Topic Tagging Using Large Language Models
Explore various techniques for organizing large amounts of content into topics using Large Language Models.
Join the DZone community and get the full member experience.
Join For FreeTopic Tagging
Topic tagging is an important and widely applicable problem in Natural Language Processing, which involves tagging a piece of content — like a webpage, book, blog post, or video — with its topic. Despite the availability of ML models like topic models and Latent Dirichlet Analysis [1], topic tagging has historically been a labor-intensive task, especially when there are many fine-grained topics. There are numerous applications to topic-tagging, including:
- Content organization, to help users of websites, libraries, and other sources of large amounts of content to navigate through the content
- Recommender systems, where suggestions for products to buy, articles to read, or videos to watch are generated wholly or in part using their topics or topic tags
- Data analysis and social media management — to understand the popularity of topics and subjects to prioritize
Large Language Models (LLMs) have greatly simplified topic tagging by leveraging their multimodal and long-context capabilities to process large documents effectively. However, LLMs are computationally expensive and require the user to understand the trade-offs between the quality of the LLM and the computational or dollar cost of using them.
LLMs for Topic Tagging
There are various ways of casting the topic tagging problem for use with an LLM.
- Zero-shot/few-shot prompting
- Prompting with options
- Dual encoder
We illustrate the above techniques using the example of tagging Wikipedia articles.
1. Zero-Shot/Few-Shot Prompting
Prompting is the simplest method for using an LLM, but the quality of the results depends on the size of the LLM.
Zero-shot prompting [2] involves directly instructing the LLM to perform the task. For instance:
<wikipedia webpage text>
What are the 3 topics the above text is talking about?Zero-shot is completely unconstrained, and the LLM is free to output text in any format. To alleviate this issue, we need to add constraints to the LLM.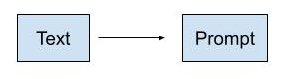
Zero-shot prompting
Few-shot prompting provides the LLM examples to guide its output. In particular, we can give the LLM a few examples of content along with their topics, and ask the LLM for the topics of new content.
<wikipedia page of physics>
Topics: Physics, Science, Modern Physics
<wikipedia page of baseball>
Topics: Baseball, Sport
<wikipedia page you want to tag with topics>
Topics: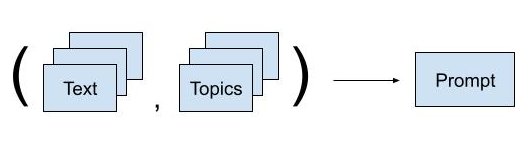
Few-shot prompting
Advantages
- Simplicity: The technique is straightforward and easy to understand.
- Ease of comparison: It is simple to compare the results of multiple LLMs.
Disadvantages
- Less control: There is limited control over the LLM's output, which can lead to issues like duplicate topics (e.g., "Science" and "Sciences").
- Possible high cost: Few-shot prompting can be expensive, especially with large content like entire Wikipedia pages. More examples increase the LLM's input length, thus raising costs.
2. Prompting With Options
This technique is beneficial when you have a small and predefined set of topics, or a method of narrowing down to a manageable size, and want to use the LLM to select from this small set of options.
Since this is still prompting, both zero-shot and few-shot prompting could work. In practice, since the task of selecting from a small set of topics is much simpler than coming up with the topics, zero-shot prompting can be preferred due to its simplicity and lower computational cost.
An example prompt is:
<wikipedia page of physics>
Possible topics: Physics, Biology, Science, Computing, Baseball …
Which of the above possible topics is relevant to the above text? Select up to 3 topics.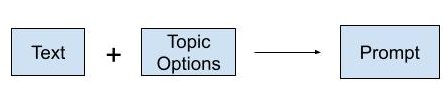
Prompting with options
Advantages of Prompting With Options
- Higher control: The LLM selects from provided options, ensuring more consistent outputs.
- Lower computational cost: Simpler task allows the use of a smaller LLM, reducing costs.
- Alignment with existing structures: Useful when adhering to pre-existing content organization, such as library systems or structured webpages.
Disadvantages of Prompting With Options
- Need to narrow down topics: Requires a mechanism to accurately reduce the topic options to a small set.
- Validation requirement: Additional validation is needed to ensure the LLM does not output topics outside the provided set, particularly if using smaller models.
3. Dual Encoder
A dual encoder leverages encoder-decoder LLMs to convert text into embeddings, facilitating topic tagging through similarity measurements. This is in contrast to prompting, which works with both encoder-decoder and decoder-only LLMs.
Process
- Convert topics to embeddings: Generate embeddings for each topic, possibly including detailed descriptions. This step can be done offline.
- Convert content to embeddings: Use an LLM to convert the content into embeddings.
- Similarity measurement: Use cosine similarity to find the closest matching topics.
Advantages of Dual Encoder
- Cost-effective: When already using embeddings, this method avoids reprocessing documents through the LLM.
- Pipeline integration: This can be combined with prompting techniques for a more robust tagging system.
Disadvantage of Dual Encoder
- Model constraint: Requires an encoder-decoder LLM, which can be a limiting factor since many newer LLMs are decoder-only.
Hybrid Approach
A hybrid approach can leverage the strengths of both prompting with options and the dual encoder method:
- Narrow down topics using the dual encoder: Convert the content and topics to embeddings and narrow the topics based on similarity.
- Final topic selection using prompting with options: Use a smaller LLM to refine the topic selection from the narrowed set.
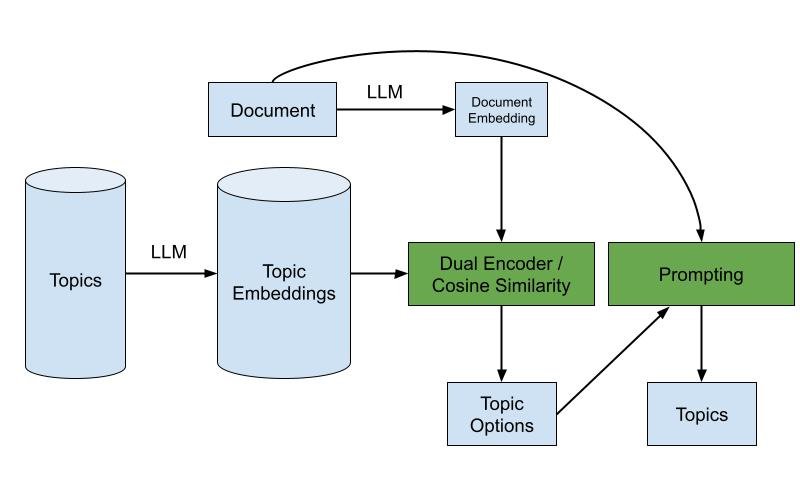
Hybrid approach
Conclusion
Topic tagging with LLMs offers significant advantages over traditional methods, providing greater efficiency and accuracy. By understanding and leveraging different techniques — zero-shot/few-shot prompting, prompting with options, and dual encoder — one can tailor the approach to specific needs and constraints. Each method has unique strengths and trade-offs, and combining them appropriately can yield the most effective results for organizing and analyzing large volumes of content using topics.
References
[1] LDA Paper
Opinions expressed by DZone contributors are their own.
Comments