Third-Generation Data Platforms: The Lakehouse
The lakehouse represents the next evolution of data platforms, aiming to combine the best of both data warehouses and data lakes.
Join the DZone community and get the full member experience.
Join For FreeData Platform Evolution
Initially, data warehouses served as first-generation platforms primarily focused on processing structured data. However, as the demand for analyzing large volumes of semi-structured and unstructured data grew, second-generation platforms shifted their attention toward leveraging data lakes. This resulted in two-tier architectures with problematic side effects: complexity of maintaining and synchronizing the two tiers, data duplication, increased risks of failure due to data movement between warehouses and data lakes, and so on.
Data lakehouses are third-generation platforms created to address the above limitations. Lakehouses are open, cost-efficient architectures combining key benefits of data lakes and data warehouses. They do their magic by implementing a metadata layer on top of data lakes.
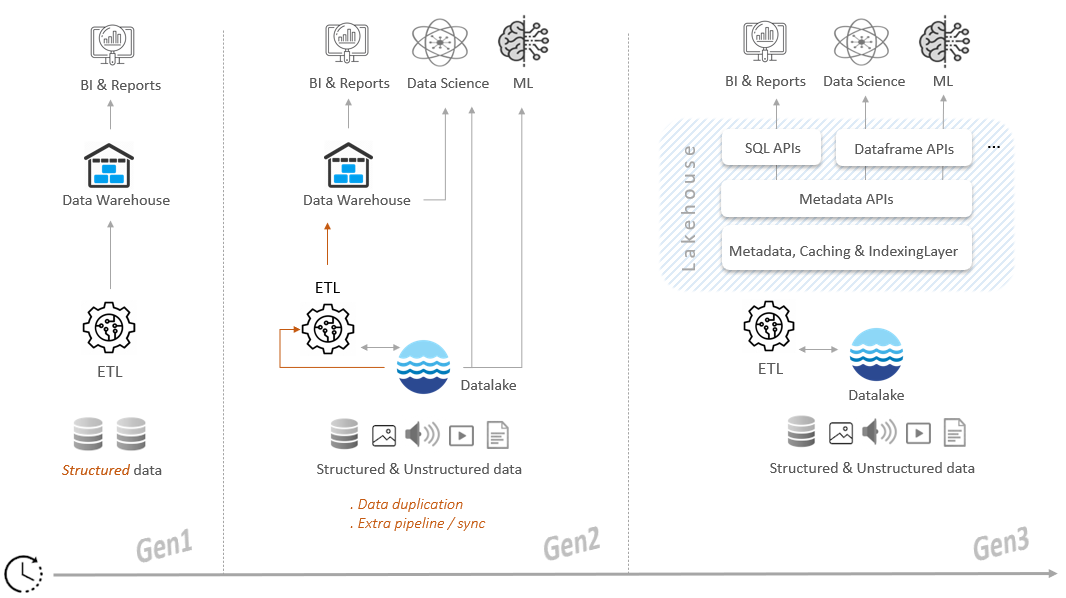
The metadata layer is the defining element of the lakehouse. It brings structure and management capabilities similar to those of traditional warehouses into the data lake: transactional support (ACID), time travel, schema enforcement and evolution, data governance, access controls, and auditing. The lakehouse also enables real-time analytics, business intelligence (BI), data science, and machine learning (ML) by providing APIs for data processing activities and allowing the use of a vast array of languages and libraries.
Lakehouse Platforms
Although it is theoretically possible to design one's own lakehouse architecture, the general recommendation would be to use an already existing solution, just to save time, money, and headaches.
The various technologies competing in the lakehouse market can be classified into two main categories:
- Cloud-agnostic platforms, e.g. Databricks and Snowflake, both available in Azure, AWS, and GCP.
- Cloud-native platforms, such as Microsoft Fabric, AWS Glue, or the GCP lakehouse.
Cloud-agnostic platforms alleviate cloud provider lock-in issues. However, if organizations are already using a number of services within a specific cloud provider, going with a cloud-native solution instead might cause less integration headaches. That said, cloud-agnostic platforms have been providing an increasing number of tools to facilitate communications with other services, like connectors, APIs, and data sharing protocols.
There are likewise trade-offs in considering SaaS (Software-as-a-Service) vs. PaaS (Platform-as-a-Service). SaaS brings convenience and minimal administration at the price of less flexibility, even though the latter is partially addressed by providing connectors, interoperable data formats, exchange marketplace, etc.
Metadata and Table Formats
At the schema layer, lakehouses use distinct table formats. The problem on what mechanism to use so that a bunch of files in the data lake can be viewed as one or more tables, was originally solved in the old Hadoop days by Apache Hive, using a direct directory-to-table mapping, with subfolders mapping to table partitions. Nowadays, there are several open-source table formats for lakehouses that approximate traditional data warehouses in functionality, such as Delta Lake, Apache Iceberg, and Apache Hudi. These Open Table Formats (OTF) are similar in that they all support the Parquet file format, provide ACID transactions, schema enforcement, and time travel. Of course, each OTF has its own approach to delivering those capabilities, although work is being done to make these formats compatible. The upcoming Delta Lake 3.0 for instance, aims to provide a Universal Format (UniForm) for all three OTF.

Right now, though, different eco-systems have varying levels of read and/or write support for one or more of these table formats. Taking AWS as an example, Amazon Redshift can read Hudi and Delta Lake, but not Iceberg. At this time, it has no write support for any of them. By contrast, AWS Glue has added native support for all three.
| Lakehouse | Platform type | Metadata layer |
|---|---|---|
| Databricks | PaaS, cloud-agnostic | Unity Catalog, Supported: Delta Lake (core), Hudi, Iceberg. |
| Snowflake | SaaS, cloud-agnostic | Information Schema, Proprietary table format. Supported: Iceberg, Delta Lake (read-only). |
| MS Fabric | SaaS, Azure cloud-native | MS Purview, Supported: Delta Lake (core), Hudi. |
| AWS Glue | PaaS, AWS cloud-native | Data Catalog, Supported: Delta Lake, Hudi, Iceberg. |
| GCP Lakehouse | PaaS, GCP cloud-native | Dataplex, Supported: Delta Lake, Hudi, Iceberg. |
Each of these lakehouses deserves its own dedicated article. We went through an initial overview of Microsoft Fabric previously. Subsequent articles will explore the other options.
Final Thoughts
The solutions provided by these platforms exhibit similar patterns of increasing openness and share a common understanding of the value of unstructured data for BI, AI, and ML.. At this stage, though, they still fall under the Work in Progress category. Snowflake is more of an evolved hybrid architecture. MS Fabric is in preview at this time, and has a number of known limitations. Databricks is arguably one of the more complete cloud-agnostic lakehouse solutions to-date, although there are other, similar alternatives (e.g., Starburst or Dremio) in this highly competitive market. Lakehouses are constantly evolving and maturing. In particular, the upcoming integration of AI (e.g. the new Databricks LakehouseIQ or Azure OpenAI Service) looks promising.
Published at DZone with permission of Tony Siciliani. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments