Time Series for Developers: What the Heck Is Time-Series Data?
This post seeks to illustrate the power of time-series data by looking at a real-world scenario using a public dataset from the New York Taxi & Limousine Commission.
Join the DZone community and get the full member experience.
Join For FreeDevelopers and companies use time-series data every day whether they know it or not. Whether you're capturing data from IoT sensors, analyzing past market performance, monitoring cloud or application infrastructure, or running an on-demand food delivery app, time-series data helps your business run. But what exactly is time-series data and how is it useful?
This post seeks to provide answers to those questions and illustrate the power of time-series data in action by looking at a real-world scenario using a public dataset from the New York Taxi & Limousine Commission. First, let’s dive into a few basic concepts to lay the foundation for the queries we’ll write and analyze in the “Let’s Code” section.
A Memorable (Not-So-Theoretical) Time-Series Data Definition

At a fundamental level, time-series data represents how something changes over time. That “something” could be a system, process, behavior, or object.
When people talk about time-series data, they’re referring to a situation where every data point has a time-stamp associated with it, and we capture and keep all data points about the system, process, behavior, or object in question. Rather than overwriting previous data, we use the time-stamp to distinguish between values (e.g., when something occurred is as — if not more — important than the value itself).
This leads us to two defining characteristics of time-series data:
- Time is the principal axis for time-series data (i.e, the X-axis on a graph)
- Time-series data is
INSERTS, notUPDATES(i.e., we don’t overwrite data)
To summarize, time-series data represents change over time, where we treat time as the primary axis of our data and new data points are treated as an INSERT not an UPDATE.
You might also be interested in reading: Working With Time Series Data
Here’s a fun thought exercise: If you think about it, all data is time-series data!
If you're anything like me, this may lead to you say, "Wait, what!? What about....?", as you try to think of a counter example of data not being time-series in nature. However, to this day, I still can’t think of one. This is because all data inherently occurs at some point in time (and time only goes forward as far as we know).
If we “throw away” or disregard the time element of our data, we lose valuable information. Conversely, when we view our data as time-series data, we (and our teams) are able to make better sense of how the world and things we care about are changing.
How Can Time-Series Data Help Me?
Time-series data is important because by capturing how things change over time, time-series data turns data points into data stories.
We can bucket why time-series data is useful into 3 categories.
Time series data helps people:
- Analyze the past
- Monitor the present
- Plan for and predict the future
Let’s look at an example to drive that home. Most, if not all of us, have received a package from Amazon, DHL, UPS, FedEx, or some other package delivery service. By now, it shouldn’t surprise you that your package delivery information is time-series data!
The table below shows how a package delivery company could (and should) use their data to:
Analyze past |
Monitor present |
Predict future |
|
Package delivery company (Amazon, DHL, FedEx, etc.) |
Analyze historical delivery data to optimize delivery routes |
Monitor real-time package location and delivery status |
Use historical data to predict delivery volume and times, give realistic expectations to customers, and manage capacity planning (e.g., staffing enough drivers during peak times). |
Because all data can be time-series in nature, companies and teams of all sizes — from small startups and contributors to open source projects to large multi-million dollar companies — can and should leverage time-series data.
Now that we’ve got some theory and definitions out the way, let’s get practical and take a look at a real example.
Let’s Code: NYC Taxicab Data
I work out of Timescale’s New York City office, so I’m using an example of something I, and people who live in big cities, see every day: taxis. This example will illustrate how time-series data helps us analyze the past.
The scenario below is taken from Hello NYC, a 3 part tutorial about analyzing New York City taxicab data using PostgreSQL and Timescale. No prior knowledge aside from basic SQL knowledge is needed to complete the tutorial.
The Scenario
New York City has set a goal to reduce its greenhouse gas emissions by 20% by 2024.* Given the number of taxi rides taken each day, they believe studying past taxi rider history will play a major factor in helping them achieve this goal.
The New York Data Team* has recruited you to help them make sense of historical taxi ride data, draw insights, and use your analysis to plan for the future. Your goal is to conduct an analysis of all NYC TLC taxi rides taken in January 2016.
*Note: This is a fictional scenario. However, we’ve designed this scenario and related goals to realistically reflect the questions real city planning organizations may ask of their data and the methods used to answer those questions.
Dataset
We’re going to be looking at a dataset of all taxi rides taken in New York City during January 2016. The data comes from the New York City Taxi and Limousine Commission (NYC TLC)’s publicly available datasets. The NYC TLC is the agency responsible for licensing and regulating New York City’s Yellow Taxi cabs and other for hire vehicles. The NYC TLC has over 200,000 licensee vehicles completing about 1 million trips each day – that’s a lot of trips!
They collect the following data about each ride:
- Pickup date and time (as a timestamp)
- Pickup location (latitude and longitude)
- Drop off date and time (as a timestamp)
- Drop off location (latitude and longitude)
- Trip distance (in miles)
- Fares (in USD)
- Passenger count
- Rate type (e.g standard, airport. For more see RateCodeID in this doc)
- Payment type (Cash, credit card. For more see Payment_type in this doc)
Part 1 of the Hello NYC tutorial examines the design of the schema used to store this data in a PostgreSQL database more closely, so you can refer to it if you’d like more detail. However, let’s look at an overview below so that we can get familiar with it.
To make the data easily usable, we’ve set up three tables to store ride data:
1 regular Postgres table called
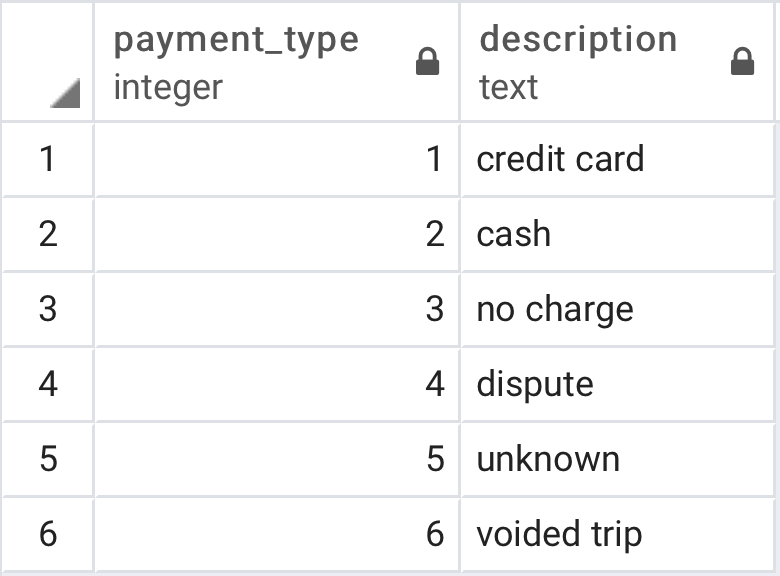
payment_types, which maps the numeric payment type codes to an English description (e.g. credit card, cash, etc.)
xxxxxxxxxx
SELECT * FROM payment_types
1 regular Postgres table called
rates, which maps the numeric rate codes to an English description (e.g., standard ride, JFK airport ride, Newark Airport ride, etc.).
xxxxxxxxxx
SELECT * FROM rates

1 Timescale hypertable called
rides, which stores all of the above data that the NYC TLC collected for the passenger rides in 2016, the period in question. Hypertables behave just like regular Postgres tables, but are optimized under the hood to automatically partition time-series data for efficiency and performance.
xxxxxxxxxx
SELECT * FROM rides
LIMIT 3;
xxxxxxxxxx
-[ RECORD 1 ]---------+---------------------------------------------------
vendor_id | 1
pickup_datetime | 2016-01-02 06:27:50
dropoff_datetime | 2016-01-02 06:39:17
passenger_count | 1
trip_distance | 4.30
pickup_longitude | 0
pickup_latitude | 0
rate_code | 1
dropoff_longitude | 0
dropoff_latitude | 0
payment_type | 2
fare_amount | 14
extra | 0
mta_tax | 0.5
tip_amount | 0
tolls_amount | 0
improvement_surcharge | 0.3
total_amount | 14.8
pickup_geom | 01010000207308000058937DADD91162413BC2471015063241
dropoff_geom | 01010000207308000058937DADD91162413BC2471015063241
-[ RECORD 2 ]---------+---------------------------------------------------
vendor_id | 1
pickup_datetime | 2016-01-02 08:59:50
dropoff_datetime | 2016-01-02 09:06:20
passenger_count | 2
trip_distance | 0.70
pickup_longitude | 0
pickup_latitude | 0
rate_code | 1
dropoff_longitude | 0
dropoff_latitude | 0
payment_type | 2
fare_amount | 6
extra | 0
mta_tax | 0.5
tip_amount | 0
tolls_amount | 0
improvement_surcharge | 0.3
total_amount | 6.8
pickup_geom | 01010000207308000058937DADD91162413BC2471015063241
dropoff_geom | 01010000207308000058937DADD91162413BC2471015063241
-[ RECORD 3 ]---------+---------------------------------------------------
vendor_id | 1
pickup_datetime | 2016-01-01 06:05:30
dropoff_datetime | 2016-01-01 06:11:48
passenger_count | 2
trip_distance | 2.00
pickup_longitude | 0
pickup_latitude | 0
rate_code | 1
dropoff_longitude | 0
dropoff_latitude | 0
payment_type | 2
fare_amount | 8
extra | 0
mta_tax | 0.5
tip_amount | 0
tolls_amount | 0
improvement_surcharge | 0.3
total_amount | 8.8
pickup_geom | 01010000207308000058937DADD91162413BC2471015063241
dropoff_geom | 01010000207308000058937DADD91162413BC2471015063241
Now that we’re more familiar with the database tables and schema, it’s time to start analyzing the data!
In this section, we’re going to write queries to answer the following questions and discuss how the results might apply to real world situations.
- What is the daily average fare for rides with 2+ passengers?
- How many rides took place by ride type?
Question 1: What is the average fare amount for 2+ passengers?
This is an example of a query you see often in time-series analysis, where you want to track statistics about a subset of data.
We’d perform this as follows:
xxxxxxxxxx
-- Q: What is the daily average fare amount for rides with 2 or more passengers
SELECT date_trunc('day', pickup_datetime) as day, avg(fare_amount)
FROM rides
WHERE passenger_count > 1 AND pickup_datetime < '2016-02-01'
GROUP BY day ORDER BY day;
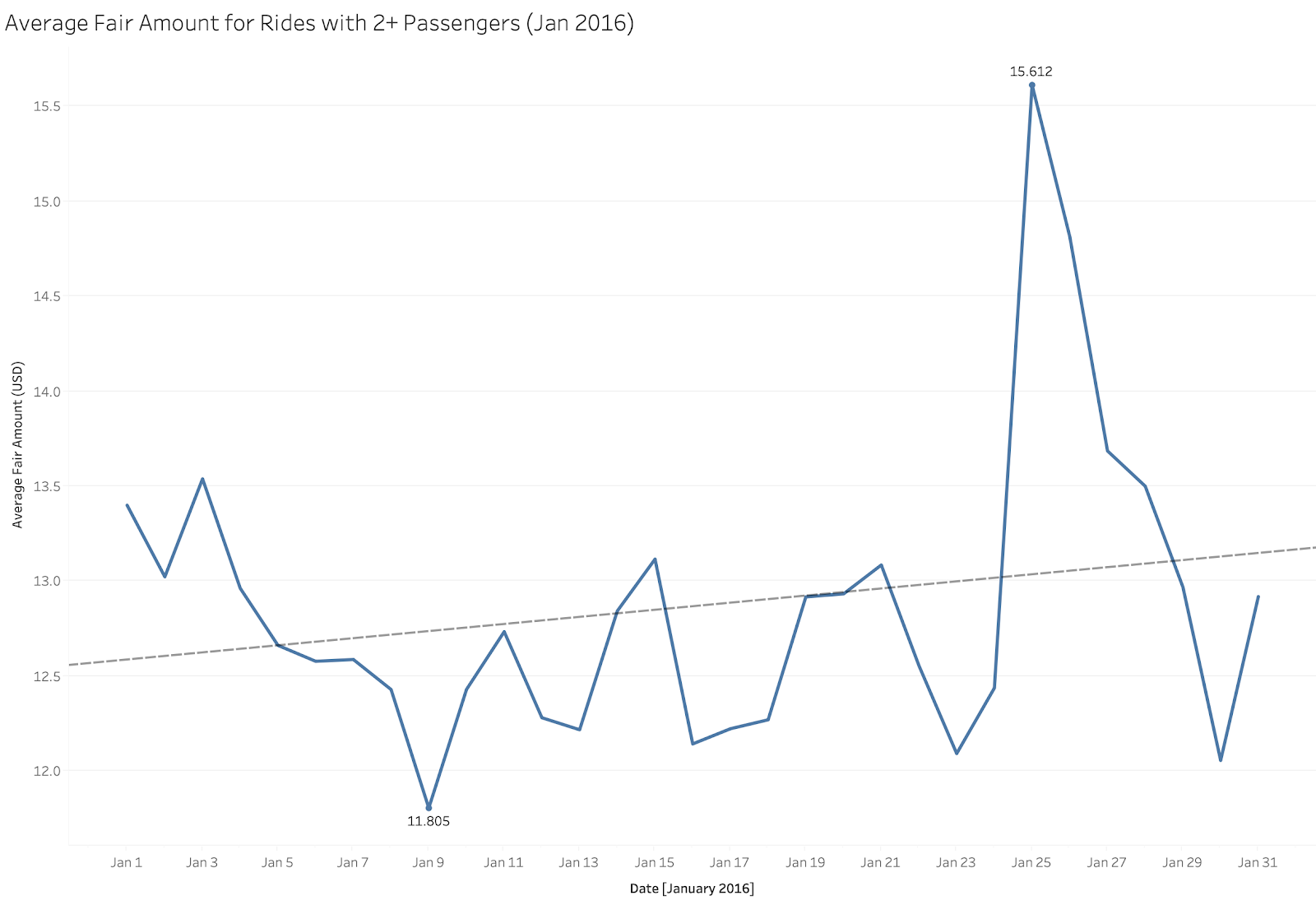
In this case, if rides with 2+ passengers is a type of ride we care about a lot, we’re able to track statistics about it and see how they change over time. Moreover, we’d probably investigate what happened during the week of 23-30 January 2016 that caused the spike in average fare price to $15.61. This idea of querying, analyzing, and viewing subsets you care about also applies to other scenarios, like analyzing key customer segments or popular product configurations.
Question 2: How many rides took place by each rate type?
This question asks for a breakdown of rides by rate type over time. This is a common example of tracking different segments of users or customers and how they grow over time.
We’d perform this as follows:
xxxxxxxxxx
-- Q: How many rides of each rate type took place in the month?
SELECT rate_code, COUNT(vendor_id) as num_trips
FROM rides
WHERE pickup_datetime < '2016-02-01'
GROUP BY rate_code ORDER BY rate_code;
We get the following output, which shows how many rides of each rate code took place:
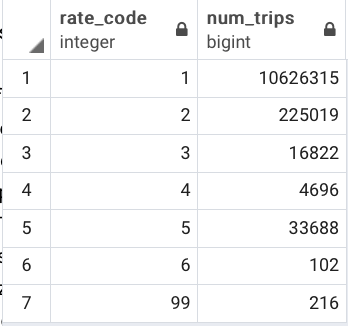
While that’s technically correct, we want something more human readable. To do that, we can use the power of SQL JOINS, so let’s modify the query we have:
xxxxxxxxxx
-- How many rides of each rate type took place?
SELECT rates.description, COUNT(vendor_id) as num_trips
FROM rides
JOIN rates on rides.rate_code = rates.rate_code
WHERE pickup_datetime < '2016-02-01'
GROUP BY rates.description ORDER BY num_trips desc;
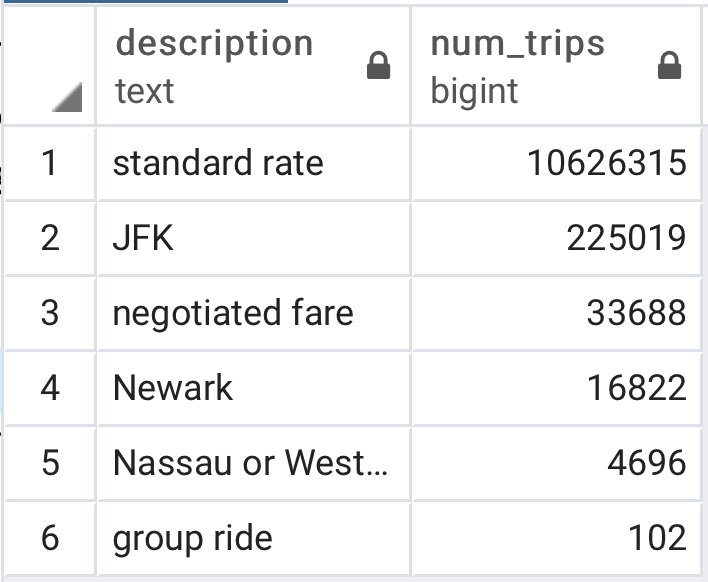
From here, we can more easily interpret which ride types were most popular since we have more human-readable descriptions of the ride types, while still storing those ride types as integers in the database for flexibility.
We can see that the most popular ride types are the standard rate rides and rides to JFK International Airport, one of New York City’s three airports. We can also see how much more popular rides to JFK airport are than rides to Newark Liberty International Airport (another airport in the New York area), 13x more popular based on the number of rides to each destination.
This simple example — combining individual ride data and data mapping rate types to English descriptions — illustrates a powerful point: by combining your time-series data with your relational or business data, you can simplify analysis, uncover powerful insights for your project, app, or business, and make things more comprehensible to you, your team members, and your executives.
Conclusion and Next Steps
In this post, we answered the question “what the heck is time-series data?!” and we learned that time-series data represents how something changes over time. We also learned why time-series data is useful: it helps us analyze the past, monitor present, and predict and plan for the future. Lastly, we got a taste of how time-series data can help a real organization by analyzing NYC taxicab data with TimescaleDB (and performing JOINs over Timescale hypertables and regular PostgreSQL tables).
To continue learning more:
Finish the NYC Taxicab tutorial: Finish the 3 part tutorial we started above and answer to answer more complex questions that better help us understand the past, such as, “How many rides took place from Times Square on New Year's Day?” or that model the future, such as, “How can analyzing airport rides help us build a greener city?”
Opinions expressed by DZone contributors are their own.
Comments