Terraform Drift Detection at Scale: How to Catch Configuration Drift Early
Automated drift detection ensures Terraform-managed infrastructure stays aligned with Git, reducing risk from manual changes across multi-cloud environments.
Join the DZone community and get the full member experience.
Join For FreeWhile Terraform possesses the declarative model for managing infrastructure across cloud platforms, it makes one assumption that is rare at scale: that the state of the deployed infrastructure is always managed exclusively through Terraform. In practice, environments evolve. Under such pressure, teams manually make changes, apply hotfixes directly in the cloud console, and deploy infrastructure through the parallelisation of automation.
These changes create configuration drift outside of the Terraform lifecycle. The infrastructure stays functional but is misaligned with the Terraform codebase, causing unpredictable behavior, broken expectations, and sometimes even production incidents.
In order to resolve this problem, we have an automated drift detection system that runs continuously across our multi-cloud environments (AWS, Azure, GCP). It is a system that detects and reports divergence between what is provisioned and what is declared in Git. In this article, we explain how it works, how we integrated it into our workflows and the decisions we made to ensure it scaled reliably.
Understanding Configuration Drift
How Drift Happens in Terraform Workflows
Configuration drift occurs when infrastructure is modified outside of Terraform — through manual edits, external tools, or emergency fixes not committed to code. This can happen through:
- Manual changes in the cloud console
- Untracked hotfixes during incidents
- Other tools and APIs that modify resources
- Environmental factors such as auto-scaling or third-party tagging
Terraform does not detect changes made directly to infrastructure unless the state is explicitly refreshed, and even then, minor changes may go unnoticed. It compares the Terraform code to the last known state, not the actual infrastructure, unless it is refreshed. Even if you do this, minor or cloud-managed changes might go unnoticed unless they're adequately differentiated.
Risk Profile of Drift
While a drift will not always break infrastructure quickly, it slowly degrades reliability. For example, IAM policies that are not stored in version control and are, therefore, changed outside of the source of truth typically remain undocumented. Configuring the network can help restore the lost network until Terraform solves the issues through changes that later become long-term liabilities when Terraform reverts.
Drift introduces fragility in multi-team environments. The more small changes propagate inconsistencies across environments, the more engineers lose confidence in Terraform, which should be a source of truth.
Designing Drift Detection That Scales
Anchoring to Git, Not Just Terraform State
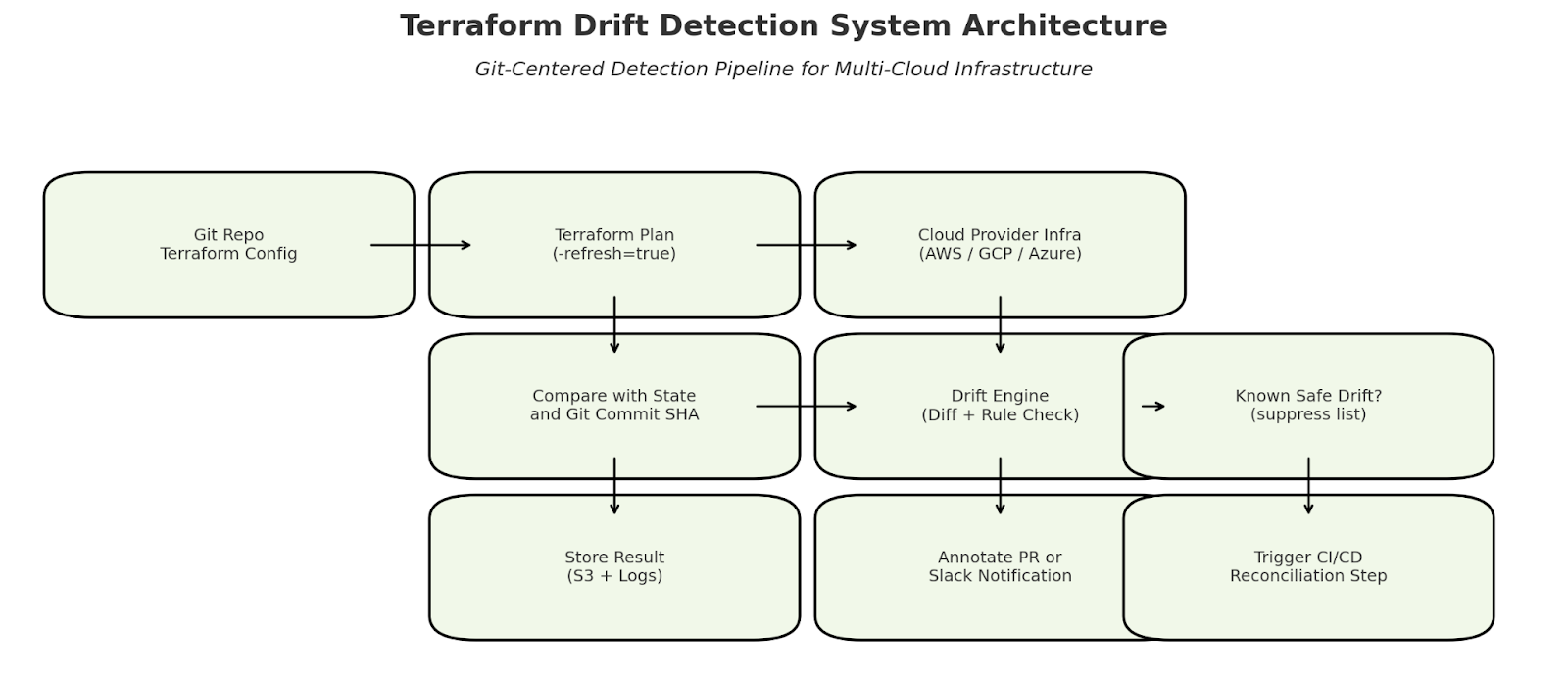
In our design, the core principle was to treat Git as the source of infrastructure truth rather than the Terraform state. We measure drift by checking the latest live environment (with a fresh Terraform plan-refresh=true) against the state of code as committed to version control.
In each module, we have added a CI job, which runs on a regular schedule and builds on each PR. The job:
- It refreshes the provider's Terraform state.
- Runs a plan against the code at the current Git SHA
- Compares the output with the expected plan (previous commit or baseline
The module is flagged if there are differences and no matching code change is found.
Multi-Cloud Support
Since our infrastructure is spread over AWS, GCP, and Azure, modular runners help us run drift checks per cloud provider. In each environment, a scheduled drift detector is executed in a restricted read-only context, which prevents accidental modification and allows it to run in production.
The plan hash, commit ID, timestamp, and diff details are pushed together with the results and metadata into a central storage location (in our case, an S3 bucket). This data is surfaced and aggregated through Slack alerts and Grafana dashboards.
Integrating Detection into the Developer Workflow
Pull Request Integration
The drift surfaces directly during the development cycle. We also check whether the corresponding module drifts when a pull request that only modifies the infrastructure code is opened.
If a drift occurs, we annotate the PR with a detailed plan diff and a warning. This allows the developer to check whether the drift is benign or should be reconciled. For instance, if a security group rule was modified manually, the diff will show what was edited before the PR removes it anyway.
Suppressing Known Non-Issues
Not all drift is actionable. Cloud providers frequently add or change metadata (e.g., last_updated, self_link, and dynamic tags) to make apps more dynamic. These do not require remediation.
To address this, we introduced configurable suppression rules per module. With those rules in place, the drift detection job provides only actionable differences, enough to create drift detection jobs for teams to focus on.
Improving Signal and Accountability
Human-Readable Diff Output
In earlier iterations, the system would simply post "drift detected" logs. These alerts weren't helpful. We also made improvements to the toolchain that presented human-readable diffs between code and live config, which were grouped by resource type and attribute for readability purposes.
This allowed developers and SREs to process their random fails without having to run plans locally or manually browse the cloud console.
Drift Aging and Priority
We also track the age of drift (changes that have persisted through multiple check cycles without resolution). A drift in a three-day-old dev database is okay. A drift that is older than 15 minutes is public-facing to an IAM policy is not.
With this aging model in place, we can escalate the alert appropriately without overwhelming teams during triage.
Lessons from Production
Start With Critical Modules
So, we started by performing drift detection only on modules associated with production environments and security-sensitive resources like IAM, VPCs, and external-facing gateways. When drift occurs, the blast radius from these resources is the worst.
Because the rollout was phased, we built confidence while showing value early without slowing down delivery or introducing unnecessary friction.
Detect Before You Enforce
At first, we did not enforce hard gates for drift. The goal was awareness. Once teams had visibility, they were proactive in helping tidy up and codify manual changes.
Today, our most critical modules are likely to break PR checks if a known drift exists. Some others report but do not block deployment. It allows for temporary fixes without negating long-term consistency.

Conclusion
Using Infrastructure-as-Code tools such as Terraform is a solid base for managing cloud resources; however, without drift detection, they operate on blind trust. This is not a real-world environment, so manual edits, unmanaged exceptions, and hotfixes will always exist in real-world areas. The trick is to catch it early, before it cascades into outages or regressions.
We combined Terraform, Git history, automated CI, and structured reporting to build a system that detects when infrastructure is not consistent with the code. It doesn't eradicate all risk but is primed for the feedback loop required to maintain consistency at scale.
For any operation in a multi-cloud environment working on multiple teams, this approach is not optional. At its core, it is about the difference between configuration as documentation and configuration as reality.
Opinions expressed by DZone contributors are their own.
Comments