Testing Your Code With Spock
Let's take a look at some of Spock's key features, how they stack up against vanilla JUnit, and see how it helps with your testing.
Join the DZone community and get the full member experience.
Join For FreeSpock is a testing and specification framework for Java and Groovy applications. Spock is:
- Extremely expressive
- Facilitates the Given/When/Then syntax for your tests
- Compatible with most IDEs and CI Servers.
Sounds interesting? Well, you can start playing with Spock very quickly by paying a quick visit to the Spock web console. When you have a little test you like, you can publish it like I did for this little Hello World test.
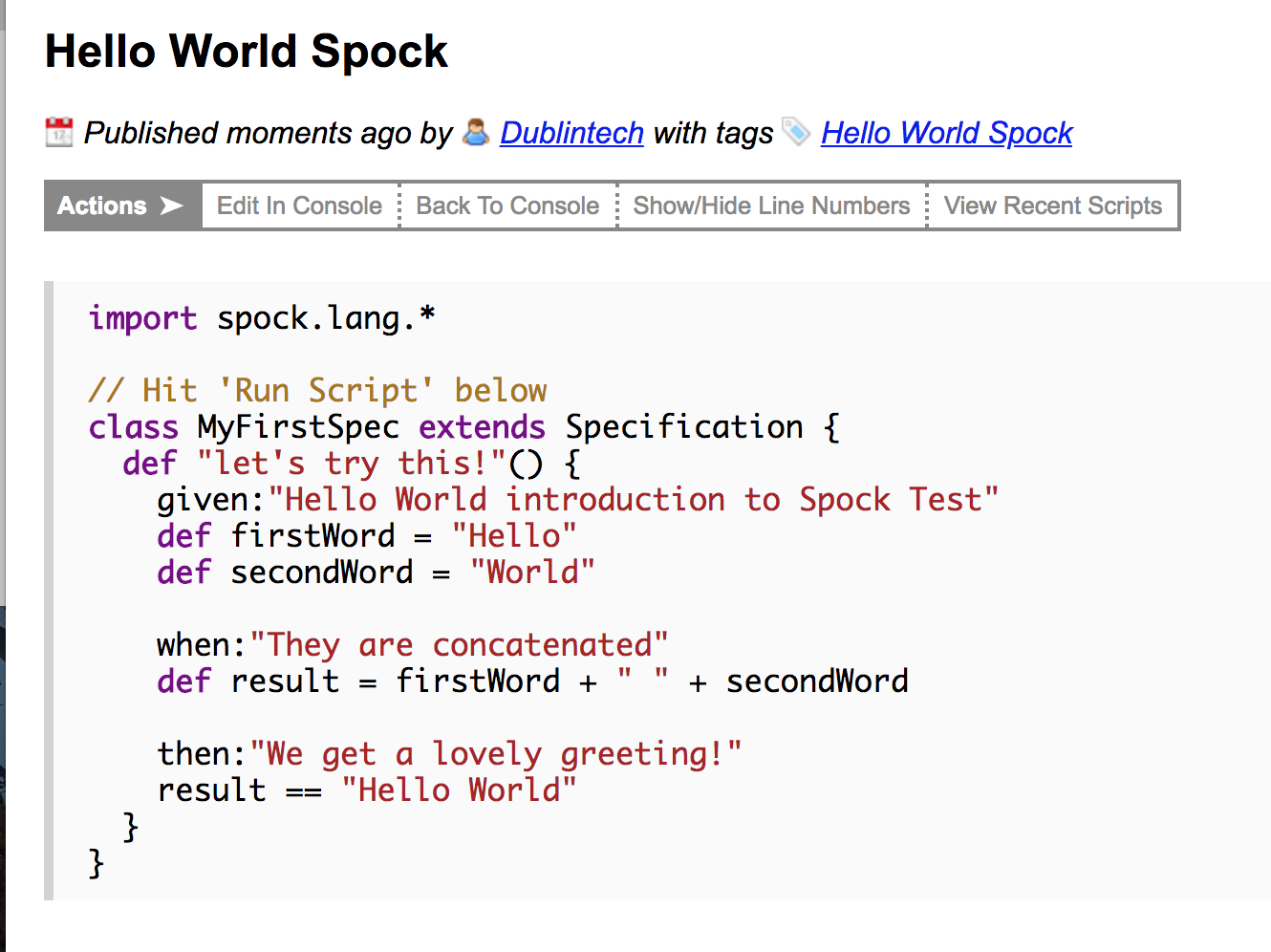
This Hello World test serves as a gentle introduction to some of the features of Spock.
Firstly, Spock tests are written in Groovy. That means some boilerplate code that you have with Java goes away. There is:
- No need to indicate the class is Public as it is by default.
- No need to declare firstWord and lastWord as Strings
- No need to hurt your little finger with a ; at the end every line
- No need to explicitly invoke assert, as every line of code in the expect block gets that automatically. Just make sure the lines in the then: block evaluate to a boolean expression. If it is true the test passes otherwise it fails. So in this case, it is just an equality expression which will either be true or false. You can have as many expressions as you want.
So less boilerplate code what next? Well you know those really long test names you get with JUnit tests, well instead of having to call this test, helloWorldIntroductionToSpockTest() which is difficult to read, you can just use a String with spaces as you normally do when you speak and name the test: Hello World introduction to Spock test.
This makes things much more readable.
Thirdly, the Given: When: Then: syntax, enforces test structure. No random asserts all over the test. They are in a designated place - inside the then: block and there only. More complex tests can use this structure to achieve BDD and ATDD. This means, a BA, QA, anybody can read what your test is doing.
Fourthly, if I were to make a small change to the test and change the assertion to also include Tony, the test will of course fail. But when I get a failure in Spock, I get the full context of the expression that is tested. I see the value of everything in the expression. This makes it much quicker to diagnose problems when tests fail.

Not bad for an introduction. Let's now have a look at more features.
Mocking and Stubbing
Mocking and Stubbing are much more powerful than what is possible with JUnit (and various add-ons). But it is not only super powerful in Spock, it is also very terse, keeping your test code very neat and easy to read.
Suppose we want to Stub a class called PaymentCalculator in our test, more specifically one of its methods, calculate(Product product, Integer count). In the stubbed version we want to return the count multiplied by 10 irrespective of the value of a product. In Spock, we achieve this by:
PaymentCalculator paymentCalculator = Stub(PaymentCalculator)
paymentCalculator.calculate(_, _) >> {p, c -> c * 10}If you haven't realized how short and neat this is, well then get yourself a coffee. If you have realized that you can still have a coffee and keep reading, consider these points:
- The underscores in calculate mean for all values
- On the right-hand side, of the second line, we see a Groovy Closure. For now, think of this as an anonymous method with two inputs: p for the product, c for count. We don't have to type them. That's just more boilerplate code gone.
- The closure will always return the count time 10. We don't need a return statement. The value of the last expression is always returned. Again, this means less boilerplate code. When stubbing becomes this easy and neat, it means you can really focus on the test — cool.
Parameterized Tests
The best way to explain this is by example.
@Unroll
def "Check that the rugby player #player who has Irish status #isIrish plays for Ireland"(String player, Boolean isIrish) {
given:"An instance of Rugby player validator"
RugbyPlayerValidator rugbyPlayerValidator = new RugbyPlayerValidator()
expect:
rugbyPlayerValidator.isIrish(player) == isIrish
where:
player || isIrish
"Johny Sexton" || true
"Stuart Hogg" || false
"Conor Murray" || true
"George North" || false
"Jack Nowell" || true
}In this parameterized test, we see the following:
- The test is parameterized. The test signature having parameters tells us this, as does the where block.
- There is one input parameter player and one output parameter — which corresponds to an expected value.
- The test is parameterized five times. The input parameters are on the left, output on the right. It is, of course, possible to have more of either, in this test we just have one of each.
- The @Unroll annotation will mean that if the test fails, the values of all parameters will be outputted. The message will substitute the details of player into #player and the details of the Irish status substituted into #isIrish. So for example, "Checks that the rugby player Jack Nowell who has Irish status true plays for Ireland"
Again, this makes it much quicker to narrow in on bugs. Is the test wrong or is the code wrong? That becomes a question that can be answered faster. In this case, of course, it is the test that is wrong.
All the Benefits of Groovy
What else? Well, another major benefit is all the benefits of Groovy. For example, if you are testing an API that returns JSON or XML, Groovy is brilliant for parsing XML and JSON. Suppose we have an API that returns information about sports players in XML format. The format varies, but only slightly, depending on the sport they play:
<details>
<rugbysummarycategory>
<players>
<player>Joey Carberry</player>
<player>Teddy Thomas</player>
</players>
</rugbysummarycategory>
</details>
<details>
<footballsummarycategory>
<players>
<player>Lionel Messi</player>
<player>Cristiano Ronaldo</player>
</players>
</footballsummarycategory>
</details>We want to just invoke this API and then parse out the players irrespective of the sport. We can parse this polymorphically very simply in Groovy.
def rootNode = new XmlSlurper().parseText(xml)
def players = rootNode.'*'.Players.Player*.text()Some key points:
- The power of dynamic typing is immediate. The expression can be dynamically invoked on the rootNode. No verbose, complex XPath expression needed.
- The '*' is like a wildcard. That will cover both RugbySummaryCategory and FootballSummaryCategory.
- Player* means for all Player elements. So no silly verbose for loop needed here
- The text() expression just pulls out the values of the text between the respective Player elements. So we now have a list all players and can simply do: players.size() == 4. Remember, there is no need for the assert.
Suppose we want to check the players' names. Well, in this case, we don't care about order, so it makes more sense to convert the list to a Set and then check. Simple.
players as Set == ["Joey Carberry", "Teddy Thomas", "Lionel Messi", Cristiano Ranaldo"] as SetThis will convert both lists to a Set, which means order checking is gone and it is just a Set comparison. There's a ton more Groovy features we can take advantage of, but the beauty is, we don't actually have to.
All Java code is also valid in a Groovy class. The same hold trues for Spock. This means there is no steep learning curve for anyone from a Java background. They can code pure Java and then get some Groovy tips from code reviews, etc.
Powerful Annotations
Spock also has a range of powerful annotations for your tests. Again, we see the power of Groovy here as we can pass a closure to these annotations. For example:
@IgnoreIf({System.getProperty("os.name").contains("windows")})
def "I'll run anywhere except windows"() {...}Or just make your test fail if they take too long to execute:
@Timeout(value = 100, unit=TimeUnit.MILLISECONDS)
def "I better be quick"() {...}So in summary, Spock versus vanilla JUnit has the following advantages:
- Test Structure enforced. No more random asserts. Assertions can only be in designated parts of the code.
- Test code is much more readable.
- Much more information on the context of the failed test
- Can mock and stub with much less code
- Can leverage a pile of Groovy features to make code much less verbose
- Very powerful test parameterization, which can be done very neatly
- A range of powerful annotations.
And one of the often forgotten points is that your project doesn't have to be written in Groovy. You can keep it all in Java and leverage the static typing of Java for your production code and use the power and speed of Groovy for your test code.
Until the next time, take care of yourselves.
Published at DZone with permission of Alex Staveley. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments