Storage-Computing Integration vs. Separation: Architectural Trade-offs, Use Cases, and Insights from Apache Doris
Discover the pros, cons, and use cases of storage-computing integration vs. separation, with real-world insights from Apache Doris’s hybrid architecture.
Join the DZone community and get the full member experience.
Join For FreeIn the field of databases and big data, the architectural debate between “storage-computing integration” and “storage-computing separation” has never ceased. Some people question, “Is storage-computing separation really necessary? Isn’t the performance of local disks sufficient?” The answer is not black and white — the key to technology selection lies in the precise matching of business scenarios and resource requirements. This article takes Apache Doris as an example to analyze the essential differences, advantages and disadvantages, and implementation scenarios of the two architectures.
Storage-Computing Integration vs. Storage-Computing Separation
Storage-Computing Integration: The Tightly-Coupled “All-Rounder”
Definition: Data storage and computing resources are bound to the same node (such as a local disk + server), and local reading and writing are used to reduce network overhead. Typical examples include the early architecture of Hadoop and traditional OLTP databases.
Historical Origin: In the early days of IT systems, the data volume was small (such as IBM mainframes in the 1960s), and a single machine could meet the storage and computing requirements, naturally forming a storage-computing integration architecture.
Storage-Computing Separation: The Decoupled “Perfect Partners”
Definition: The storage layer (such as object storage, HDFS) and the computing layer (such as cloud servers, container clusters) are independently scalable and connected through a high-speed network to achieve data sharing. Typical representatives include the cloud-native database Snowflake and the storage-computing separation mode of Doris.
Driving Forces: Exponential growth of data volume, elastic requirements of cloud computing, and fine-grained cost control.
Architectural Duel: The Ultimate Game of Performance, Cost, and Elasticity
Advantages and Shortcomings of Storage-Computing Integration
Advantages
- Minimal Deployment: It does not need to rely on external storage systems and can run on a single machine, which is suitable for quick trials or small to medium-scale scenarios (for example, the storage-computing integration mode of Doris only requires the deployment of FE/BE processes).
- Ultimate Performance: Local reading and writing reduce network latency, making it suitable for high-concurrency and low-latency scenarios. (For example, in the YCSB scenario, the storage-computing integration of Doris can reach 30,000 QPS, and the 99th percentile latency is as low as 0.6ms)
Shortcomings
- Inflexible Expansion: Storage and computing need to be scaled simultaneously, which is likely to cause resource waste (for example, the CPU is idle while the disk is full).
- High Cost: The price of local SSD disks is high, and redundant backups increase hardware investment (for example, the storage-computing integration version of Doris requires three copies to ensure high data reliability).
Breakthroughs and Challenges of Storage-Computing Separation
Advantages
- Elastic Scalability: Computing resources can be scaled on demand, and storage can be independently expanded (for example, the computing group of Doris can dynamically add or remove nodes).
- Cost Optimization: Shared storage (such as object storage) costs as low as 1/3 of that of local disks and supports hierarchical management of hot and cold data.
- High Availability: The storage layer has independent disaster recovery, and there is no risk of data loss in case of computing node failures.
Challenges
- Network Bottleneck: Remote reading and writing may introduce latency (relying on intelligent caching optimization).
- Operation and Maintenance Complexity: It is necessary to manage shared storage (such as HDFS, S3) and network stability.
Scenarios Matter: How to Choose the Most Suitable Architecture?
The “Main Battlefield” of Storage-Computing Integration
- Small to Medium-Scale Real-Time Analysis: The data volume is within the TB level, and low latency is pursued (such as the high-concurrency query scenario of Doris).
- Independent Business Lines: There is no dedicated DBA team, and simple operation and maintenance are required (such as start-ups trying out data analysis).
- No Dependence on Cloud Environment: Localized deployment and no reliable shared storage resources.
The “Killer Scenarios” of Storage-Computing Separation
- Cloud Native and Elastic Requirements: In public cloud / hybrid cloud environments, pay-as-you-go is required (for example, the cloud-native version of Doris supports K8s containerization).
- Massive Data Lake Warehouses: PB-level data storage, and multiple computing clusters share the same data source (such as financial risk control, e-commerce user portraits).
- Cost-Sensitive Businesses: Archiving historical data, low-cost storage of cold data (such as the hot and cold layering technology of Doris).
