The Evolution of Systems Integration
Let's take a look at the evolution of Systems integration and also explore integrating systems by remote procedure calls.
Join the DZone community and get the full member experience.
Join For FreeIn the Beginning, There Was Nothing
If you think about it, standards and protocols start popping up after the task they’re meant to simplify has been around for a while and no two groups are doing it the same way. This holds true for software, a recent example being how mobile development became standardized, and you can now even create a single application that will work on all major OS's (it wasn’t too long ago when you had to use different technologies for different models of devices from the same company).
So, in the beginning, when the need for distributed computing appeared and different systems needed to communicate with each other, the first solutions weren’t exactly open. In the 70s, one of the first recorded system integration technologies was called EDI (Electronic Data Interchange). It was developed to allow companies to exchange valuable documents seamlessly with each other. There was no standard that could easily be implemented in any language. Instead, EDI provided a set of software tools that would let you perform the exchange. Another key aspect to EDI is the fact that the documents being exchanged had very specific and well-defined formats they were allowed to be in.
This is not like forcing XML into your message format, this is a protocol designed to exchange documents, yet these documents could only be transferred if they complied to one of the approved standards (the X12 Document list page in Wikipedia contains the full list).
Moreover, EDI allows for different transmission mediums, which is not that common, some of the most used integration protocols these days work on top of HTTP, but EDI works with HTTP and allows for channels like FTP, e-mail, AS1, and others.
Even though EDI has been around for over 40 years and forces the standard of the documents being transferred, it is used by many governments internally to share documents between organizations. The list of standards is also constantly updated, so new ones get added as soon as the need for them arises.
Integrating Systems by Remote Procedure Calls
RPC was developed during the 80’s and instead of integrating systems by allowing them to exchange digital documents, it allows distributed systems to integrate with each other by remotely executing procedures (or subroutines) as if it was all a single system.
Tracing the origin of this technology is a bit tricky, since some would say that there are theoretical implementation proposals that date back to the 70’s, but the first few practical implementations started appearing in the early 80’s. In fact, the term RPC is attributed to Bruce Jay Nelson, an American computer scientist in 1981.
That being said, RPC has one minor problem, which I would attribute to it being the first attempt at solving a problem that was very new at the time: the implementation is language dependant. In fact, some of the first implementations actually required the creation of dedicated programming languages, such as Lupine, the first actual practical implementation of RPC, developed at XEROX by Nelson and Andrew Birrel.
The first popular implementation of RPC was Sun’s RPC, now known as ONC RPC which was used as the basis for NFS (the Network File System).
How Does It Work?
You can distill RPC all the way down to a simple client-server communication protocol, in which the calling code acts as the client, and the executing subroutine acts as the server.
It was standardized by providing a simple way to replicate the interface for the remote procedure. An Interface Definition Language (or IDL for short) is used to define the interface, and with generators, you can grab these IDL files and generate your own client and server stubs in the language of your choice.
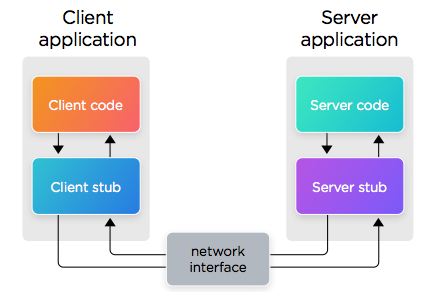
Simplified explanation of interaction between client and server during an PRC communication
The previous diagram provides more details on the different components involved in RPC communication. Although the details might vary from implementation to implementation, the basics of it are:
- The client application binds with the client stub, which is basically a “fake” instance of the remote procedure trying to be executed (same interface, but not the actual procedure).
- The client code executes the stub, sending it the required parameters.
- The client stub will marshal the parameters (which is fancy talk for “serialization”) and transmits them to the server stub.
- The server stub will, in turn, unmarshall the package (which again, is code for recreating the parameters from the received serialized package).
- The server stub will execute the server code, passing the received (and now unmarshaled) parameters.
The response from the procedure call will go through the same inverse process (marshalling, transmission over the network, unmarshalling and final reception by the client code) and land on the client.
One of the main drawbacks of this approach is that it tries to hide the non-locality of the server from the developer but has no way to handle network problems on its own. So, the developers need to write network error handling code, on the client-side, breaking the very illusion this approach initially intended to provide (that there is nothing between client and server).
A Step in the Right Direction
CORBA was born in the early 90’s as an attempt to bridge the gap left by RPC and other similar attempts. Even though they all had succeeded in communicating distributed systems, they had not been as successful providing heterogeneous ways to integrate systems built using different technologies. Some protocols were good for some languages, some others weren’t.
So, the Common Object Request Broker Architecture, as defined by the Object Management Group (OMG for short) was an attempt at providing a language and OS-agnostic way of allowing two CORBA-based systems to interact with each other.
At its core, you can say that CORBA is an object-oriented implementation of RPC that does not focus on the language used to create the system. It works in the same way RPC does, by creating and publishing IDLs of the shared services, although this particular IDL is designed and managed by OMG, and clients need to use them to create their stubs as well as the servers to create their skeletons (which would be the server stub from before). It also offers many other benefits such as:
- Heterogenous access: Language and OS freedom is one of the key winning features of CORBA over previous attempts at system integrations.
- Data-typing: The IDLs allowed developers to map the types between systems and considering this meant mapping between not entirely compatible technologies.
- Better transfer error handling: CORBA allowed applications to determine if a call had failed due to network problems or other issues.
- Finally, data compression while marshalling the parameters to be sent back and forth. This was developed by IONA, Remedy IT, and Telefonica, later added as part of the standard.
I Spy a Little API
For all the benefits that CORBA provided, once the W3C (the World Wide Web Consortium) released their XML specification, systems integration took a different direction. Suddenly, Microsoft was able to get major IT players, such as IBM, to start adopting their Simple Object Access Protocol (or SOAP for short), which they had created around 1998.
This time, the abstraction layer had been raised again, and instead of performing remote method invocation as if they were local, you were actually doing a remote request to an external service. This new protocol came with the following benefits over previous options:
- It was independent of the programming model used. It wasn’t bound to OOP or procedural programming.
- It was extensible. Updates and improvements could be added to the protocol over time in a seamless manner.
- It was neutral to the communication layer. SOAP could be implemented over any protocol such as HTTP, SMTP, TCP, and more.
After SOAP was defined, it became the basis for a much larger stack that would be used to define and consume Web Services. This stack was composed of:
- The Web Service Definition Language (WSDL) as the means of defining the interfaces of these services.
- SOAP as the messaging protocol used to transfer data from clients to servers and back.
- The Universal Description Discovery and Integration (UDDI) protocol, which allowed services across the globe to publish themselves in a centralized discovery platform, which allowed clients looking for those services to find them without having to know where they were.
The following diagram shows how the above elements interact with each other:
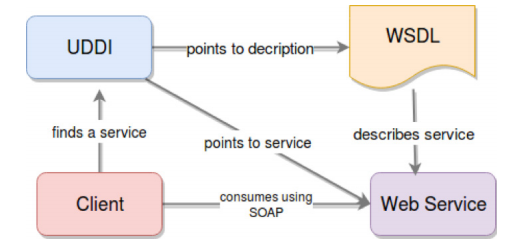
Simple explanation of the interactions between UDDI, client, and service
SOAP-based services took over the systems integration space for a while, XML was the new standard in town and it came with some much-needed benefits, such as:
- Flexibility. You could use XML for anything you wanted, so your services were both defined by it and transferred their data using it. This simplified development by only requiring users to understand and parse one language.
- Validation. By defining and using XML Schemas, you could verify correctness in your messages using another standard. This simplified the task of creating ad-hoc validations for new services, since having a standard validation language led to the creation of validation tools and libraries across all languages.
- Human readable. This was a major benefit at the time. Other solutions would use binary protocols to encode their data, making it impossible for humans to directly read it and validate the format and correctness of it. By having a structure that made its messages human readable it provided developers with a better experience by reducing debugging times.
Eventually, XML and the cumbersome format SOAP imposed on its messages would become one of its main drawbacks as well, and other leaner options would take its place.
REST Is the New SOAP
Even though they both coexist, and a lot of legacy services are still using SOAP-based web services, for the past 5 to 10 years there’s been a tendency of moving away from SOAP and into REST.
REST stands for REpresentational State Transfer and is a way of thinking about systems integration based on resources, instead of actions. We’ve been moving away from procedure and method calls to remote action calls using SOAP and now, we’re even moving away from actions and into resources. The philosophy behind REST is that your services are based around resources your clients need to interact with, and all you need to transfer between client and server is the state of such resources, nothing else.
This is not a protocol nor a style guide for web services, it is merely an architectural style defined by Roy Fielding in his 2000 doctoral dissertation. His proposal defined REST to work on top of HTTP leveraging its features, such as response codes (2xx and 3xx for success responses, 4xx for client errors, and 5xx for server errors), verbs (such as GET, POST, PUT, and others) and others. Over time, it was established that HTTP is just one of the many protocols REST can be implemented on.
The other key aspect from REST that has not been the case for previous integration solutions is that it doesn’t force the format of the data being transferred during the client-server communication. In fact, it welcomes different representations of the same resource’s state, so you can have RESTful services speaking XML while others returning binary representations of their resources. At the same time, you can even have the same service, providing two versions of the same resource. In the end, it is up to the service and client to agree on the best representation to use. This led to the adoption of a much lighter and leaner way to send information back and forth over HTTP: JSON. You could even state that this adoption got a bit out of hand since now, many developers actually believe JSON is part of the definition of REST and thus, a requirement for a service to be RESTful (which is not the case if you read Fielding’s paper).
Although many developers will swear over REST, like in all aspects of software development, there is no such a thing as a silver bullet, and like in all cases before it, REST has its drawbacks:
- It usually requires the client to make several round trips to get all the information it needs if it has to pull data from several resources.
- The latency added by HTTP can be a problem in some critical systems.
- If your service cannot be structured around resources, forcing REST on it will not yield the ideal result.
- The interaction between client and server is inherently asynchronous, creating problems when you need to have socket-like communication between your client and server.
The New Kid in Town
Now, we'll discuss the current state of systems integration: GraphQL.4 It is defined as a Query language for your APIs, and it simplifies a task that was not as straightforward with REST: querying your resources. It was originally created by Facebook, but being open source5, there are many organizations improving it.
What GraphQL basically provides is a querying language for your resources, one that is strongly typed, so errors can be caught sooner rather than later (which is what happens with loosely typed systems, such as REST). In this case, both requests and their respective responses are JSON-based, but clients are allowed to define exactly what information they want on their response, including related resources (with REST you either had to implement some sort of ad-hoc solution or simply have your client do many requests to get all of that).
The architecture proposed by GraphQL enables the back-end to provide a single entry point, which can be queried to get any of the available resources. It can also act both as a simple “database wrapper” in the sense you’re creating a service that queries a database and your interface to the world is GraphQL, and it can also act as an integrator, fetching data from several remote sources and combining it together before sending the response back to the client.
In Summary
Like I stated at the beginning of this article, system integration has been around ever since the first two systems needed to talk to each other. The technologies used and the methodologies related to them have evolved over time, and new and exciting ways to perform these tasks are developed every year.
That being said, just because EDI has been around ever since the 70s, or just because REST is “better” than SOAP, it doesn’t really mean those technologies aren’t used anymore. In fact, they’re very much used due to older tech companies not updating systems either because doing so would be too disruptive to their business or just because it would be too expensive to do. So, don’t be surprised if you happen to find some of these dinosaurs in the wild during your next project!
Opinions expressed by DZone contributors are their own.
Comments