Top 5 Enterprise ETL Tools
If you're looking to adopt a new tools to help perform ETL process, check out this list of five options and see which one fits your needs.
Join the DZone community and get the full member experience.
Join For Free
With the ever-growing amounts of data, enterprises create an increasing demand for data warehousing projects and systems for advanced analytics. ETL is their essential element. It ensures successful data integration within various databases and applications. In this ETL tools comparison, we will look at:
- Apache NiFi
- Apache StreamSets
- Apache Airflow
- AWS Data Pipeline
- AWS Glue
They are among the most popular ETL tools 2019. Let's compare the pros and cons to find out the best solution for your project.
The ETL meaning is often misunderstood, due to the "simple" interpretation of its abbreviation. It stands for three data warehouse concepts: extract, transform, load. Thus, ETL processes include:
- Extracting data from different external sources
- Transforming it as the business model requires.
- Loading data into the new warehouse.
ETL is only a subset of data movement tasks. Ralph's Kimball book, Data Warehouse ETL Toolkit, defines its three fundamental features:
- Data is downloaded in a suitable format for analytics.
- It is enriched with additional information.
- The system records and documents the origin of the data.
So, the data shouldn't just be reloaded from one place to another — it should be improved in the loading process. For example, an ETL developer can add new calculated or technical attributes. It's important to track how the data appeared in the database, as well as how and when it was changed.
ETL Process Steps
A web programmer can imagine ETL architecture as a set of three areas:
- A data source.
- An intermediate area.
- A data receiver.
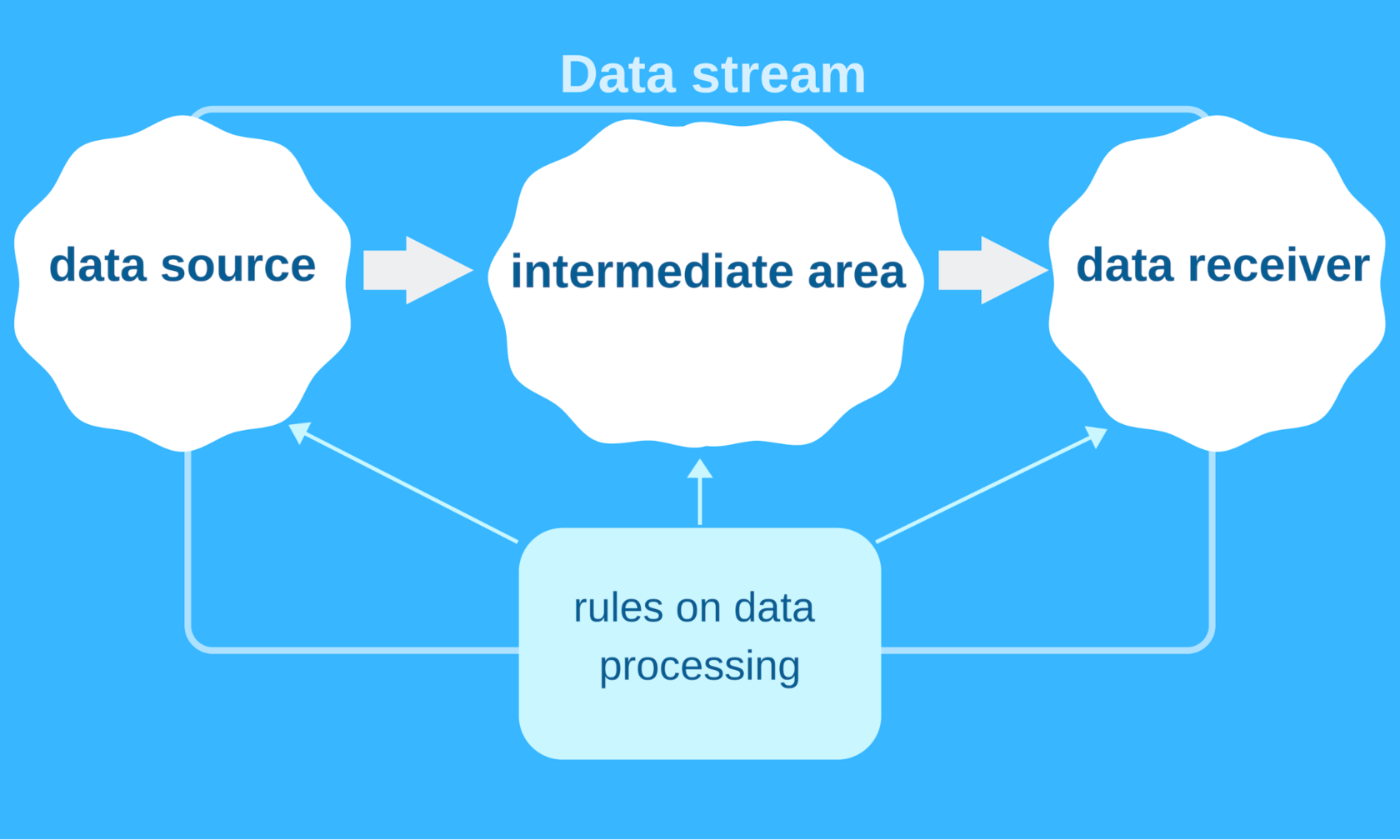
A data stream is the movement of data from the source to the receiver. Each of the stages can be quite complicated. The process of creating ETL software includes different challenges:
- The variety of external sources.
- Unification of data according to business rules.
- The frequency of updates and other specific requirements.
That's why an IT company needs to have a clear picture of structures of the source and destination applications.
An ETL Example
The common ETL task is to transfer data from RDBMS to another database that works better for business intelligence tools. ELT jobs are divided into two types:
- Batch job
- Stream job
The case with taking data from RDBMS is an example of a stream job. The data is transferred separately one by one for further processing. Otherwise, we can talk about a batch job. This means you can take a whole file, process it, and save it to a larger file. Various ETL systems cope with these tasks in different ways.
Nowadays, the batch-only approach has become a relic. The growing number of streaming data sources has caused ETL tools to be used mainly for stream jobs. They make the most recent data available as quickly as possible.
The variety of common and cloud-based data integration tools makes the choice really difficult. So, I prepared a list of five ETL solutions that are reliable (in my experience).
1. Apache Nifi
Pricing: Free
Official website: https://nifi.apache.org/
Useful resources: documentation, tutorials
Pros:
- Perfect implementation of dataflow programming concept.
- The opportunity to handle binary data.
- Data provenance.
Cons:
- Simplistic UI.
- Lack of live monitoring and per-record statistics.
The first in the list of the best ETL tools is an open source project, Apache NiFi. Developed by the Apache Software Foundation, it is based on the concept of Dataflow Programming. This means that this ETL tool allows us to visually assemble programs from boxes and run them almost without coding. So, you don't have to know any programming languages.
One of the most popular open source ETL tools, NiFi is capable of working with a lot different sources. For example, RabbitMQ, JDBC query, Hadoop, MQTT, UDP socket, etc. As for the actions, you can filter, adjust, join, split, enhance, and verify data.
Apache NiFi is written in Java and distributed under the Apache 2.0 license. It runs on a JVM and supports all JVM languages.
This ETL tool helps to create long-running jobs and is suited for processing both streaming data and periodic batches. As for manually managed jobs, they are also possible. However, there is a risk to face difficulties while setting them up.
Thanks to the well-rounded architecture, Apache NiFi is considered as one of the best open source ETL tools. It's a powerful and easy-to-use solution. FlowFile includes meta-information. So, the tool's possibilities aren't limited to CSV. You can work with photos, videos, audio files, or binary data.
The processors include three outputs:
- Failure means there are problems with appropriate processing of FlowFile.
- Original shows that an incoming FlowFile has been processed.
- Success denotes that the processing of FlowFiles was finished.
If you want to drop terminated outputs, you can use special checkboxes. You should pay attention to the Process Groups. They are necessary for combining elements of a complex dataflow in advanced ETL programming.
Another great feature is the possibility of using various queue policies (FIFO, LIFO, and others). Data Provenance is a connected service that records almost everything in your dataflows. It's very convenient because you can see how the data was saved or performed. The only drawback is that the function requires lots of disk space.
Some users complain about the Apache NiFi's interface. Actually, it isn't impressive, but the usability is good enough. The UI has a clear, minimalist design without extra elements. The only exception is the lack of automatic adjustment of text fields for long SQL queries. You should do them manually.
There is also a built-in Node cluster. You can pick up several instances and it will pull out the necessary ETL data. Apache NiFi includes back pressure. It is needed for quickly connecting to MySQL, getting the file, and adding it to the next processor.
To sum up, Apache NiFi is a nice alternative to other mainstream ETL tools. Its main advantage is more than 100 different embedded processors. They provide an opportunity to download files via HTTP, S3, or Google Data Source and upload them to MySQL or other data receivers. You need just to configure the UI, press the RUN button, and, if everything is right, it will work.
2. Apache StreamSets
Pricing: Free
Official site: https://streamsets.com
Useful resources: documentation, tutorials, developer support forum, source code
Pros:
- Each processor has individual per-record statistics with nice visualization for effective debugging.
- Attractive user interface.
- Good tool for streaming or record-based data.
Cons:
- The absence of a reusable JDBC configuration.
- Changing a setting of one processor requires stopping the whole dataflow.
Apache StreamSets is a strong competitor of Apache NiFi. It's difficult to say which on these free ETL tools is better.
All data that you put into StreamSets automatically converts into exchangeable records. The common format is designed for smooth streaming. Unlike Apache Nifi, this ETL tool doesn't show queues between processors. If you want to use different formats, Apache Nifi requires turning from one version of the processor to another. StreamSets avoids these manipulations. Instead of stopping only one processor, you need to stop the whole dataflow to change the settings.
While it may seem that fixing bugs is more difficult in StreamSets, in fact, it's easier due to the real-time debugging tool. Thanks to the user-friendly interface with a live dashboard and all the necessary statistics, you can notice and fix any error. Moreover, there is an opportunity to put record filters on the connections between processors to check suspicious records. There are four variations of the processor:
- Origin processor receives information from data sources.
- Processors that get and transform the received data.
- Destinations put transformed data to the external files.
- Executors process actions completed by other processors.
StreamSets processors can generate actions and events, including bugs. In order to track and fix them, you need executors. Some users prefer Apache NiFi because its design is simpler. All you need are the Processors and Controller Services. However, StreamSets also has well-thought architecture, which isn't difficult to get used to. And the UI also looks better.
I felt the lack of Controller Services, which is quite important for JDBC settings. Adjusting all JDBC settings for each processor is really annoying.
StreamSets checks all processors before you can run the dataflow. This feature seems quite useful. In my experience, it's a controversial thing StreamSets doesn't allow you to leave disconnected processors for fixing bugs in the future. All of them must be connected before the dataflow starts. As for other cons, I felt a lack of possibilities, as I couldn't choose more than 1 processor at once. Moving many processors and reorganizing them one-by-one takes too much time and effort.
All in all, it's a mature, open source ETL tool with convenient visual data flow and a modern web interface. I recommend you to try StreamSets and Apache NiFi to find out which of them is the most suitable for your purposes.
3. Apache Airflow
Pricing: Free
Official site: https://airflow.apache.org
Useful resources: tutorial
Pros:
- Suits for different types of tasks.
- User-friendly interface for clear visualization.
- Scalable solution.
Cons:
- Isn't suitable for streaming jobs.
- Requires additional operators.
This modern platform for designing, creating and tracking workflows is an open source ETL software. It can be used with cloud services, including GCP, Azure, and AWS. There is an opportunity to run Airflow on Kubernetes using Astronomer Enterprise.
You can code in Python, but not have to worry about XML or drag-and-drop GUIs. The workflows are written in Python, however, the steps themselves can be done in anything you want. Airflow was created as a perfectly flexible task scheduler. One of the top ETL tools is suitable for lots of different purposes. It is used to train ML models, send notifications, track systems, and power functions within various APIs.
The main facts about the platform:
- Airflow-as-a-Service is available from Qubole and astronomer.io.
- It was created by Airbnb in 2015 and transitioned to Apache in 2016.
- The basis for Google's Cloud Composer (beta summer 2018).
- Workflows are performed as directed acyclic graphs (DAGs).
Apache Airflow was designed according to four fundamental principles. The developers aimed to create a dynamic, extensible, elegant, and scalable solution. So, it provides dynamic pipeline generation through coding in Python. You can also define your own operators and executors and extend the library according to the needed level of abstraction. The pipelines are clear and accurate because parameterizing is included into the core of the platform. Thanks to the modular design with a message queue, Airflow can be easily scaled.
Apache Airflow is suitable for most of the everyday tasks (running ETL jobs and ML pipelines, delivering data and completing DB backups). However, it's a bad choice for stream jobs.
The platform has a modern UI that is full of visualization elements. You can see all the running pipelines, track progress, and fix bugs. This helps complete complex tasks on DAGs.
As for workflows, they are constant and stable. The structure is just a little bit more dynamic than an ETL database. If you define workflows as code, they will be more collaborative, versionable, testable, and maintainable.
The platform runs on a private Kubernetes cluster. It also includes resource management tools and analytics (StatsD, Prometheus, Grafana).
What about the ETL testing of Airflow workflows? You can use:
- Unit tests
- Integration tests
- End-to-end tests (in some cases)
The first type is suitable for checking DAG loading, Python operator functions, custom operators, and Bash/EMR scripts. The platform doesn't require any original configurations. The only thing that should be changed is the DB connection string. You need to create an empty database, and give the user permission to CREATE/ALTER. So, an airflow command will handle all the rest.
To conclude, Apache Airflow is a free, independent framework written in Python. It's a good example of open source ETL tools. Airflow can be challenging to run alone, so you should use different operators.
4. AWS Data Pipeline
Pricing: Variable
Official site: https://aws.amazon.com/datapipeline/
Useful resources: documentation, community forum
Pros:
- Easy to use ETL technology
- Reasonable price
- Nice flexibility
Cons:
- Doesn't have many built-in functions
The web service ensures processing and moving data between an AWS compute and various data sources. It provides permanent access to the stored data, as well as its transformation. The final results can be transferred to AWS services. They are Amazon DynamoDB, Amazon RDS, Amazon EMR, and Amazon S3. This ETL tool simplifies the process of creating complex data processing workloads. It helps to achieve a repeatable, highly available, and reliable case-load.
AWS Data Pipeline gives the possibility to move and process data that was previously locked up in on-premises data silos. Amazon asserts that its ETL tool has six main advantages:
- Accuracy
- Simplicity
- Adaptability
- Good price
- Scalability
- Transparency
AWS Data Pipeline is a reliable service that automatically retries the active processes in case of any failures. You will also receive notifications via Amazon SNS. They can be set for successful runs, delays, or failures.
The drag-and-drop console allows fast and simple designing of pipelines. The built-in preconditions prevent you from writing any extra logic to use them. The web developer enjoys various popular features. I mean scheduling, dependency tracking, and issues handling. The service's flexible design allows for the smooth processing of numerous files.
This product isn't expensive compared to other ETL tools. AWS Data Pipeline is a serverless orchestration service and you pay only for what you use. Moreover, there is a free trial version for new users. It's a transparent solution. The user receives full information on the pipelines and has complete control over the computational resources.
Finally, I especially recommend this ETL tool for performing pipe jobs. I use it on my current project for transferring data. Although AWS Data Pipeline doesn't have many built-in functions, it provides a convenient UI. It can spawn instances and ensure cascading file management. I like this simple, inexpensive, and useful tool with built-in processors that allows you to do everything via the UI.
5. AWS Glue
Pricing: Variable
Official site: https://aws.amazon.com/glue/
Useful resources: tutorials
Pros:
- Supports various data sources.
- Good integration with AWS services.
Cons:
- A lot of manual work.
- Poor flexibility.
The code-based, serverless ETL alternative to traditional drag-and-drop platforms is effective, but an ambitious solution. AWS Glue allows you to create and run an ETL job in the AWS Management Console. The service takes data and metadata from AWS, puts it in the catalog, and makes it searchable, queryable, and available for ETL. The process includes three steps:
- Classifying data through building a catalog (JSON, CSV, Parquet, and many other formats are available).
- Generating ETL code and editing transformations (written in Scala or Python).
- Scheduling and running ETL jobs.
Amazon points out three main benefits of this ETL tool.
Convenience: Having tight integration with numerous AWS services and engines, this tool is simple for those who already use Amazon products. The drawback is that you can't implement it on-premise or in any other cloud environment.
Profitable: The serverless solution means you don't need to provision or manage infrastructure. So, the cost depends on the measure of "Data Processing Units." You pay only for the jobs that are running.
Powerful: The automatization of creating, maintaining, and running ETL jobs is perfect. On the other hand, the service requires a lot of manual work too.
Apache Spark is used as the base for ETL logic. However, you may notice significant differences from ordinary Spark. The service has a "dynamic frame" with specific Glue methods, while Spark uses a "data frame."
AWS Glue is a modern and strong part of the AWS ecosystem. But you should be mindful of its nuances. The service provides a level of abstraction in which you must identify tables. They represent your CSV files. There is a lot of manual work here, but, in the end, it will generate the code for Spark and launch it. You can download this code in Scala or Python and change it as you want. It's suitable for a wide range of data sources, but the service forces you to choose a specific solution. If you want to try another way, you may not be able to do that.
How to Select the Right ETL Tool
InfoWorld asserts that ETL causes the largest costs in building data warehousing systems. It's the bottleneck that requires special attention. A correct ETL implementation is your chance to optimize costs and speed-up work. When hoosing an ETL tool, consider five criteria:
- The complexity of your system.
- Your data requirements.
- Developer experience.
- Costs of ETL technologies.
- Special business needs.
Published at DZone with permission of Vitaliy Samofal. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments