Processing 200,000 Records in Under 3 Hours
A developer tells how he was able to use MuleSoft, Salesforce, and some integration known to solve a time crunch issues for his team.
Join the DZone community and get the full member experience.
Join For Free"Pay Per Use" is a common billing strategy where customers are charged depending on how many times they use a certain feature. Recently, our current monthly batch process that loads usages records into Salesforce was failing due to the ESB system being overwhelmed. The system was originally designed to handle 20,000 records a month but we had just crossed the 200,000 record count last month, a 10x increase of what was expected. While a great problem to have for the business, as a developer and architect I had to find a way to keep a handle on this load and keep the process running.
Our current ESB system (name omitted) which runs in a 4 server cluster simply couldn't handle the size of the input. During the first hour it would process a consistent 22 transactions a second; however the longer it ran the slower it got. Often we would find it crawling along as low as 2 transactions a second. At this point, we would need to quickly restart the whole ESB before timeouts starting occurring and records were lost.
I pitched an idea to my Product Owner to allow me to move this process to MuleSoft's Anypoint Platform. He agreed as long as I could get all 200,000 usage records loaded under 3 hours. Challenge accepted!
Below is my first attempt at rewriting the batch job using Mule 4. For simplicity, I've removed the components that don't demonstrate the major time saving actions I took. 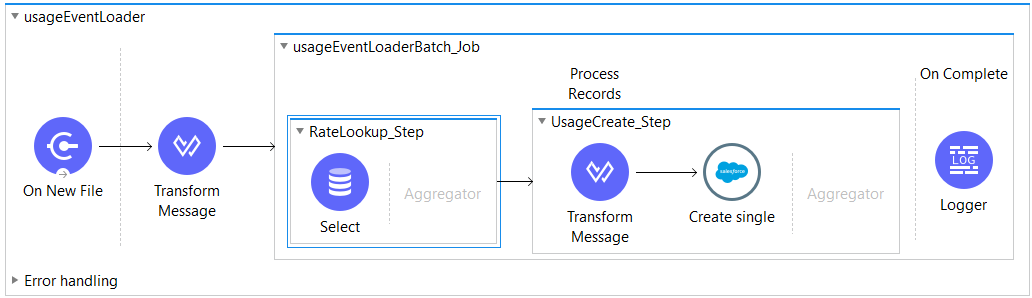 The job starts when a newly uploaded CSV file is detected. After parsing each line in the file, which represents a usage record, we look up the customer's cost per usage (rate) in our local database. Then we combine the rate information to the payload and upload it to Salesforce.
The job starts when a newly uploaded CSV file is detected. After parsing each line in the file, which represents a usage record, we look up the customer's cost per usage (rate) in our local database. Then we combine the rate information to the payload and upload it to Salesforce.
Results: Processing 200,000 usage records took 3 hours and 25 minutes. The run was stable unlike the current process but it needed to be faster.
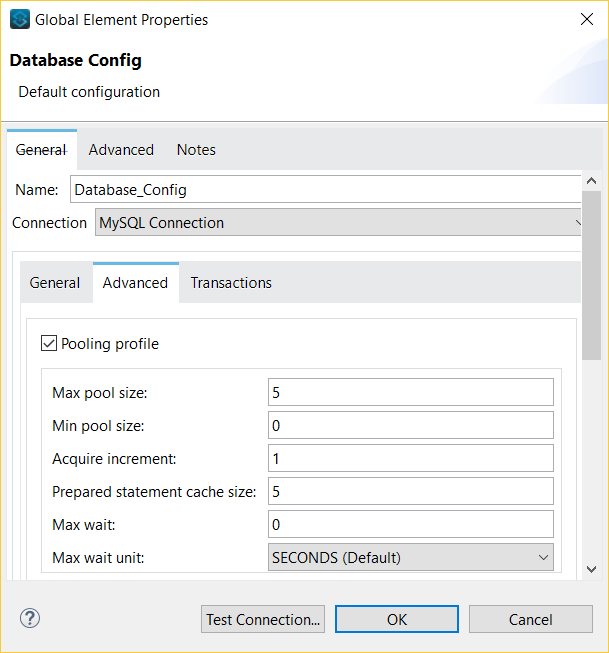
After our first run, our database logs were full of messages complaining about the driver not being able to "to create a connection." Turns out, by default, Mule uses 16 threads to process records simultaneously. However, our database configuration was set to only allow a single connection at a time, causing requests by multiple threads to wait until the connection was free to query the database. As shown above, I increased the database connection pool to 5 and reran the process.
Results: Processing 200,000 usage records took 2 hours and 47 minutes ( - 38 minutes ). Much improved but it needed to be faster.

Creating timestamps entering and exiting each batch step allowed me to figure out where most of the processing time was spent and it was definitely on the call out to SalesForce. After browsing through the Salesforce Connector documentation I found an operation to upload objects in bulk. Awesome! I dragged that component onto the batch step, wrapped it inside a Batch Aggregator Scope, and reran the process again. Fingers crossed!
Results: Processing 200,000 usage records took 1 hour and 54 minutes ( - 53 minutes ).
I did it! The process handled 200,000 records in under 2 hours, averaging 29 transactions a second. This was much lower than the 3 hours the business needed which will accommodate future growth with no server crashes. I went back to my Product Owner and told him we no longer have to worry about incorrect customer billing. He was quite impressed with the results and shared the good news along with praises of my work across the organization. Thank you, Mule, for making me look good.
Opinions expressed by DZone contributors are their own.
Comments