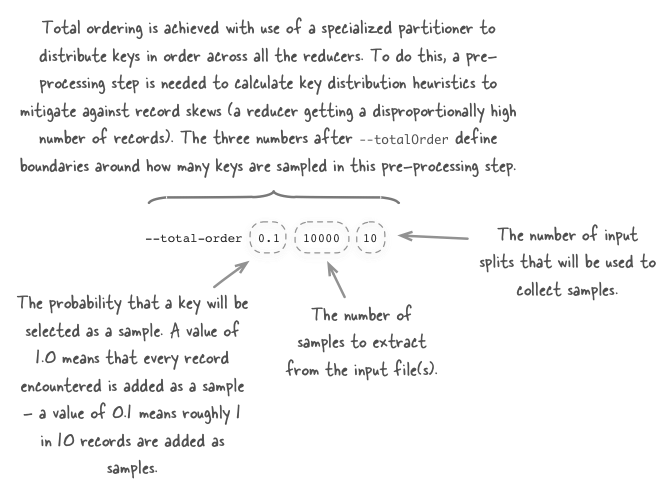
more details on total ordering can be seen in chapter 4 of hadoop in practice .
more details
for details on how to download and run the hadoop-utils sort take a look at the cli guide in the github project page .
Published at DZone with permission of Alex Holmes. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments