Thriving Amid Giants: A Guide for Small Players in the LLM Search Engine Market
This article briefly explains what language models are and how small players in this exciting space build sustainable products that can survive the competition.
Join the DZone community and get the full member experience.
Join For FreeThere's been a lot of chatter around Chat GPT. In this article, I'm briefly explaining what language models are, how Chat GPT differs from other language models, and how small players coming into this exciting space build sustainable products that can survive the competition.
What Are Language Models?
Language modeling is at the core of Natural language processing, trying to predict the probability of the following sequence of words given the past sequence of words in a text. E.g., The model tries to learn that the word "blue" is more likely to follow the sequence of words "The water is clear and the sky is <>" than the words red/green/ocean, etc. Suppose the model can learn the next sequence of words/sentences/characters. In that case, this model can be used in various tasks like Autocomplete, speech recognition, machine translation, text generation, etc., along with other classification models.

Here's a good primer on What language models are. In this article, I want to focus on what the recent advancements in Large language model research mean for Startups and engineers building out their companies in this space.
How Is ChatGPT Trained?
Open AI launched the ChatGPT demo in December. Deep learning-based language models are not entirely new. There are at least 80 different language models released over the past six months, differing in how they are trained, what they are trained on, and the task they are optimized for. What makes ChatGPT unique is that it uses Reinforcement learning with human feedback in training the language model. This article does a great job of explaining how RLHF was used to train ChatGPT. Let me touch up on that briefly.
- You start with pre-training a language model. This is a supervised learning problem because, in your model, you provide inputs and output from a known corpus of text. i.e., you know what the "next" sequence of words is going to be for a given training sample, and you allow your model to learn just that.
- Next, with a language model, one needs to generate data to train a reward model, which is how human preferences are integrated into the system. This is where Reinforcement learning is incorporated along with Human Feedback. Human feedback here refers to human raters looking at the model output and assigning a rank (if they think the model output makes sense w.r.t to the input). So you train an RL model where you provide a certain input -> see how the model outputs and have the human raters reward the model. Likewise, the Reinforcement learning model basically tries to learn from the environment(human raters) depending on the rewards it sees.
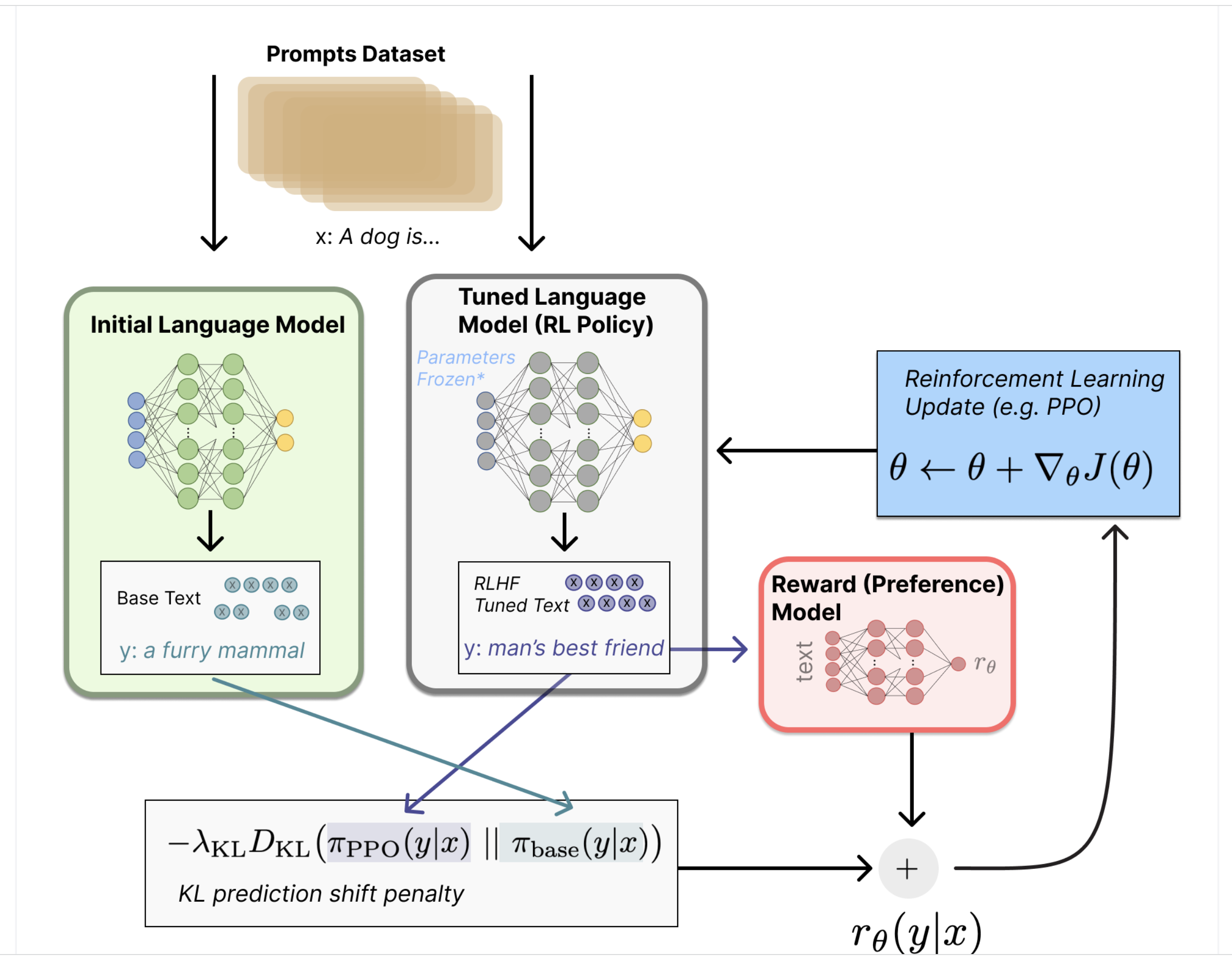
- In the next step, you train another RL model called the Policy model. Imagine there are like two towers. For the first tower, you take the language model trained in Step 1. Then, you train a new RL model for the second tower, which looks for Rewards from the model trained in Step 2). You start with the same input to the Pre-trained and Policy models and try to minimize the reconstruction loss (KL Divergence) of both towers. The reward function (Model trained in step 2) is also used to update parameters for the second tower. In this manner, for each prompt that you keep providing the model, you can continuously make the Policy model better and better.
Now that we have seen how ChatGPT was trained, let me talk about the main challenges.
LLM models are incredibly resource intensive to train and run inference on. From the above process, you can imagine that this model has billions of parameters and also requires tons of human raters to keep bettering the model. This is quite an expensive process that a smaller player coming into the market must wait to reproduce. This is quite unlike other Deep learning state-of-the-art models of the yesteryears. When Alexie was released in 2014, People had access to the Pytorch code. The data to train on was small enough to load into a single GPU. You could re-train the model and reproduce the results of the paper. BERT was released in 2018 and had only a 0.3Billion parameters. 4 years later. We have Chat GPT with 175 billion parameters. This list has a good set of Language models trained by different Big tech and has details on which of them are public etc.
Re-training is difficult. Running inference is also expensive. Imagine the CPU cost that would incur when you try to make a model inference over 150 billion parameters (that's 150 billion + matrix multiplications).
What Does This Mean for Smaller Startups Who Want to Build the Next Search Engine, the Next AI Assistant, or the Next Question Answering System?
Money spent on running inference per query is expensive to keep up for small players. Without an effective monetization strategy, a startup that's going to build search engines will burn through the runway fast. The kind of financial moat that requires to pull off a search engine rests with the big powers.
Google/Facebook/Microsoft have the moat to survive. But Search is an area that even big tech needs help with monetization. FB has workplace search and blue-app Search both came with their set of challenges. They are sitting on tons of user data and user-generated content that enables personalization and real-time ML and are areas that only big tech can excel at. Personalization is a big driver in boosting successful search metrics. Smaller players need both of them.
So how can small players win — when you don't have access to a financial moat to power your models, when you don't have user data to make Search personalized, and when your product can be replicated in a jiffy? Here are some of my thoughts!
1. Product Innovation

2. Focus On One Domain and Build an Enterprise Product Out of It
Like a search engine assistant for doctors/lawyers — The model is built only with the literature of a particular domain, hence can generalize to that domain better even with a few million parameters. Therefore it is not going to burn cash for every inference. Most importantly- adoption is sticky. A doctor using your real-time assistant to most likely stick with it for their lifetime. (There's a huge first-mover advantage to domain-specific Search. Remember how Epic systems is still the web software for 90% of hospitals).
3. Pick One Problem and Get Better at It
Text summarization is a different problem than Document search, and Conversational AI is a different problem from both of them. All of these can be powered by LLMs. A baseline attempt at combining all can introduce less reliable results and often BS kind of answers. Startups building out in this space should pick one problem. Build a product around it and optimize for precision. This means if you build a search engine, then have tight constraints on mean reciprocal rank (consider only the rank of the first five items). If building a text summarizer, build a model with the best ROUGE scores out there. This effort is going to not just come with building a big model but often bootstrapping your evaluation process with tons of raters, also incorporating trust and safety to prevent misinformation. Then you have a good chance!
4. The Future of Generative AI Is Bright, and This Is Just the Beginning for Generative AI
There's a lot of attention on txt2tx and img2txt. If you are just getting started building an AI avatar app or a Real-time chat assistant, or a copy.ai clone, you are already behind. We have yet to get started with other models of input. Generating Music, text-to-video scenes, txt to videos will come soon. Before the end of 2023, we will get to Music and videos, which will be more prevalent. Internationalization is another beast that is less RoI for large companies to look at immediately. Building search engines for local languages is another great idea that can monetize well and get ahead of the game!!
2023 is going to be an exciting year to watch for. With the rapid progress in scaleable MLOps and State of the art models, we are in AI or Tech wonderland. The time to ideate and bootstrap and get a product running has dramatically reduced. Now, it remains to see how companies would innovate to differentiate their product offering and make them more defensible against replication and copypastas. The journey has just begun!
Opinions expressed by DZone contributors are their own.
Comments