The Modern Era of Data Orchestration: From Data Fragmentation to Collaboration
By embracing composability, organizations can position themselves to simplify governance and benefit from the greatest advances happening in our industry.
Join the DZone community and get the full member experience.
Join For FreeEditor's Note: The following is an article written for and published in DZone's 2024 Trend Report, Data Engineering: Enriching Data Pipelines, Expanding AI, and Expediting Analytics.
Data engineering and software engineering have long been at odds, each with their own unique tools and best practices. A key differentiator has been the need for dedicated orchestration when building data products. In this article, we'll explore the role data orchestrators play and how recent trends in the industry may be bringing these two disciplines closer together than ever before.
The State of Data Orchestration
One of the primary goals of investing in data capabilities is to unify knowledge and understanding across the business. The value of doing so can be immense, but it involves integrating a growing number of systems with often increasing complexity. Data orchestration serves to provide a principled approach to composing these systems, with complexity coming from:
- Many distinct sources of data, each with their own semantics and limitations
- Many destinations, stakeholders, and use cases for data products
- Heterogeneous tools and processes involved with creating the end product
There are several components in a typical data stack that help organize these common scenarios.
The Components
The prevailing industry pattern for data engineering is known as extract, load, and transform, or ELT. Data is (E) extracted from upstream sources, (L) loaded directly into the data warehouse, and only then (T) transformed into various domain-specific representations. Variations exist, such as ETL, which performs transformations before loading into the warehouse. What all approaches have in common are three high-level capabilities: ingestion, transformation, and serving. Orchestration is required to coordinate between these three stages, but also within each one as well.
Ingestion
Ingestion is the process that moves data from a source system (e.g., database), into a storage system that allows transformation stages to more easily access it. Orchestration at this stage typically involves scheduling tasks to run when new data is expected upstream or actively listening for notifications from those systems when it becomes available.
Transformation
Common examples of transformations include unpacking and cleaning data from its original structure as well as splitting or joining it into a model more closely aligned with the business domain. SQL and Python are the most common ways to express these transformations, and modern data warehouses provide excellent support for them. The role of orchestration in this stage is to sequence the transformations in order to efficiently produce the models used by stakeholders.
Serving
Serving can refer to a very broad range of activities. In some cases, where the end user can interact directly with the warehouse, this may only involve data curation and access control. More often, downstream applications need access to the data, which, in turn, requires synchronization with the warehouse's models. Loading and synchronization is where orchestrators play a role in the serving stage.
Figure 1. Typical flow of data from sources, through the data warehouse, out to end-user apps
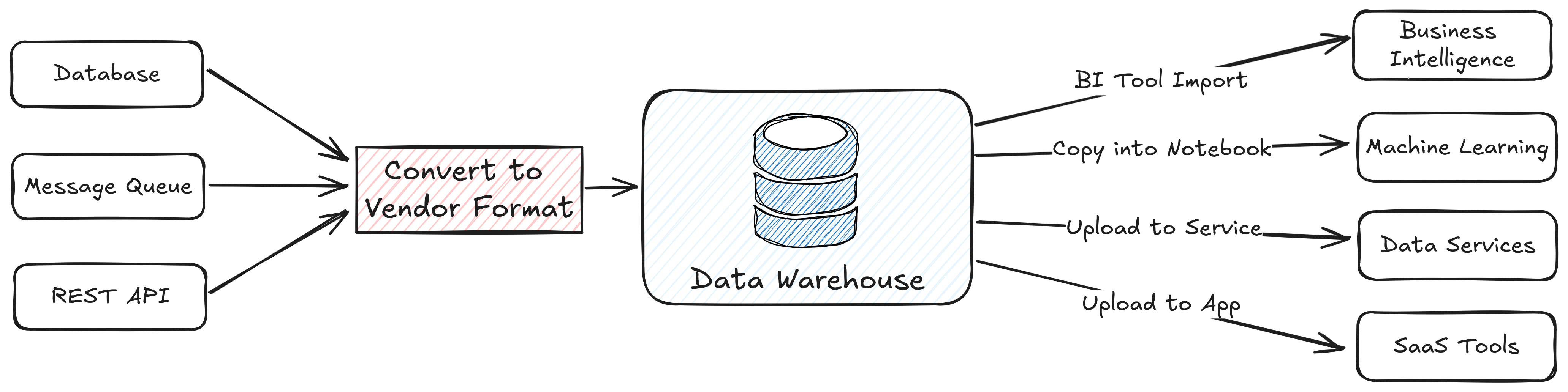
Ingestion brings data in, transformation occurs in the warehouse, and data is served to downstream apps.
These three stages comprise a useful mental model for analyzing systems, but what's important to the business is the capabilities they enable. Data orchestration helps coordinate the processes needed to take data from source systems, which are likely part of the core business, and turn it into data products. These processes are often heterogeneous and were not necessarily built to work together. This can put a lot of responsibility on the orchestrator, tasking it with making copies, converting formats, and other ad hoc activities to bring these capabilities together.
The Tools
At their core, most data systems rely on some scheduling capabilities. When only a limited number of services need to be managed on a predictable basis, a common approach is to use a simple scheduler such as cron. Tasks coordinated in this way can be very loosely coupled. In the case of task dependencies, it is straightforward to schedule one to start some time after the other is expected to finish, but the result can be sensitive to unexpected delays and hidden dependencies.
As processes grow in complexity, it becomes valuable to make dependencies between them explicit. This is what workflow engines such as Apache Airflow provide. Airflow and similar systems are also often referred to as "orchestrators," but as we'll see, they are not the only approach to orchestration. Workflow engines enable data engineers to specify explicit orderings between tasks. They support running scheduled tasks much like cron and can also watch for external events that should trigger a run. In addition to making pipelines more robust, the bird's-eye view of dependencies they offer can improve visibility and enable more governance controls.
Sometimes the notion of a "task" itself can be limiting. Tasks will inherently operate on batches of data, but the world of streaming relies on units of data that flow continuously. Many modern streaming frameworks are built around the dataflow model — Apache Flink being a popular example. This approach forgoes the sequencing of independent tasks in favor of composing fine-grained computations that can operate on chunks of any size.
From Orchestration to Composition
The common thread between these systems is that they capture dependencies, be it implicit or explicit, batch or streaming. Many systems will require a combination of these techniques, so a consistent model of data orchestration should take them all into account. This is offered by the broader concept of composition that captures much of what data orchestrators do today and also expands the horizons for how these systems can be built in the future.
Composable Data Systems
The future of data orchestration is moving toward composable data systems. Orchestrators have been carrying the heavy burden of connecting a growing number of systems that were never designed to interact with one another. Organizations have built an incredible amount of "glue" to hold these processes together. By rethinking the assumptions of how data systems fit together, new approaches can greatly simplify their design.
Open Standards
Open standards for data formats are at the center of the composable data movement. Apache Parquet has become the de facto file format for columnar data, and Apache Arrow is its in-memory counterpart. The standardization around these formats is important because it reduces or even eliminates the costly copy, convert, and transfer steps that plague many data pipelines. Integrating with systems that support these formats natively enables native "data sharing" without all the glue code. For example, an ingestion process might write Parquet files to object storage and then simply share the path to those files. Downstream services can then access those files without needing to make their own internal copies. If a workload needs to share data with a local process or a remote server, it can use Arrow IPC or Arrow Flight with close to zero overhead.
Standardization is happening at all levels of the stack. Apache Iceberg and other open table formats are building upon the success of Parquet by defining a layout for organizing files so that they can be interpreted as tables. This adds subtle but important semantics to file access that can turn a collection of files into a principled data lakehouse. Coupled with a catalog, such as the recently incubating Apache Polaris, organizations have the governance controls to build an authoritative source of truth while benefiting from the zero-copy sharing that the underlying formats enable. The power of this combination cannot be overstated. When the business' source of truth is zero-copy compatible with the rest of the ecosystem, much orchestration can be achieved simply by sharing data instead of building cumbersome connector processes.
Figure 2. A data system composed of open standards
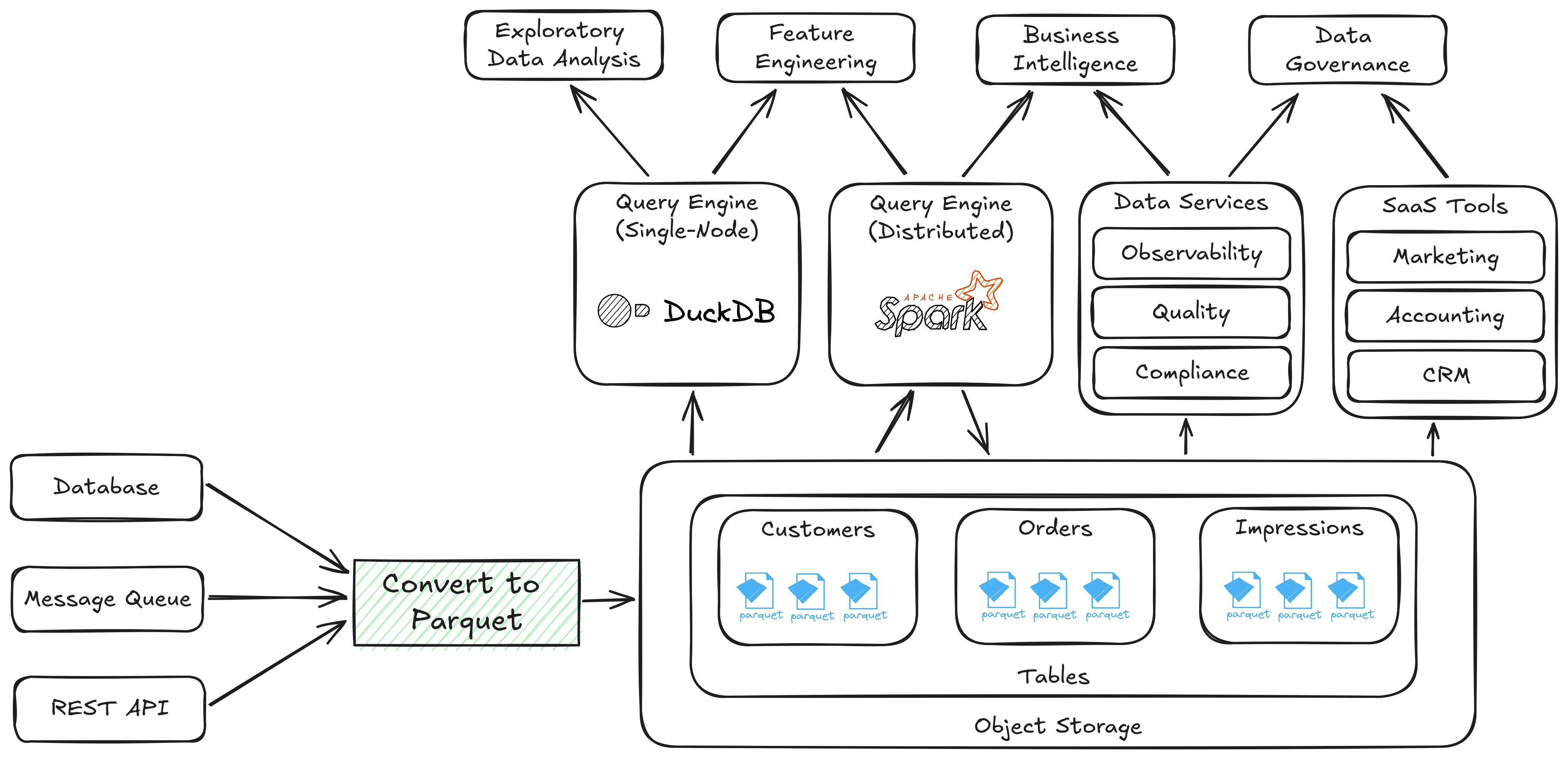
Once data is written to object storage as Parquet, it can be shared without any conversions.
The Deconstructed Stack
Data systems have always needed to make assumptions about file, memory, and table formats, but in most cases, they've been hidden deep within their implementations. A narrow API for interacting with a data warehouse or data service vendor makes for clean product design, but it does not maximize the choices available to end users. Consider Figure 1 and Figure 2, which depict data systems aiming to support similar business capabilities.
In a closed system, the data warehouse maintains its own table structure and query engine internally. This is a one-size-fits-all approach that makes it easy to get started but can be difficult to scale to new business requirements. Lock-in can be hard to avoid, especially when it comes to capabilities like governance and other services that access the data. Cloud providers offer seamless and efficient integrations within their ecosystems because their internal data format is consistent, but this may close the door on adopting better offerings outside that environment. Exporting to an external provider instead requires maintaining connectors purpose-built for the warehouse's proprietary APIs, and it can lead to data sprawl across systems.
An open, deconstructed system standardizes its lowest-level details. This allows businesses to pick and choose the best vendor for a service while having the seamless experience that was previously only possible in a closed ecosystem. In practice, the chief concern of an open data system is to first copy, convert, and land source data into an open table format. Once that is done, much orchestration can be achieved by sharing references to data that has only been written once to the organization's source of truth. It is this move toward data sharing at all levels that is leading organizations to rethink the way that data is orchestrated and build the data products of the future.
Conclusion
Orchestration is the backbone of modern data systems. In many businesses, it is the core technology tasked with untangling their complex and interconnected processes, but new trends in open standards are offering a fresh take on how these dependencies can be coordinated. Instead of pushing greater complexity into the orchestration layer, systems are being built from the ground up to share data collaboratively. Cloud providers have been adding compatibility with these standards, which is helping pave the way for the best-of-breed solutions of tomorrow. By embracing composability, organizations can position themselves to simplify governance and benefit from the greatest advances happening in our industry.
This is an excerpt from DZone's 2024 Trend Report,
Data Engineering: Enriching Data Pipelines, Expanding AI, and Expediting Analytics.
Read the Free Report
Opinions expressed by DZone contributors are their own.
Comments