The Confusion Matrix in Statistical Tests
It's been a crazy flu season, so you may be interested to learn how to use big data and statistics to learn about diagnostic flu tests available to doctors.
Join the DZone community and get the full member experience.
Join For FreeThis winter was one of the worst flu seasons in recent years, so I found myself curious to learn more about the diagnostic flu tests available to doctors in addition to the usual "looks like a bad cold, but no signs of bacteria" strategy. There's a wide array of RIDTs (Rapid Influenza Dignostic Tests) available to doctors today, and reading through literature quickly gets you to decipher statements like:
Overall, RIDTs had a modest sensitivity of 62.3% and a high specificity of 98.2%, corresponding to a positive likelihood ratio of 34.5 and a negative likelihood ratio of 0.38. For the clinician, this means that although false-negatives are frequent (occurring in nearly four out of ten negative RIDTs), a positive test is unlikely to be a false-positive result. A diagnosis of influenza can thus confidently be made in the presence of a positive RIDT. However, a negative RIDT result is unreliable and should be confirmed by traditional diagnostic tests if the result is likely to affect patient management.
While I heard about statistical test quality measures like sensitivity before, there are too many terms here to remember for someone not dealing with these things routinely; this post is my attempt at documenting this understanding for future use.
A Table of Test Outcomes
Let's say there is a condition with a binary outcome ("yes" vs. "no", 1 vs. 0, or whatever you want to call it). Suppose we conduct a test that is designed to detect this condition; the test also has a binary outcome. The totality of outcomes can thus be represented with a two-by-two table, which is also called the Confusion Matrix.
Suppose 10,000 patients get tested for flu; out of them, 9,000 are actually healthy and 1,000 are actually sick. For the sick people, a test was positive for 620 and negative for 380. For the healthy people, the same test was positive for 180 and negative for 8,820. Let's summarize these results in a table:
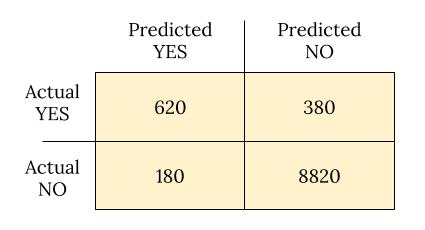
Now comes our first batch of definitions.
- True positive (TP): Positive test result matches reality — the person is actually sick and tested positive.
- False positive (FP): Positive test result doesn't match reality — the test is positive but the person is not actually sick.
- True negative (TN): Negative test result matches reality — the person is not sick and tested negative.
- False negative (FN): Negative test result doesn't match reality — the test is negative but the person is actually sick.
Folks get confused with these often, so here's a useful heuristic: positive vs. negative reflects the test outcome; true vs. false reflects whether the test got it right or got it wrong.
Since the rest of the definitions build upon these, here's the confusion matrix again now with them embedded:

Definition Soup
Armed with these and N for the total population (10,000, in our case), we are now ready to tackle the multitude of definitions statisticians have produced over the years to describe the performance of tests:
- Prevalence: How common is the actual disease in the population?
- (FN+TP)/N
- In the example: (380+620)/10000=0.1
- Accuracy: How often is the test correct?
- (TP+TN)/N
- In the example: (620+8820)/10000=0.944
- Misclassification rate: How often the test is wrong?
- 1 - Accuracy = (FP+FN)/N
- In the example: (180+380)/10000=0.056
- Sensitivity or True Positive Rate (TPR) or Recall: When the patient is sick, how often does the test actually predict it correctly?
- TP/(TP+FN)
- In the example: 620/(620+380)=0.62
- Specificity or True Negative Rate (TNR): When the patient is not sick, how often does the test actually predict it correctly?
- TN/(TN+FP)
- In the example: 8820/(8820+180)=0.98
- False Positive Rate (FPR): The probability of false alarm.
- 1 - Specificity = FP/(TN+FP)
- In the example: 180/(8820+180)=0.02
- False Negative Rage (FNR): Miss rate; the probability of missing a sickness with a test.
- 1 - Sensitivity = FN/(TP+FN)
- In the example: 380/(620+380)=0.38
- Precision or Positive Predictive Value (PPV): When the prediction is positive, how often is it correct?
- TP/(TP+FP)
- In the example: 620/(620+180)=0.775
- Negative Predictive Value (NPV): When the prediction is negative, how often is it correct?
- TN/(TN+FN)
- In the example: 8820/(8820+380)=0.959
- Positive Likelihood Ratio: Odds of a positive prediction given that the person is sick (used with odds formulations of probability).
- TPR/FPR
- In the example: 0.62/0.02=31
- Negative Likelihood Ratio: Odds of a positive prediction given that the person is not sick.
- FNR/TNR
- In the example: 0.38/0.98=0.388
The Wikipedia page has even more.
Deciphering our Example
Now back to the flu test example this post began with. RIDTs are said to have a sensitivity of 62.3%; this is just a clever way of saying that for a person with flu, the test will be positive 62.3% of the time. For people who do not have the flu, the test is more accurate since its specificity is 98.2% — only 1.8% of healthy people will be flagged positive.
The positive likelihood ratio is said to be 34.5; let's see how it was computed:
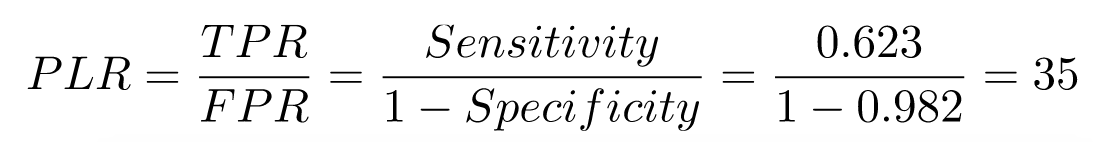
This is to say, if the person is sick, odds are 35-to-1 that the test will be positive. And the negative likelihood ratio is said to be 0.38:
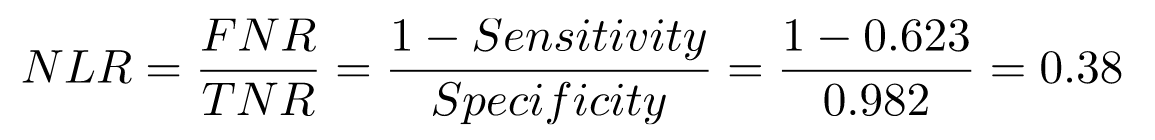
This is to say, if the person is not sick, odds are 1-to-3 that the test will be positive.
In other words, these flu tests are pretty good when a person is actually sick, but not great when the person is not sick — which is exactly what the quoted paragraph at the top of the post ends up saying.
Back to Bayes
An astute reader will notice that the previous sections talk about the probability of test outcomes given sickness, when we're usually interested in the opposite — given a positive test, how likely is it that the person is actually sick?
My previous post on the Bayes theorem covered this issue in depth. Let's recap, using the actual numbers from our example. The events are:
T: Test is positive.
T^C: Test is negative.
F: Person actually sick with flu.
F^C: Person doesn't have the flu.
Sensitivity of 0.623 means P(T|F) = 0.623; similarly, specificity is P(T^C|F^C) = 0/982. We're interested in finding P(F|T), and we can use the Bayes theorem for that:
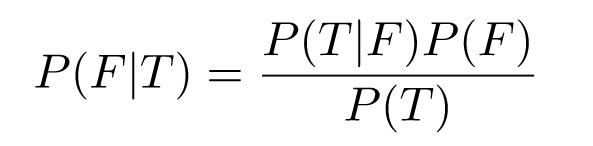
Recall that P(F) is the prevalence of flu in the general population; for the sake of this example, let's assume it's 0.1; we'll then compute P(T) by using the law of total probability as follows:
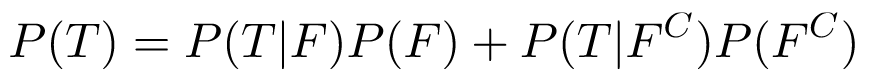
Obviously, P(T|C^C) = 1 - P(T^C|F^C) = 0.018, so:
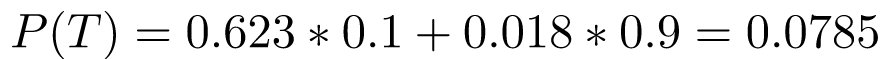
And then:
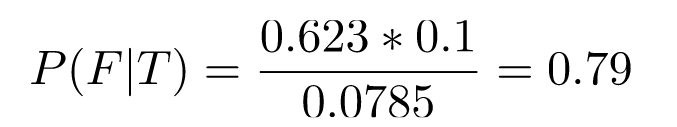
So, the probability of having flu given a positive test and a 10% flu prevalence is 79%. The prevalence strongly affects the outcome! Let's plot P(F|T) as a function of P(F) for some reasonable range of values:
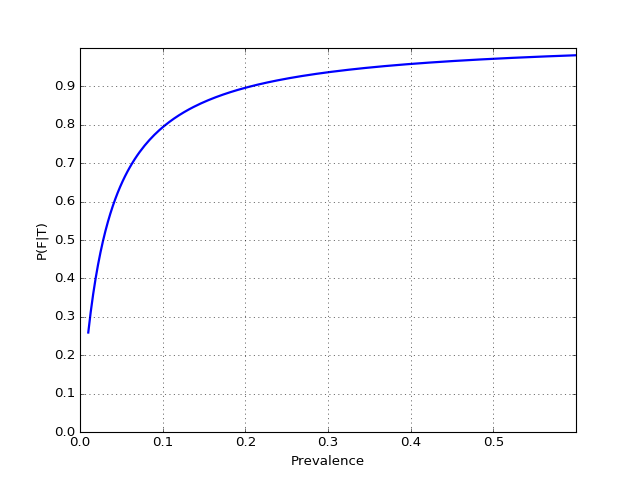
Note how low the value of the test becomes with low disease prevalence — we've also observed this phenomenon in the previous post; there's a "tug of war" between the prevalence and the test's sensitivity and specificity. In fact, the official CDC guidelines page for interpreting RIDT results discusses this:
When influenza prevalence is relatively low, the positive predictive value (PPV) is low and false-positive test results are more likely. By contrast, when influenza prevalence is low, the negative predictive value (NPV) is high, and negative results are more likely to be true.
And then goes on to present a handy table for estimating PPV based on prevalence and specificity.
Naturally, the rapid test is not the only tool in the doctor's toolbox. The flu has other symptoms, and by observing them on the patient, the doctor can increase their confidence in the diagnosis. For example, if the probability P(F|T) given 10% prevalence is 0.79 (as computed above), the doctor may be significantly less sure of the results if flu symptoms like a cough and fever are not demonstrated, etc. The CDC discusses this in more detail with an algorithm for interpreting flu results.
Published at DZone with permission of Eli Bendersky. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments