The Battle of the Testing Triangle
Everyone's interpretation is different, but this is Sam Atkinson's take on what the each of the levels on the testing triangle mean.
Join the DZone community and get the full member experience.
Join For FreeWhilst recently setting out to start a new project, I had an enjoyable discussion with regards to the testing triangle. There are a number of different interpretations of what the triangle is, but this diagram is roughly what I think of when I think of the triangle:
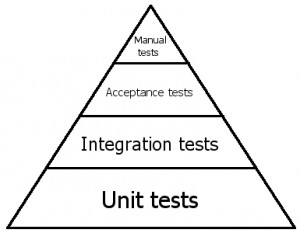
I think everyone's interpretation of the levels is different, but this is my take on it. The aim is to have a large number of quickly running unit tests, and as we move further up the triangle to integration and acceptance tests, the number of tests decreases as they take longer to run and become more complex to create. Unit tests should take no longer than a few minutes to run, with integration and acceptance tests taking no more than 10 minutes. Beyond these numbers, the fast feedback needed for these tests to be valuable is too slow, and you will likely see a trend up in broken builds and developers not taking the time to run tests on their machine.
But why do we need all three layers? Could we not rely solely on one type of test over the others?
Each layer of tests brings something to the table that the others cannot offer, which is why they must be used in conjunction. Unit tests, for example, are wonderful creatures. Particularly when created using TDD, they provide a wonderful way of documenting the intended function of a class and, for well-written code, can provide a way of exercising all of the code paths in a class to ensure that their functionality is completely correct. A good unit test has no complex dependencies, allowing for thousands to be run in seconds.
But whilst unit testing is great for ensuring that the individual “units” of our application work as intended, what they do not offer is proof that when they’re all wired up together that they will behave as intended. This then leads to integration tests, texting more, and more complex “chunks” of code together to make sure they work properly.
Unfortunately, we literally cannot test everything via integration tests. Imagine two simple classes, each of which has one “if” statement. Each class has two possible code paths, but wire them together, and that number increases exponentially to four. Any genuinely complex system is likely to have tens of thousands of execution paths, and that’s before we start considering issues like threading. This is why we need both integration and unit tests, which in combination provide us with a strong layer of protection.
The other quandary with integration tests is what scope they should cover. The more real parts of the system used, the more valid and realistic the test as it’s executing more production code. However, some parts of the system may be expensive in time and resources to start up, and eventually, we will reach system boundaries such as databases and third-party systems that we cannot start locally and need to be mocked or stubbed. So whilst we aim (wherever possible) to express as much of the system as possible in an integration test, that must be tapered against the need to run them in a timely fashion.
All of this begs the question, when do we test the whole system? In the old days, perhaps that would have been done by a large group of testers whose job was to run through a bunch of testing scripts. Hopefully, those days are gone, and in their place, we will have automated acceptance tests. Ideally, these will express the full system, with dependencies (although due to environmental limitations sometimes we must reluctantly still accept mocks). These are the true test cases where we are seeing full system functionality. These are often very expensive to write and maintain and are slow to run, as they require a full system start-up and realistic data sets. So, we end up with fewer acceptance tests.
Is there still a place for manual testing in this? I think that the first time a feature is built then absolutely, if only to have another set of eyes on the system to challenge your assumptions. However, any tests must then be automated for future run-throughs.
The question posed at the start of this new project was this: what should we target with regards to our testing? Should we aim for incredible unit test coverage at the sacrifice of fewer acceptance and integration tests, or value more complex tests that are more realistic but may leave gaps in coverage?
This will come down to personal preference and the nature of the system that you’re on. I personally like to start any new major feature with an integration test covering as much of the system as possible. Having this failing test gives me some confidence that I will know when the functionality is complete. I then use unit tests and TDD to build and design my system.
I also try to use fewer mocks these days in my unit tests than I used to instead of trying to test bigger units of several classes where appropriate, as this gives me further confidence that those areas are functioning correctly together.
I’m still unsure where the creation of acceptance tests lies in the process. I’m becoming a fan of cucumber for writing executable specs which can then be run against a real environment. This gives me bigger confidence that the functionality works as expected, but using a real environment does risk test failures occurring due to environmental issues, which in turn can erode confidence in the tests. I think a simple truism that if the acceptance tests have been failing for more than a day, then they require investigating is a good rule of thumb.
What about you? How do you split your tests?
Opinions expressed by DZone contributors are their own.
Comments