Top 3 Snowflake Performance Tuning Tactics
The Snowflake Database has no indexes to build, no statistics to capture or partitions to manage. How do you tune Snowflake for maximum performance?
Join the DZone community and get the full member experience.
Join For Free
The Snowflake Data Warehouse has an excellent reputation as an analytics platform for blisteringly fast query performance but without indexes. So, how can you tune the Snowflake database to maximize query performance? This article explains the top three techniques to tune your system to maximum throughput, including data ingestion, data transformation, and end-user queries.
Snowflake Query Performance
One of my favorite phrases is: What problem are we trying to solve? As techies, we often launch into solutions before we even understand the true nature of the problem. The performance issues on any analytics platform generally fall into one of three categories:
- Data Load Speed: The ability to load massive volumes of data as quickly as possible.
- Data Transformation: The ability to maximize throughput, and rapidly transform the raw data into a form suitable for queries.
- Data Query Speed: This aims to minimize the latency of each query and deliver results to business intelligence users as fast as possible.
1. Snowflake Data Loading
Avoid Scanning Files
The diagram below illustrates the most common method of bulk loading data into Snowflake, which involves transferring the data from the on-premise system to cloud storage, and then using the COPY command to load to Snowflake.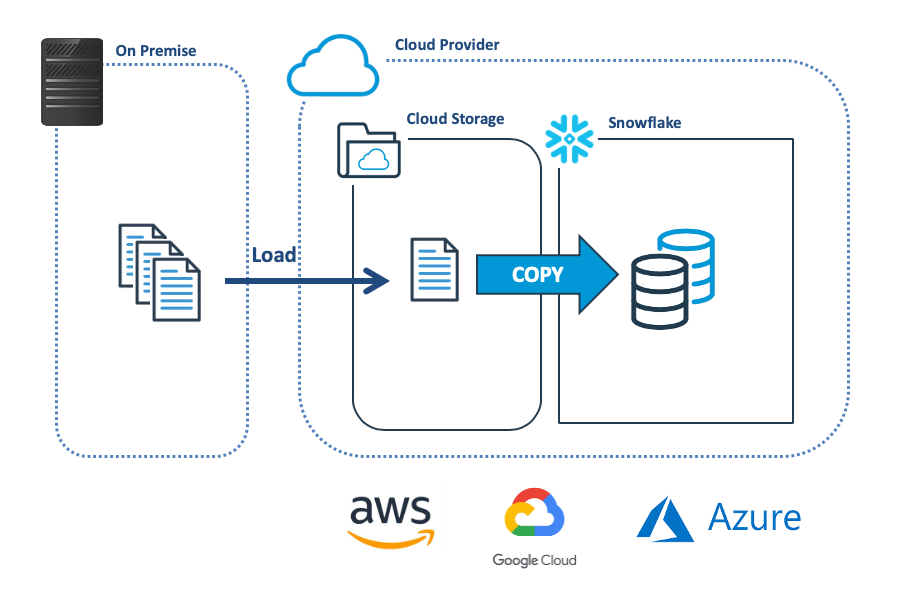
Before copying data, Snowflake checks the file has not already been loaded, and this leads the first and easiest way to maximize load performance by limiting the COPY command to a specific directory. The code snippet below shows a COPY using a range of options.
xxxxxxxxxx
-- Slowest method: Scan entire stage
copy into sales_table
from @landing_data
pattern='.*[.]csv';
-- Most Flexible method: Limit within directory
copy into sales_table
from @landing_data/sales/transactions/2020/05
pattern='.*[.]csv';
-- Fastest method: A named file
copy into sales_table
from @landing_data/sales/transactions/2020/05/sales_050.csv;
While the absolute fastest method is to name a specific file, indicating a wildcard is the most flexible. The alternative option is to remove the files immediately after loading.
Size the Virtual Warehouse and Files
The diagram below illustrates a common mistake made by designers when loading large data files into Snowflake, which involves scaling up to a bigger virtual warehouse to speed the load process. In reality, scaling up the warehouse has no performance benefit in this case.
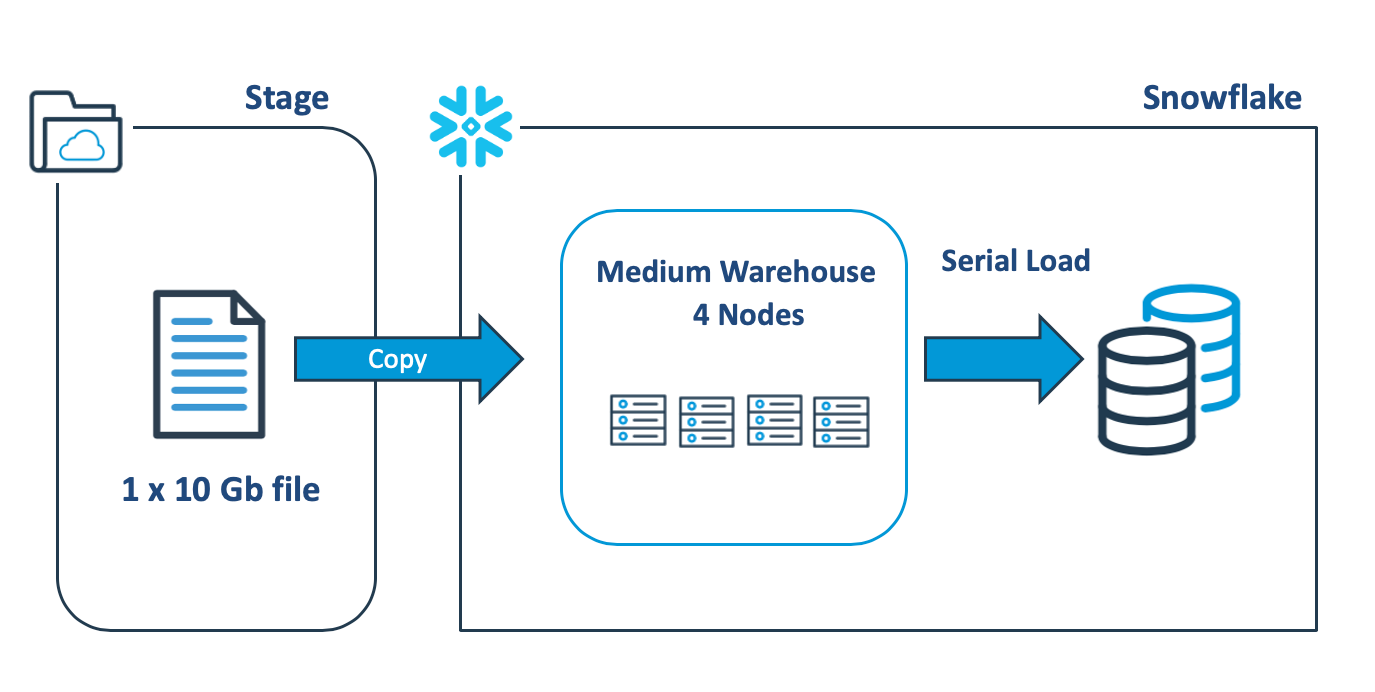
The above COPY statement will open the 10Gb data file and sequentially load the data using a single thread on one node, leaving the remaining servers idle. Benchmark tests demonstrate a load rate of around 9 Gb per minute, which is fast but could be improved.
The diagram below illustrates a better approach, which involves breaking up the single 10Gb file into 100 x 100Mb files to make use of Snowflake’s automatic parallel execution.
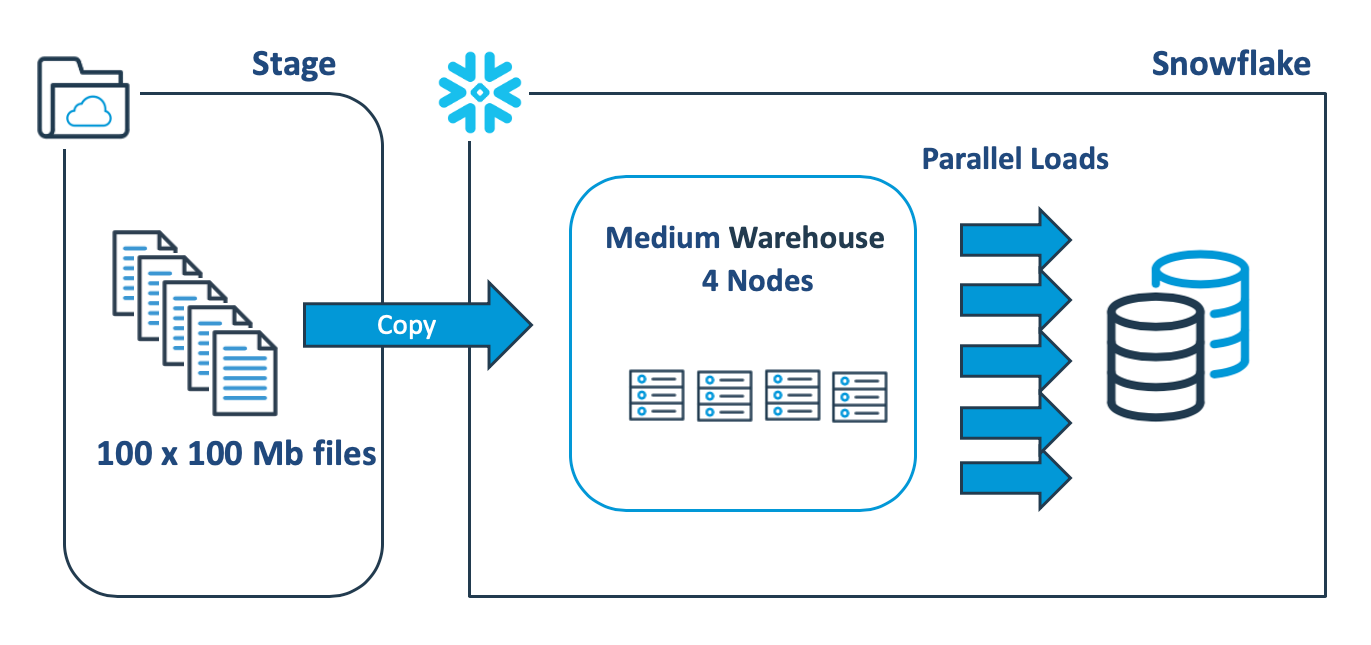
2. Snowflake Transformation Performance
Latency Vs. Throughput
While tuning the SQL is often the most effective way to reduce elapsed time, designers often miss an opportunity. In addition to reducing the latency of individual queries, it’s also vital to maximize throughput — to achieve the maximum amount of work in the shortest possible time.
