Task-Specific Large Language Models Using Distillation
Reducing LLM costs through distillation is an effective method for achieving cost-quality trade-offs for task-specific LLMs.
Join the DZone community and get the full member experience.
Join For FreeLarge Language Models
Large language models (LLMs) represent a significant advancement in Artificial Intelligence, particularly in the field of Natural Language Processing. These models are designed to understand, generate, and interact with natural language in a way that closely mimics human communication. Trained on vast datasets comprising text from diverse sources, LLMs learn to recognize patterns, contexts, and nuances within language, enabling them to perform tasks such as translation, summarization, question-answering, and creative writing. Their ability to generate coherent and contextually relevant text makes them valuable tools in various applications, including customer service, content creation, and educational assistance.
General-purpose LLMs are powerful and impressive but come with issues like non-determinism in outputs and formatting, and high resource and financial costs. Smaller, task-specific LLMs distilled from larger, general-purpose LLMs can be an attractive option for many tasks.
Cost/Quality Trade-Off
While large and powerful LLMs offer unparalleled capabilities in tasks demanding deep language understanding and generation, their inherent complexity presents significant challenges for real-world deployment, particularly in scenarios requiring low latency and cost-effectiveness.
High Latency
- Real-time interactions: LLMs often operate with high latency, meaning there's a noticeable delay between input and output. This can be detrimental in applications requiring real-time responses.
- User experience: High latency can create a frustrating user experience, leading to user churn and reduced engagement.
- Limited scalability: Scaling LLMs for large numbers of users while maintaining low latency can be challenging.
Inference Cost
- Computational resources: Running an LLM for inference, especially a large one, requires significant computational power.
- Cost per request: The cost of utilizing an LLM can vary depending on the model size, complexity of the task, and the number of requests. For real-time applications with high request volumes, these costs can quickly escalate.
Exploring smaller, more efficient LLMs specifically tailored for specific tasks can be a cost-effective alternative while still achieving acceptable performance.
Distilling Task-Specific Large Language Models
Distillation [1] involves generating a large amount of data from a large/expensive LLM (called a teacher model), and training a smaller, more efficient, and performant LLM (called a student model) on it to achieve quality comparable to the larger LLM.
This works especially well for deploying an LLM to perform a single task (eg: summarizing text, extracting key pieces of information from large amounts of text, etc.)
Generating Training Data
Training data of the order of thousands to millions of examples is needed to train a high-quality model. We only need the inputs of the examples, for instance: for the task of summarizing documents, we only need the input documents.
Piece-1: Training Inputs
The strategy for generating training data depends on whether you already have a source of inputs, or are starting from scratch:
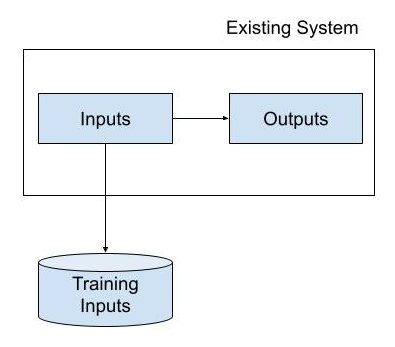
Existing System as Input Source: If there is an existing system for which you’re building this model, the inputs can be extracted from the system.
LLMs to Generate Inputs: If there’s no large-scale source of high-quality inputs, few-shot prompting of a large/powerful LLM with a small number (3-5) of examples can yield a large volume of training data inputs. Note that this is a one-time expense for creating training-data and not a recurring expense throughout the life of the task-specific LLM that you’re trying to deploy.
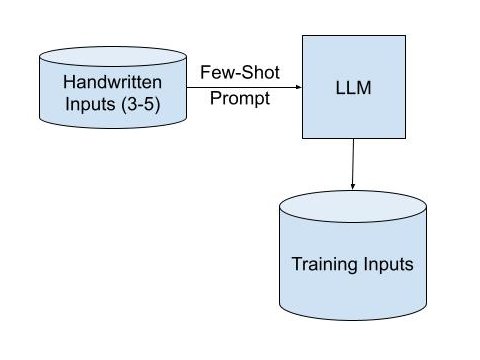
In either of these techniques, it’s best to have a broad set of natural-sounding inputs, in order to best reflect the inputs expected in the real-world application where the LLM will be deployed. LLMs are great at recognizing patterns, so it’s helpful to not have repetitive, templated, or artificial training inputs.
Piece-2: Training Outputs
The best quality (ie., large, expensive) LLM can be used to generate high-quality outputs for each of the training inputs. The best LLMs have strong zero-shot performance and are able to follow instructions well, so the task can be formulated as instructions (eg: “Summarize the text below. Avoid complex sentences in order to be readable in a hurry.”).
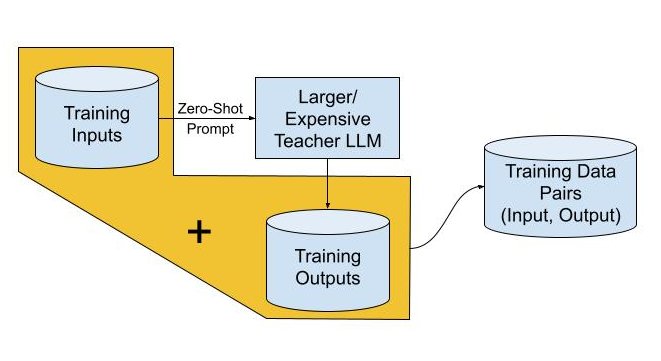
The pairs of training inputs and outputs, ideally between thousands to millions, form the training dataset for distillation into the student LLM.
Distillation Into Smaller, More Efficient LLMs
The student model is trained to mimic the teacher's outputs for the given inputs. You can use various loss functions to measure the difference between the teacher's outputs and the student's outputs.
The training process typically involves Supervised Fine-Tuning of the student model using the input prompts and output text from the teacher ie., the pairs generated above. The model then updates its weights to minimize the difference between the two.
Advantages of Distilled Student LLMs
- Cheaper serving and inference: The most significant advantage of a distilled student LLM is its reduced size. This translates to lower computational demands, resulting in lower costs for deploying and running the model.
- Lower latency: Smaller models inherently process information faster. This leads to lower latency, meaning responses are generated quickly.
- Comparable quality to teacher LLM: The key to successful distillation lies in the vast training data derived from the powerful "teacher" LLM. The student model effectively learns from the teacher's knowledge and expertise, allowing it to achieve comparable performance on the specific tasks for which it was trained.
Disadvantages of Distilled Student LLMs
- Task-specific nature: Distilled models are often highly specialized for the specific task they were trained on. They might excel in the specific task, but fall short in other areas. This limits their versatility.
- Lost general-purpose abilities: The fine-tuning process focuses on maximizing performance for the designated task, often at the expense of broader knowledge and adaptability.
Conclusions
Distillation is a powerful technique for making Large Language Models efficient and performant, which can be a critical factor when deploying LLMs for specific tasks. However, it's crucial to be mindful of their limitations, particularly their task-specific nature and the potential loss of general-purpose abilities.
References
Opinions expressed by DZone contributors are their own.
Comments