Practical Insights from Doris: Can You Have Your Cake and Eat It Too?
As a new-generation real-time analysis database, Apache Doris supports both storage-computing integration and storage-computing separation modes, becoming a benchmark for architectural flexibility:
Storage-Computing Integration Mode
Applicable Scenarios: Development and testing, small to medium-scale real-time analysis.
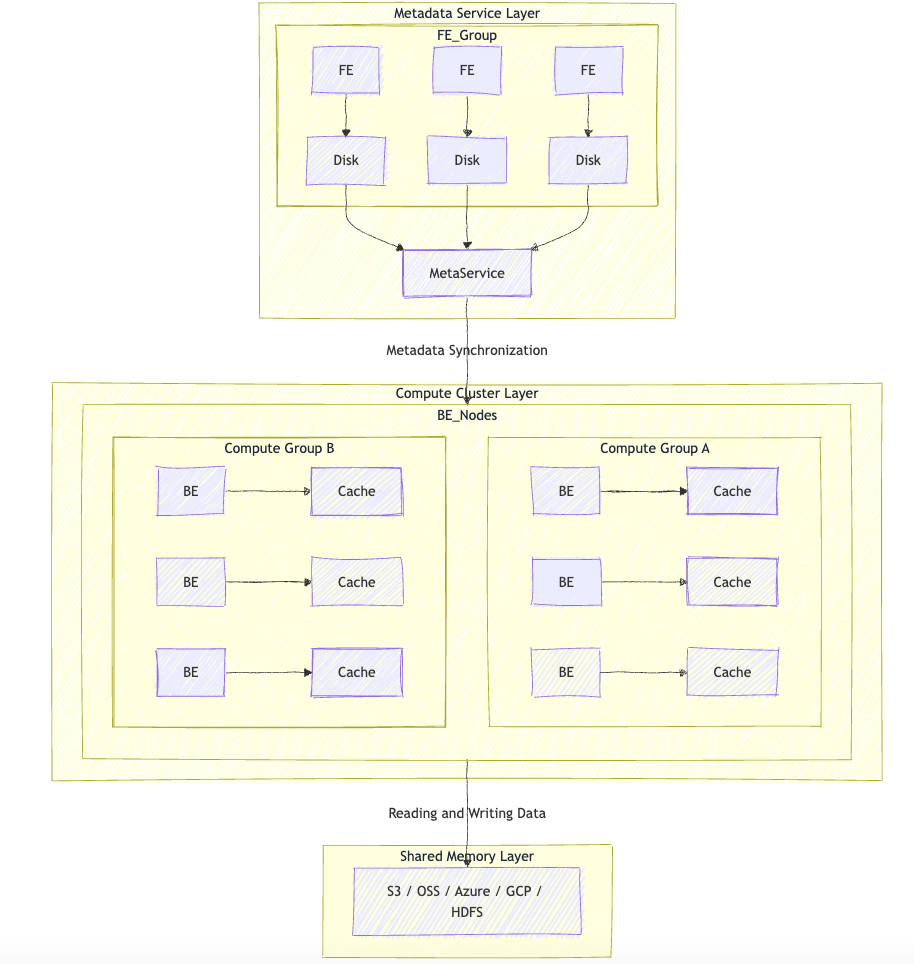
Storage-Computing Separation Mode
Technical Highlights
- Shared Storage: Supports HDFS/S3, decoupling the main data storage from computing nodes.
- Local Cache: BE nodes cache hot data to offset network latency.
Conclusion: There Is No Absolutely Optimal, Only the Most Suitable Match
Storage-computing separation is not a “panacea,” and storage-computing integration is not an “outdated product.” Technical decisions should return to the essence of the business:
- Choose Storage-Computing Integration: When performance is sensitive, the data scale is controllable, and operation and maintenance resources are limited.
- Embrace Storage-Computing Separation: When cost and elasticity are the core requirements and a cloud-native technology stack is available.
In the future, with the breakthroughs in storage networks (such as RDMA) and intelligent caching technologies, the “performance ceiling” of storage-computing separation will be further broken. The continuous evolution of open-source technologies such as Doris is providing more possibilities for this architectural debate.
Published at DZone with permission of Darren Xu. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments