The GPT-5 Impact
The focus of this article is to talk about the fast pace of change in models and the consequent updates we need to make to our LLM-powered solution design.
Join the DZone community and get the full member experience.
Join For FreeChatGPT happened. A host of models happened. Improvements continue to come out at an accelerated pace. The focus of this small article is to see if we can keep pace with our designs and remain both efficient and relevant to the latest and greatest.
I don't have a host of Elo benchmarks and ratings to evaluate these models. All I have is a small design for solving Math and Science problems that has generally kept me honest and grounded, whether it was using Cursor or Windsurf, or lately, GitHub CoPilot to write code, or in the choice of models (GPT-4o was clearly my favorite up until today!).
Evolution
Every other weekend, the design below kept improving while the focus was almost always to basically read up Math (and Science) chapters, keep the concepts handy, solve Q&A papers, and keep the correlation with what is taught in the books (using the concepts).
My design evolved with GPT-4o, but it wasn't very agentic until this point. I had the concept of 'Engine' carved out here to basically perform a more deterministic set of operations, and then an Orchestrator that managed it all.
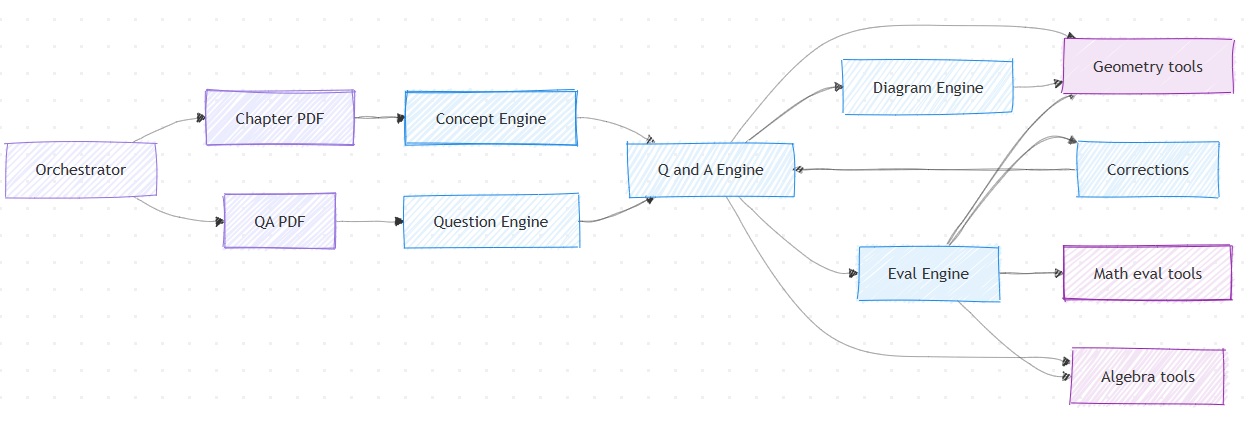
The first and significant change I noticed with GPT-5 was its ability to draw geometric diagrams and solve quadratic equations much better than its predecessors. That said, I did want some level of validation and deterministic capabilities with my tools and ended up re-evaluating the design at a tooling level on the following lines.
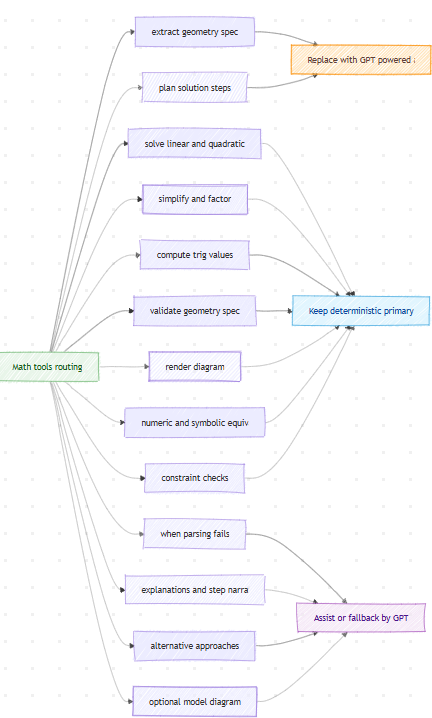
Early days yet - but as you can see above, I am giving myself the headroom to slowly wean off the current volume of 'tools' in a staggered manner - on these lines.
- Move the obvious ones out, such as extracting the geometric specifications, and creating an equation can be simply moved out.
- Hold the deterministic ones for now - such as validating the coefficients of a solved equation; applying the right scale to a trigonometric diagram; staying within the bounds of what was taught by the 'concepts' originally sourced from the textbook, etc.
- Plan for the more complex questions; those that span across Chapters, concepts are yet to be fully tested, but given all the Math and Science benchmarks scaled by GPT-5, I am hoping that solving a Composite question paper should slowly become easier and better with this alternative.
Before we move on to the agentic alternative, let us have a snapshot of the current solution's performance.
| Chapter | Items | Mean score | accepts | rate | % |
|---|---|---|---|---|---|
| Chapter7- Coordinate Geometry | 33 | 4.67 | 31 | 0.94 | 93.9 |
| Chapter8- Trigonometry | 36 | 4.56 | 29 | 0.81 | 80.6 |
| Chapter9- ApplyingTrigonometry | 16 | 4.38 | 11 | 0.69 | 68.8 |
| Chapter10- Circles | 17 | 4.76 | 15 | 0.88 | 88.2 |
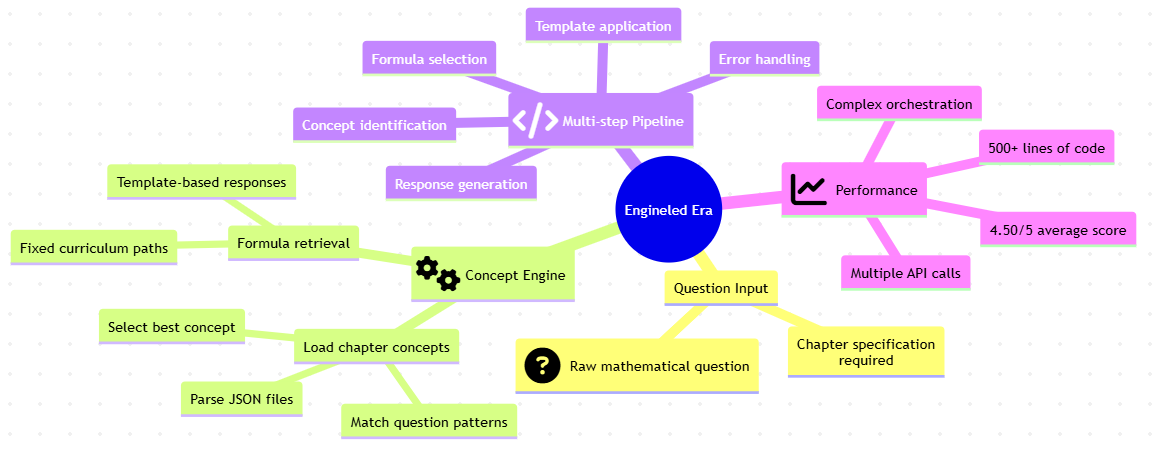
The current code flow is captured in this mind map.
Step 1: In the Evolution — Agentic With GPT-4o
As a logical first step, I created the agentic approach with the same model used above, just to get an apples-to-apples comparison due to the design change. The approach could be abstracted as shown below.
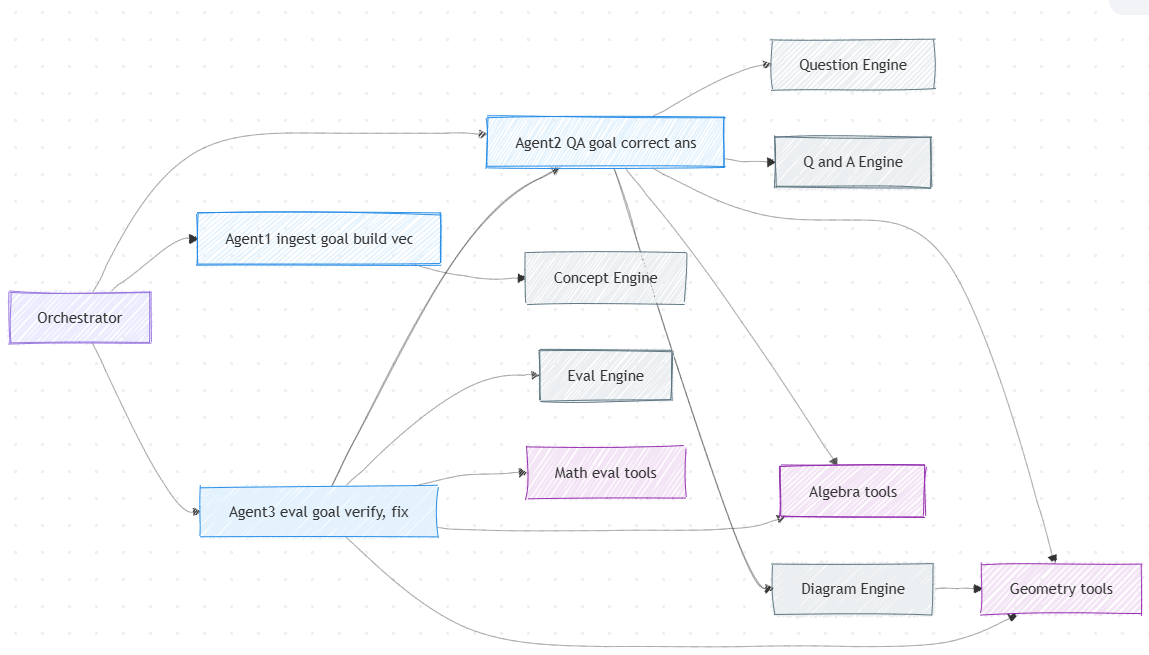
The newfound autonomy with the agents enables them to run through a solution, from identifying the right concept to the right solution, and then to a final evaluation, with a little more freedom than before. Core components of the solution that could be reused in the form parsing engines, tools have been taken forward, naturally.
The evaluation of the responses across 20 questions, five from each of the four chapters, was based on the following factors.
Evaluation Matrix
| Evaluation Dimension | Criteria | Score Range | Weight |
|---|---|---|---|
| Mathematical Correctness | Final answer accuracy and computational precision | 0-5 | Primary |
| Solution Approach | Appropriateness and efficiency of chosen method | 0-5 | Primary |
| Step-by-Step Clarity | Logical progression and explanation quality | 0-5 | Secondary |
| Formula Application | Correct identification and usage of relevant formulas | 0-5 | Secondary |
| Concept Integration | Connection to underlying mathematical principles | 0-5 | Tertiary |
Step 2: GPT-5 for the Same Questions
The approach with GPT-5 was as follows. There was a clear reduction in the volume of code and conditions that went into orchestration.
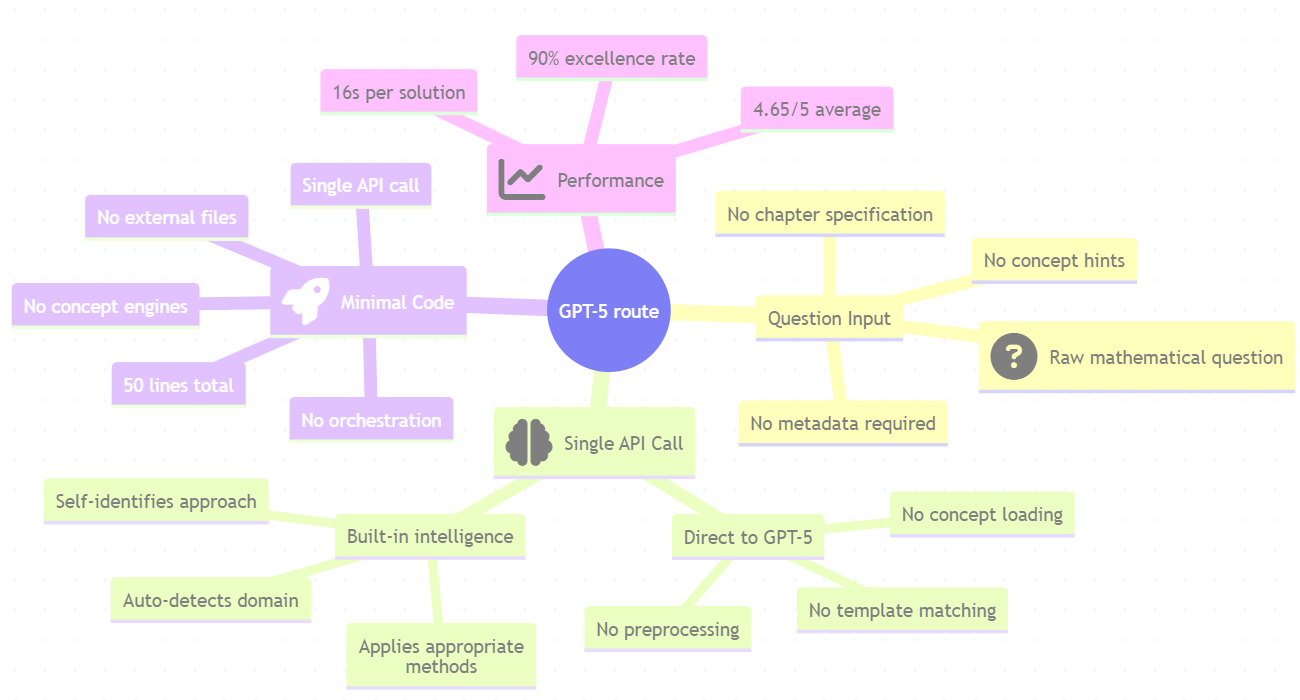
Evaluation Results
| Stage | Score | Improvement |
|---|---|---|
| Stage 1 - Engine led | 4.50/5 | Baseline |
| Stage 2 - Agentic (GPT-4o) | 4.55/5 | +1.1% |
| Stage 3 - Agentic (GPT-5)* | 4.65/5 | +3.3% |
*Honestly, I expected GPT-5 to get all 20 questions right to the T!
Other Changes Brought Forward By This Design
- Reduced codebase: with GPT-5 handling a wider range of deterministic and probabilistic steps internally, I could retire several helper scripts (especially around parsing and equation validation).
- Cleaner orchestration: fewer calls to external “tools” meant the Orchestrator’s job became more supervisory than managerial.
- Better resilience: GPT-5 was able to recover from missteps in intermediate steps (e.g., mislabeled equations, incomplete geometric specifications) without needing my fallback validation engines every time.
Summary
We’re all told that change is constant — but in the LLM/GPT-powered world, that change comes with acceleration. The velocity of improvements means that even code written just a few months ago can feel redundant today.
My next step is to expand this analysis across all chapters and question types, not just the sampled set. If the improvement trends I’ve seen with GPT-5 hold up, I’ll share the results in a follow-up post. The main lesson so far: stay ready to experiment, and be willing to rethink even the core of a design — provided the model and use case allow for it.
Closing Thoughts
For this entire journey — from design through implementation — I leaned on GitHub Copilot Chat and agent assistants. I haven’t benchmarked the underlying models across tools like Windsurf or Cursor in a structured way, but one observation stood out: Claude Sonnet 4 seemed to handle large context windows more reliably than most. In practice, this meant fewer iteration errors when working in its “agent” mode.
It’s early days still, but the direction is clear: as models keep evolving, so must our designs.
Opinions expressed by DZone contributors are their own.
Comments