The diagram below illustrates a typical data transformation pattern that involves executing a sequence of batch jobs in a virtual warehouse. As each task completes, the next task is started:
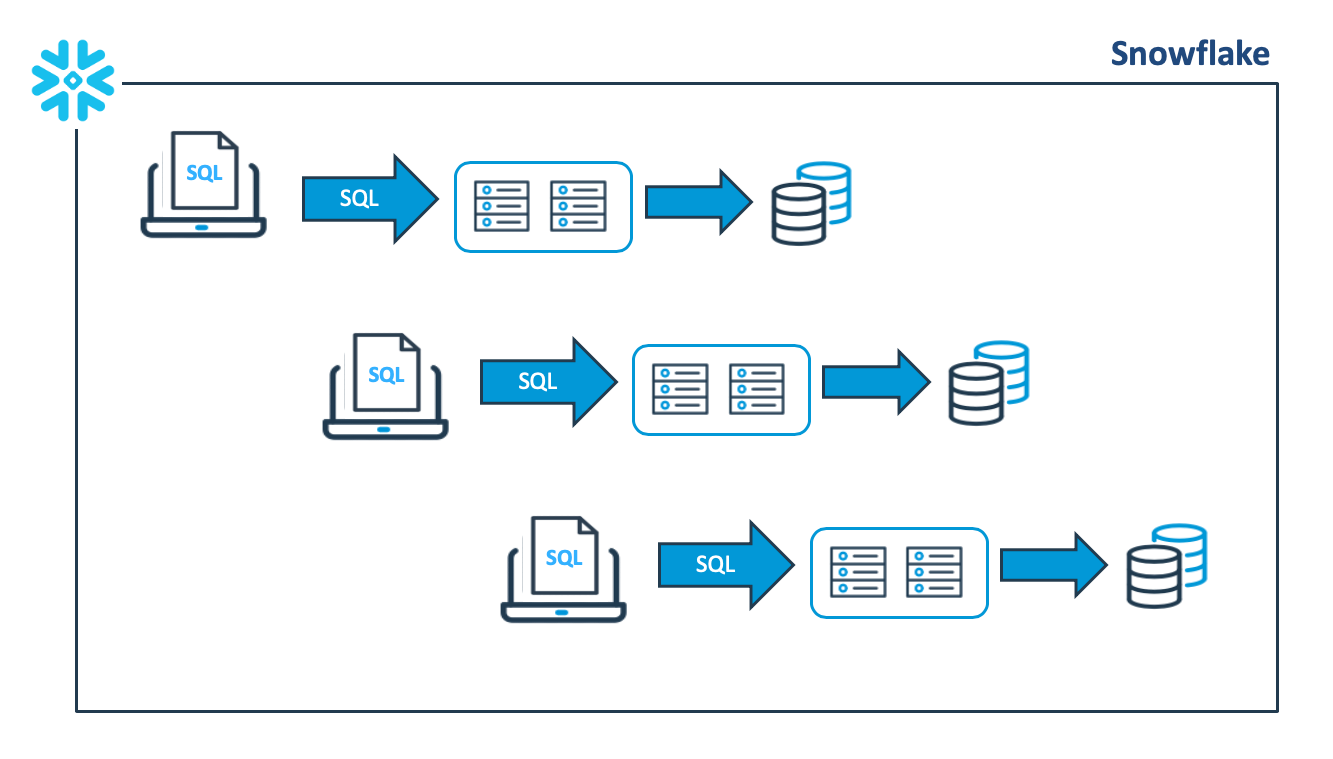
One obvious solution is to scale up to a bigger virtual warehouse to complete the work faster, but even this technique will eventually reach a limit. Furthermore, while it might improve query performance, there’s also a greater chance of inefficient use of resources on a larger warehouse.
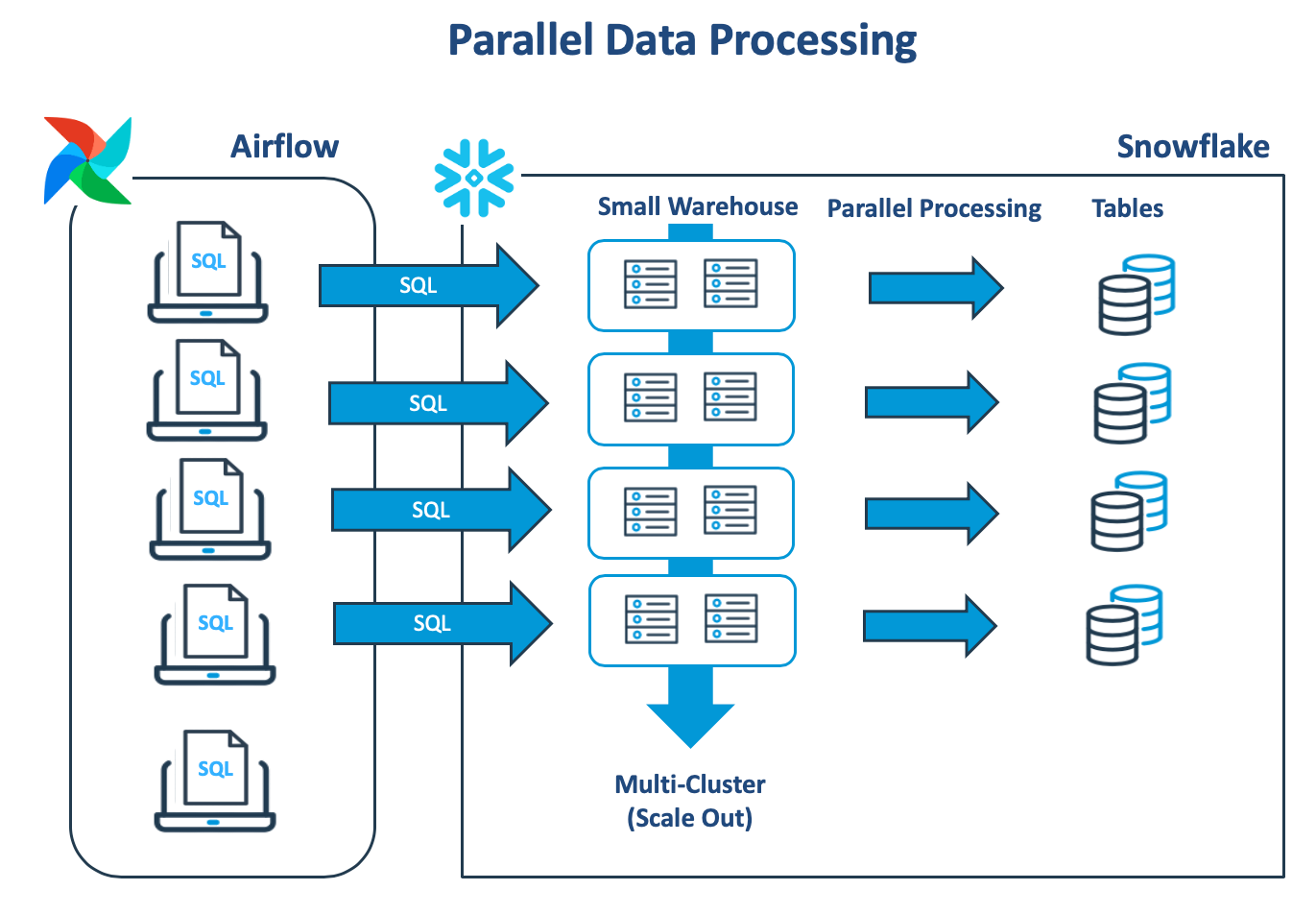
In the above example, Apache Airflow is used to execute multiple independent connections to Snowflake, and each thread runs a single task against the same virtual warehouse. As the workload increases, jobs begin to queue as there are insufficient resources available. However, the Snowflake multi-cluster feature can be configured to automatically create another same-size virtual warehouse, and this continues to take up the load.
As tasks complete, the above solution automatically scales back down to a single cluster, and once the longest job finishes, the cluster will suspend. This is by far the most efficient method of completing the work, and we still have the option of scaling up.
The SQL snippet below illustrates the command needed to create a multi-cluster warehouse, which will automatically suspend after 60 seconds idle time, but use the ECONOMY scaling policy to favor throughput and saving credits over individual query latency.
xxxxxxxxxx
-- Create a multi-cluster warehouse for batch processing
create or replace warehouse batch_vwh with
warehouse_size = SMALL
min_cluster_count = 1
max_cluster_count = 10
scaling_policy. = economy
auto_suspend. = 60
initially_suspended = true;
3. Tuning Snowflake Query Performance
Select the Required Columns
Like many other data analytics platforms, Snowflake uses a columnar data store which is optimized to fetch only the attributes needed for the specific query, and this is illustrated in the diagram below:
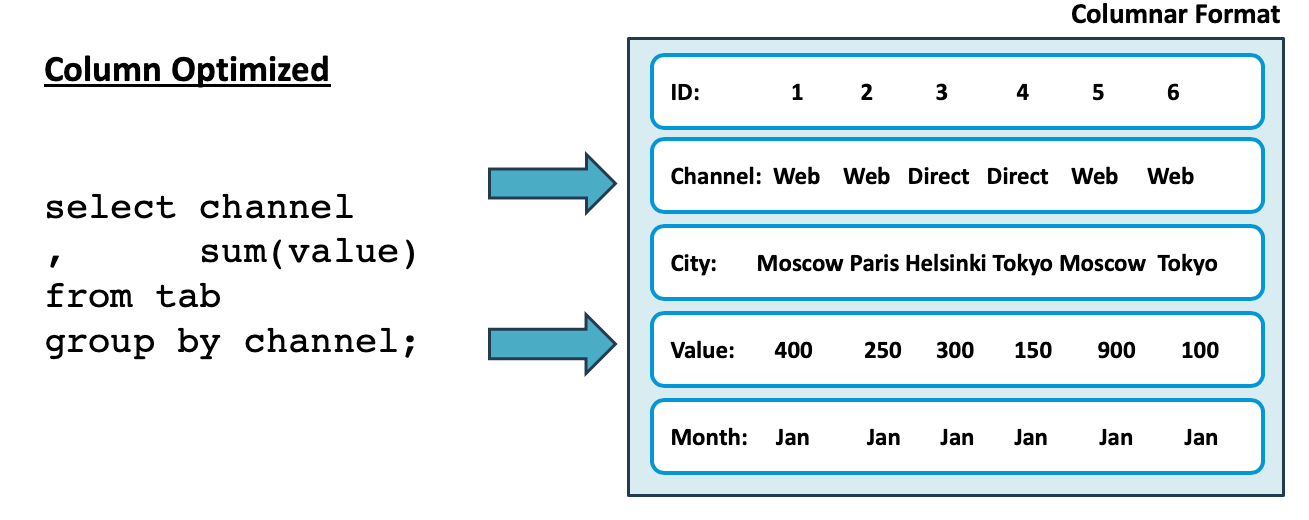
In the above diagram, the query fetches just two columns, and on a table with 100 columns, this will be 98% faster than a traditional row-store, which needs to read all the data from disk.
Maximize Cache Usage
The diagram below illustrates a vital component of the Snowflake internal architecture that it caches data in both the virtual warehouse and the cloud services layer.
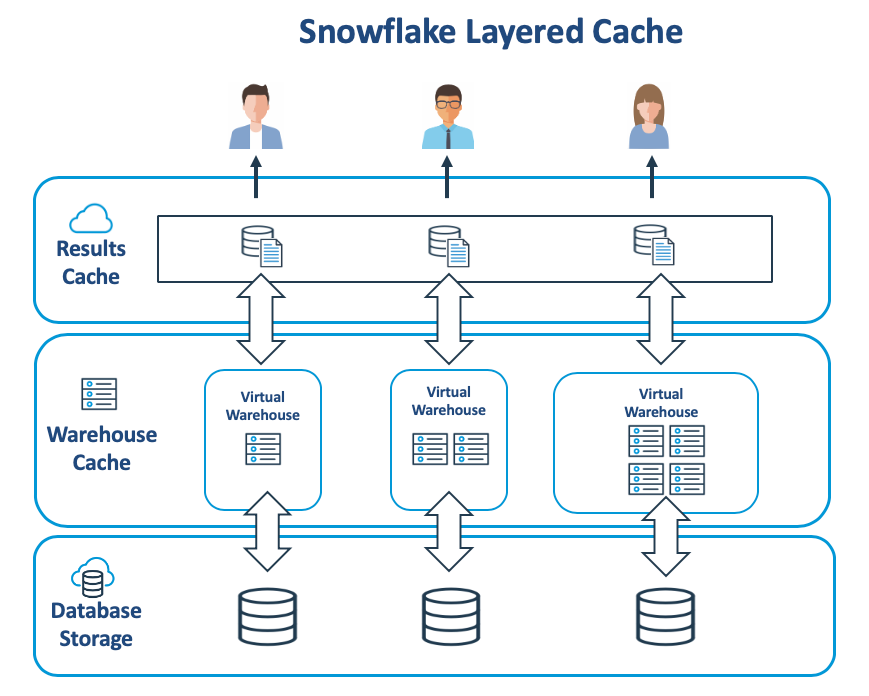
Business intelligence dashboards frequently re-execute the same query to refresh the screen showing changed values. Snowflake automatically optimizes these queries by returning results from the Results Cache with results available for 24 hours after each query execution.
Data is also cached within the virtual warehouse on fast SSD, but unlike the Results Cache, the virtual warehouse holds raw data which is aged out on a least recently used basis. While it’s not possible to directly adjust the virtual warehouse cache, it is possible to optimize usage with the following steps:
- Fetch required attributes: Avoid using SELECT * in queries as this fetches all data attributes from Database Storage to the Warehouse Cache. Not only is this slow, but it potentially fills the warehouse cache with data that is not needed.
- Scale Up: While you should never scale up to tune a specific query, it may be sensible to resize the warehouse to improve overall query performance. As scaling up adds additional servers, it spreads the workload and effectively increases the overall warehouse cache size.
- Consider Data Clustering: For tables over a terabyte in size, consider creating a cluster key to maximize partition elimination. This solution both maximizes query performance for individual queries and returns fewer micro-partitions making the best use of the Warehouse Cache.
xxxxxxxxxx
-- Identify potential performance issues
select query_id as query_id
, round(bytes_scanned/1024/1024) as mb_scanned
, total_elapsed_time / 1000 as elapsed_seconds
, (partitions_scanned /
nullif(partitions_total,0)) * 100 as pct_table_scan
, percent_scanned_from_cache * 100 as pct_from cache
, bytes_spilled_to_local_storage as spill_to_local
, bytes_spilled_to_remote_storage as spill_to_remote
from snowflake.account_usage.query_history
where (bytes_spilled_to_local_storage > 1024 * 1024 or
bytes_spilled_to_remote_storage > 1024 * 1024 or
percentage_scanned_from_cache < 0.1)
and elapsed_seconds > 120
and bytes_scanned > 1024 * 1024
order by elapsed_seconds desc;
The SQL snippet above can help identify potential query performance issues on queries that run for more than 2 minutes and scan over a megabyte of data. In particular, look out for:
- Table Scans: A high value of PCT_TABLE_SCAN and a large number of MB_SCANNED indicates potential poor query selectivity on large tables. Check the query WHERE clause and consider using a cluster key if appropriate.
- Spilling: Any value in SPILL_TO_LOCAL or SPILL_TO_REMOTE indicates a potentially large sort of operation on a small virtual warehouse. Consider moving the query to a bigger warehouse or scaling up the existing warehouse if appropriate.
Conclusion
A common misconception about Snowflake is the only solution available to improve query performance is to scale up to a bigger warehouse, but this is a poor strategy. In reality, the best approach depends upon the problem area, which is most often in ingestion, transformation, or end-user queries, and often the most effective solutions are based upon a design approach rather than pure query tuning.
By all means, consider scaling up to a large warehouse to improve query performance, but first identify and focus on the actual problem. You may find there are more effective and efficient solutions available.
Disclaimer: The opinions expressed in my articles are my own, and will not necessarily reflect those of my employer (past or present).
Want to Know More About Snowflake?
Leave a comment below, and tell me what you'd like to know about Snowflake? I'll check back and maybe write up an article.
Published at DZone with permission of John Ryan. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments