Synchronous Replication in Tarantool (Part 1)
Tarantool offers synchronous replication and the Raft-based algorithm for choosing a leader. In this series, learn of the algorithm's design and implementation.
Join the DZone community and get the full member experience.
Join For Free Tarantool is an in-memory computing platform with a focus on horizontal scalability. It means that when one instance doesn't provide enough performance, you have to add more instances, not allocate more resources to that one instance.
Tarantool is an in-memory computing platform with a focus on horizontal scalability. It means that when one instance doesn't provide enough performance, you have to add more instances, not allocate more resources to that one instance.
In the beginning, built-in asynchronous replication was the only horizontal scalability feature in Tarantool. It was enough for most tasks. However, there are cases where no external module can substitute synchronous replication, which Tarantool lacked at the time.
There were many attempts to implement synchronous replication in Tarantool during the last years. Now, in the release of version 2.6, Tarantool offers synchronous replication and the Raft-based algorithm for choosing a leader.
In this article, we'll talk about the long path to the algorithm's design and implementation. It is quite a long read, but all its sections are essential and add up to a single story. However, if you don't have time for a long read, here is a summary of the sections. You can skip the topics you are already familiar with.
- Replication: Introduction, clarification of important points.
- History of synchronous replication development in Tarantool: Before discussing technical details, let's talk about how the algorithm was developed. It was a 5-year-long journey, full of mistakes and lessons.
- Raft: replication and leader election: Without learning about this protocol, you can't understand synchronous replication in Tarantool. This section focuses on replication and offers a short description of the election process.
- Asynchronous replication: Until recently, only asynchronous replication was available in Tarantool. As synchronous replication is based on asynchronous, you first need to learn about the former to dive into the topic.
- Synchronous replication: In this section, the algorithm and its implementation are described in the context of a transaction's lifecycle. The section also covers differences from Raft and presents the Tarantool synchronous replication interface.
1. Replication
In databases, replication is the technology that allows supporting the current copy of a database on several nodes. A group of such nodes is called a replication group or, less formally, a replica set. Usually, a replica set has one main node that deals with updating, deleting, and inserting data, as well as processing transactions. The main node is usually called a master. The other nodes are called replicas. There is also "master-master replication," where all nodes in the replica set can alter data.
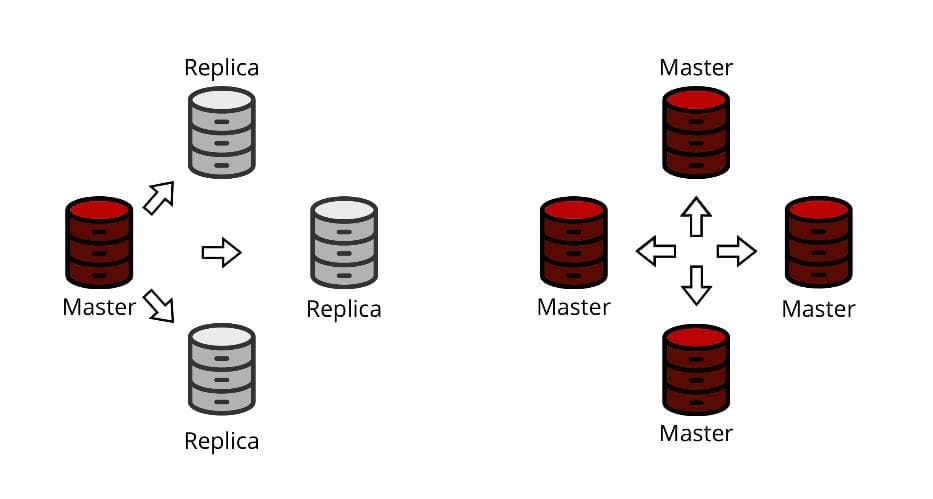
Replication serves several purposes. One of the most popular and obvious ones is backing up data. The database must be able to receive client requests if the master crashes. Another popular case is load distribution, where client requests are balanced between several instances of a database. Replication is necessary if the load is too much for a single node to handle. With replication, we can also achieve minimal latency for update/insert/delete operations on the master if read operations can be distributed between replicas.
Usually, two types of replication are distinguished: synchronous and asynchronous.
Asynchronous Replication
In asynchronous replication, a transaction can be committed on the master before being sent to the replicas. That means the client receives a positive response if the data was successfully changed and the operation was recorded in the database log.
The asynchronous transaction lifecycle consists of the following steps:
- Creating a transaction
- Changing some data
- Logging the transaction
- Telling the client that the transaction is finished
After being logged, the transaction is sent to the replicas where it goes through the same steps.
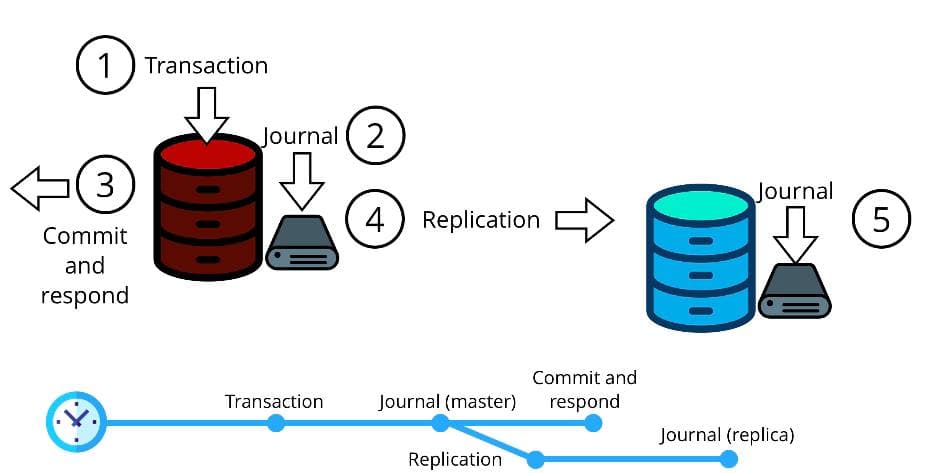
This type of replication is enough for most tasks. However, asynchronous replication is inapplicable in some cases or requires workarounds to get the desired result. One peculiar problem is that the master node might fail between steps 3 and 5 on the picture. The client has already received confirmation about a successful transaction, but the transaction isn't yet on the replicas.
As a result, if one of the replicas is chosen as the new master, the transaction will be lost for the client. At first, the client receives the response that the transaction is committed, and then the transaction vanishes without a trace.
If the database stores non-critical data, like analytics or logs, this behavior may be harmless. However, if the stored data is sensitive, like bank transactions, game saves, or game inventory purchased for real money, data loss is unacceptable.
There are several ways to solve this problem. First, there is an option to keep using asynchronous replication and deal with problems as they arise. With Tarantool, you can write replication logic so that after a successful commit, the application doesn't respond to the client right away but waits until the replicas receive the transaction. The Tarantool API allows it with a few workarounds. But this solution wouldn't always work. Even if the request that initiated the transaction waits for the replication, other requests to the database will see the changes this transaction has performed, and the original problem might repeat. This behavior is called "dirty reads".
Client 1 | Client 2
-------------------------------+--------------------------------
box.space.money:update( v
{uid}, {{'+', 'sum', 50}} |
) v
-------------------------------+--------------------------------
v -- Sees uncommitted
| -- data!
v box.space.money:get({uid})
-------------------------------+--------------------------------
wait_replication(timeout) |
vIn the example, two clients are working with a database. One client transfers 50 money units to their account and begins waiting for replication to start. The other client sees the transaction data before it is on all the replicas. This other client may be a bank employee or software that credits money to accounts. Now, if the first client's transaction doesn't replicate within the timeout and rolls back, the second client will see non-existing data and might make the wrong decisions because of that.
Thus, manually accommodating the replication delay is a very specific hack that is hard to use and not always possible.
Synchronous Replication
The best idea in this situation is to use synchronous replication, then the transaction won't be considered complete until it is replicated on a certain number of replicas.
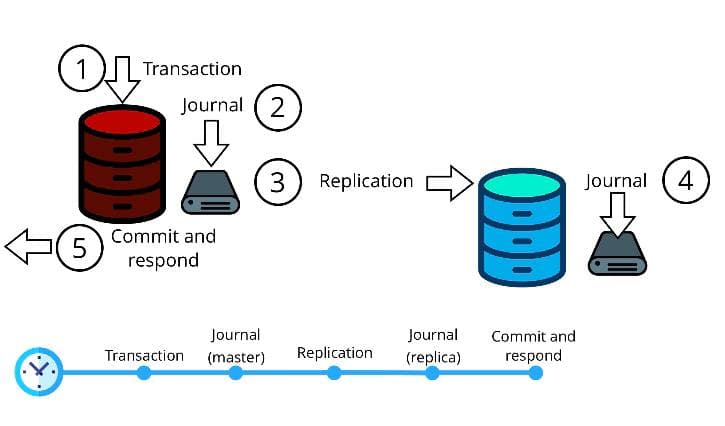
Note that the commit and response step is made at the end, after the replication.
The number of replicas required to commit a transaction is called a quorum. Usually, a quorum consists of 50% of the replica set plus 1 replica. For example, in the case of two nodes, a synchronous transaction must reach two nodes; for three nodes, also two; for four nodes, three; for five nodes, three; etc.
We add one more replica to the 50 percent so that the cluster doesn't lose data, even if half of the nodes are down. It's a good level of reliability. Additionally, here is another reason: synchronous replication algorithms usually involve leader election. For a new leader to be elected, more than half of the nodes must vote for it. A quorum consisting of half of the nodes or fewer might select more than one leader. That's where 50% plus 1 comes from. A single quorum is used for all decisions, transaction commits and elections alike.
You might be thinking: If synchronous replication is so much better than asynchronous, why not use it all the time? The answer is that synchronicity comes at a price.
- Speed: Synchronous replication is slower since the latency between the beginning and the end of the commit grows significantly. It happens because of network performance and log activity on the other nodes. The transaction has to be sent to the nodes and logged there, and the client has to receive an answer. Just the fact that the network is involved potentially increases the delay up to milliseconds.
- Synchronous replication makes it harder to keep the replica set available for writes. In the case of asynchronous replication, if there is a master, data can be updated no matter how many replicas are available. With synchronous replication, even if the master is available, it might be unable to commit new transactions if there aren't enough replicas (for example, if some of them failed). In this case, the quorum can't be reached for new transactions.
- Synchronous replication is harder to configure and program. You have to pick the quorum number (if the canonical 50% plus 1 isn't enough), define the timeout for the transaction commit, and set up monitoring. The application code must be able to handle various network-related errors.
- Synchronous replication doesn't support master-master replication. This is a limitation of the algorithm currently used in Tarantool.
However, in exchange for these difficulties, you get much better guarantees of data safety.
Luckily, there is no need to invent a synchronous replication algorithm from scratch. There are already several algorithms considered a standard. Raft is the most popular one at the moment. Here are a few reasons why:
- It guarantees data safety as long as more than half of the cluster is functional.
- It is quite straightforward. You don't need to be a database developer to understand it.
- It is not new. The algorithm has been around for a while, tested and tried, and formally proven correct.
- It includes a leader election algorithm.
Raft has two implementations in Tarantool: synchronous replication and leader election. Both were adapted to the existing Tarantool log format and general architecture. Read further to learn more about Raft and its synchronous replication implementation.
2. History of Synchronous Replication in Tarantool
Before discussing technical details, let's talk about how the algorithm was developed. It was a five-year-long journey during which I was the only member who continuously stayed on the Tarantool team. There even was one developer who left and came back to our team.
The task of developing synchronous replication has existed in Tarantool since 2015, for as long as I remember working here. Initially, synchronous replication wasn't considered a necessary feature. There were always more important tasks or not enough resources. However, the implementation was obviously inevitable.
As Tarantool continued to grow, one thing started becoming apparent: without synchronous replication, the DBMS had no opportunity for application in some areas, like certain banking tasks. The absence of synchronous replication had to be bypassed in the application code. It raised the entry threshold significantly, increased error probability and development costs.
At first, the task was to be done by a single person, from scratch and all at once. However, the difficulty was too high, and the developer eventually left the team. It was decided to split synchronous replication into several smaller tasks and do them in parallel. Let's look at these smaller components.
The SWIM protocol is responsible for building a cluster and detecting failures. In Raft, there are two components that work independently: synchronous replication with a known leader, and new leader election. To elect a new leader, the system has to detect the failure of the old one somehow. This could make the third Raft component, modeled by the SWIM protocol.
The SWIM protocol could also be used for Raft message transfer, for example, during leader election. Another application would be an automated cluster build so that the nodes could detect each other and connect as Raft demands.
The proxy module automatically redirects requests from replicas to the leader. In Raft, if a request was sent to a replica, the replica must redirect it to the leader. Our idea was to enable the user to create a proxy server in any instance. If the instance is the leader, the proxy would accept requests, and if not, it would redirect requests to the leader. The algorithm is completely transparent for the user.
Manual leader election — box.ctl.promote() — is a function that can be called from an instance to make it a leader so that all other instances become replicas. We assumed that the biggest challenge in leader election is starting the process, so we first decided to implement manual election.
We also implemented optimizations that Raft supposedly couldn't work without. The first optimization reduced excess traffic in the cluster. The second created and supported a cache to store a part of the transaction log in memory. It allowed replicating faster and more efficiently in terms of CPU time consumption.
The last task was to automate leader election: a logical conclusion to the Raft protocol.
This list of tasks was formulated in 2015 and then shelved for a few years. Our team focused on more critical tasks such as the vinyl on-disk engine, SQL, and sharding.
Manual Election
In 2018, our team received additional funding, which made synchronous replication development possible again. The first thing we tried implementing was box.ctl.promote().
The task appeared very simple. However, during the design and development process, it turned out that even if the leader was assigned manually, there were the same problems as with automated election. At least half of the replicas should vote for the new leader unanimously, and if the old leader is up again, it should be ignored.
The resulting leader election was almost identical to the Raft implementation. However, the Tarantool election didn't start automatically, even if the current leader was unavailable. Obviously, there was no reason to implement box.ctl.promote() in its original design because it was a cut-down version of Raft.
Proxy
At the same time, in 2018, we decided to begin developing the proxy module. According to the plan, it had to route requests to the main node even with asynchronous replication.
The module was designed and developed, but there were several issues with implementing some technically complex details. We didn't want to break reverse compatibility, overcomplicate the code and the protocol, or make updates to multiple Tarantool connectors. Also, there were many questions about how to make the interface user-friendly.
Should it be a separate module, or should it be integrated into the existing interfaces? Should it work out of the box or be downloaded separately? How should authorization work? Additionally, how shouldn't it work? Should it be transparent, or should the proxy server have its own authorization mechanism, users, and passwords?
The task was delayed indefinitely because there were a lot of problems to solve. Besides, the vshard module, which appeared the same year, had proxy capabilities.
SWIM
The next attempt to continue developing synchronous replication was made in late 2018 — early 2019. As a result, we developed the SWIM protocol in a year. It was implemented as a built-in module available for any task, even without replication, right out of Lua. It became possible to create multiple SWIM nodes on one instance. The plan was to have an internal Tarantool SWIM module specifically for Raft messages, failure detection, and automatic cluster building.
The module was successfully implemented and released but remained unused in synchronous replication. It turned out it wasn't as necessary as it seemed. However, it is still obvious that SWIM can simplify many aspects of replication, and it is worth coming back to.
Optimizing Replication
In parallel to SWIM, our team was optimizing replication algorithms for about a year. However, in the end, the proposed optimizations were deemed unnecessary, and one of them turned out to be harmful.
During that optimization, we also redesigned the database log structure and interface to make it "synchronous." In this way, before a transaction was committed, it was replicated by the log, not by the transaction engine. This approach didn't lead to anything good: the result strayed far from Raft and raised concerns.
The developer working on the feature above left the team. Shortly before that, the person responsible for initial planning, the CTO of Tarantool, left as well. Almost at the same time, another strong developer left the team after receiving an offer from Google. As a result, our team was weakened and the progress was almost completely nullified.
With new leadership, the approach to planning and development has changed drastically. The previous approach involved no strict deadlines but demanded to make everything at once and perfectly. The new management suggested devising a plan, creating a minimal working version, and improving it with strict deadlines.
The progress accelerated significantly. Synchronous replication saw the light in 2020, in less than a year. It was based on the Raft protocol. The minimal working version required only two things: synchronous log and leader election. Thus, it was implemented without years of preparations, countless subtasks, or rewriting the existing Tarantool systems — as far as the first version is concerned.
Read the next part of this article here: Synchronous replication in Tarantool (Part 2).
Opinions expressed by DZone contributors are their own.
Comments