Topic Modeling: Techniques and AI Models
Topic modeling is a method in natural language processing used to train machine learning models. Learn the three most common techniques of topic modeling.
Join the DZone community and get the full member experience.
Join For FreeTopic modeling is a method in natural language processing (NLP) used to train machine learning models. It refers to the process of logically selecting words that belong to a certain topic from within a document.
From a business standpoint, topic modeling provides great time- and effort-saving benefits. For example, a company that wants to identify areas of improvement can run a survey asking users to rate their services and explain each rating. Topic modeling can fast-track this analysis by categorizing information into a topic like “most common reasons for low ratings.”
Techniques for Topic Modeling
Topic modeling is about logically correlating several words. Say a telecom operator wants to identify whether the poor network is a reason for low customer satisfaction. Here, “bad network” is the topic. The document is analyzed for words like “bad”, “slow speed”, “call not connecting”, etc., which are more likely to describe network issues compared to common words like “the” or “and”.
The three most common techniques of topic modeling are:
1. Latent Semantic Analysis (LSA)
Latent semantic analysis (LSA) aims to leverage the context around the words in order to capture hidden concepts or topics.
In this method, machines use Term Frequency-Inverse Document Frequency (TF-IDF) for analyzing documents. TF-IDF is a numerical statistic that reflects how important a word is to a document within a corpus.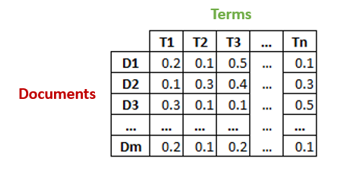
Say there is a collection of ‘m’ text documents and each document has a total of ‘n’ unique words. The TF-IDF matrix – m*n – contains the TF-IDF scores for each word in the document. This matrix is then reduced to ‘k’ dimensions, k being the desired number of topics. The reduction is done using Singular Value Decomposition (SVD). The SVD matrix decomposes into three other matrices, as shown in Figure 2.
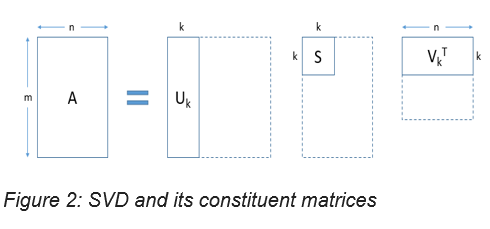
This decomposition provides a vector representation of each word term in each document in the entire collection through the equation A = USVT where:
- A is the SVD matrix
- U is the vector representation of the documents with vector length k
- V is the vector representation of terms in the given document with length k
- S represents the diagonal matrix of the singular topic frequency scores
- T is a hyperparameter reflecting the number of topics
The SVD matrix can be used to find similar topics and documents using the cosine similarity method.
The main disadvantages of LSA are the inefficient representation and non-interpretable embeddings. It also requires a large corpus to yield accurate results.
2. Probabilistic Latent Semantic Analysis (pLSA)
Probabilistic Latent Semantic Analysis (pLSA) was introduced to solve the representation challenge in LSA by replacing SVD with a probabilistic model. pLSA represents each entry in the TF-IDF matrix using probability.
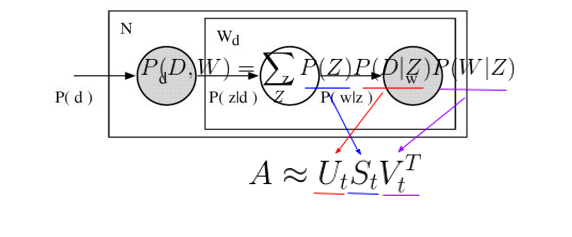
The equation P(D,W) = P(D) ∑ P(Z|D)P(W|Z) provides a joint probability suggesting how likely it is to find a certain word within a document based on the distribution of topics within it. Another parameterization – P(D,W) = ∑P(Z)P(D|Z)P(W|Z) – denotes the probability that a document contains a given topic and that a word within the document belongs to the given topic. The parameterization closely resembles LSA.
3. Latent Dirichlet Allocation (LDA)
Latent Dirichlet Allocation (LDA) is a Bayesian version of pLSA. The core concept is replaced by Dirichlet allocations where the distribution is sampled over a probability simplex. A probability simplex represents a set of numbers that add up to 1. When the set comprises three numbers, it is called a three-dimensional Dirichlet distribution.
The total desired number of topics is set as ‘k’ in the dimensional Dirichlet distribution. The LDA model reads every document, assigns each word to one of the ‘k’ topics, and provides a representation of the words and documents for a given topic. As the assignment of topics is random, the representation is not optimal. Through different equations, the Latent Dirichlet Allocation model can provide the following results:
- Percentage of words within a given document that are assigned to a particular topic
- The number of times a particular word in all the documents has been assigned to a particular topic
- Movement of a word from topic A to topic B, i.e. (topic A | d) * P (w | topic A) < P (topic B | d) * P (w | topic B), where ‘w’ means word and ‘d’ means document
These results denote the optimal number of topics and the assignment of words to each topic. The model can learn from a given set of documents and its Dirichlet distribution and, later, predict topics for a new set of documents.
How to Use Latent Dirichlet Allocation
The LDA model is mainly used to classify document text under a particular topic. For each document, it builds a topic and includes relevant words, modeled as Dirichlet distributions. LDA is proven to deliver accurate results for topic modelling use cases. However, it first requires certain document modifications and pre-processing as explained below:
Step 1: Choose the Right Library
The following libraries are used depending on the task:
- Pandas for data manipulation and analysis
- Genism for document indexing and similarity retrieval in large documents
- pyLDAvis for interactive topic modelling visualization
- Parsivar and Hazm to act as an NLP library for Persian depending on the use case
Step 2: Preprocess the Data
Before being consumed by the model, the document must be pre-treated through each of the following steps:
- Normalization – Transform text to normal/canonical form
- Stemming – Reduce a word to its word stem/root without suffixes and prefixes
- Stopwordremoval – Remove words that do not add any logical meaning
- Tokenization – Break text into ‘tokens’, i.e. words and phrases
This helps the model identify words and assign them to the correct topic.
Step 3: Build the Dictionary
The pre-processing output text is used to build the dictionary and corpus that, in turn, become inputs for the LDA model for topic modeling.
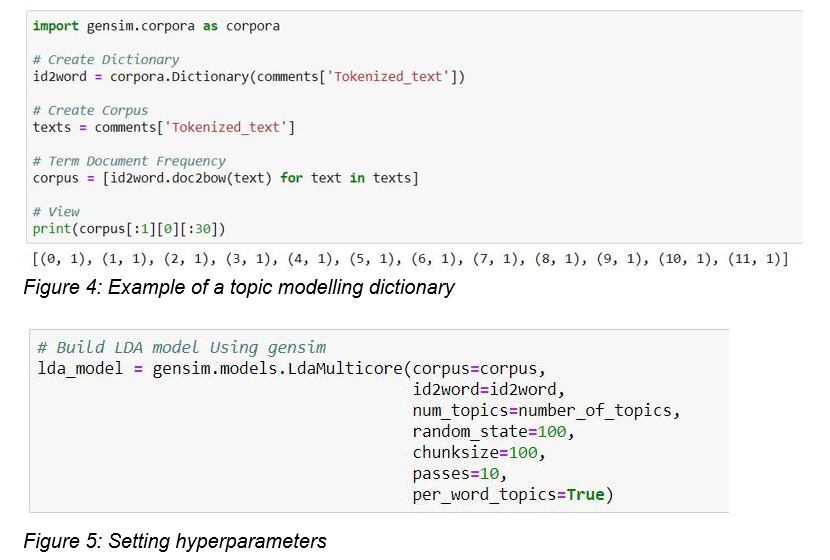
The number of topics (k) is set at 10. The rest of the parameters are set as ‘default’ for the first run.
Step 4: Test for Accuracy
A coherence matrix is used to test the model for accuracy. Topic coherence is a measure that compares different topic models based on their human-interpretability. The coherence score ‘C_V’ provides a numerical value to the interpretability of the topics. In Figure 6, the coherence score is 0.52.
Companies should build many LDA models with different ‘k’ values. The correct model will have the highest coherence score. While choosing a high ‘k’ value can provide granular sub-topics, repetition of keywords indicates that the ‘k’ value is too large. Thus, the correct ‘k’ value will minimize rapid increase in topic coherence.

Step 5: Visualize the Topics
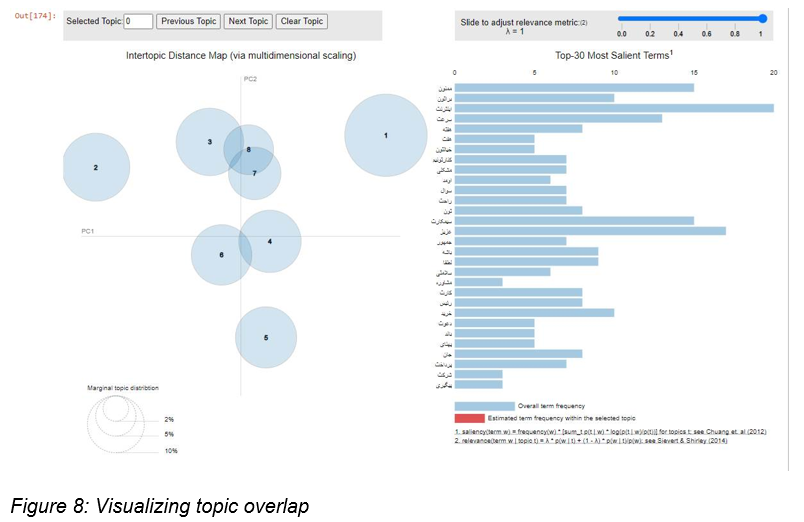
The optimal number of topics can be better visualized through the interactive pyLDAvis tool. pyLDAvis displays the number of topics, overlapping topics, and all the words contained within a given topic (see Figure 8) for users to take necessary action.
Step 6: Optimize the Topics
In this step, hyperparameters are tuned to optimize the number of topics. Different combinations of alpha (document-topic density), k and beta (topic-word density) are run and their coherence scores are calculated. The combination with the highest coherence score is used to build the LDA model.
For the LDA model explained in this paper, the optimal parameters are:
- Number of topics = 6
- Alpha = asymmetric
- Beta/eta = 0.31
After configuring the model with these parameters, one can test whether it can predict topics for any unseen text document. The test results are visualized as follows:

Since this is a Dirichlet analysis, all the probabilities will add up to 1. Figure 9 shows that topic 1 has the highest value – 0.66, i.e. the document has the highest probability of belonging to topic 1.
Reading the LDA Model Results
The LDA model used in this paper has a coherence score of 0.52 (see Figure 6). This means that the model has performed reasonably well in topic modeling. If the coherence score is 0.85 and above, there is a high chance of overfitting in the model.
The LDA model does not identify the topic as a distinct word. Instead, it provides a probability of the most likely topic. Thus, users are required to determine a logical topic from the set of words provided by the model and map the topic numbers with the topic names identified by the user. This entire process is called topic modeling.
Conclusion
LSA, probabilistic LSA, and LDA are three common ways of topic modeling. Due to its ability to build valid dictionaries and use previous learnings to predict topics in new sets of documents, LDA is the recommended model for advanced topic modeling.
Opinions expressed by DZone contributors are their own.
Comments