Train Your Own Private ChatGPT Model for the Cost of a Starbucks Coffee
With the cost of a cup of Starbucks and two hours of your time, you can own your own trained open-source large-scale model.
Join the DZone community and get the full member experience.
Join For FreeThe birth of ChatGPT has undoubtedly filled us with anticipation for the future of AI. Its sophisticated expression and powerful language understanding ability have amazed the world. However, because ChatGPT is provided as a Software as a Service (SaaS), issues of personal privacy leaks and corporate data security are concerns for every user and company. More and more open-source large-scale models are emerging, making it possible for individuals and companies to have their own models. However, getting started with, optimizing, and using large-scale open-source models have high barriers to entry, making it difficult for everyone to use them easily. To address this, we use Apache DolphinScheduler, which provides one-click support for training, tuning, and deploying large-scale open-source models. This enables everyone to train their own large-scale models using their data at a very low cost and with technical expertise.
Who Is It For? Anyone in Front of A Screen
Our goal is not only for professional AI engineers but for anyone interested in GPT to enjoy the joy of having a model that “understands” them better. We believe that everyone has the right and ability to shape their own AI assistant. The intuitive workflow of Apache DolphinScheduler makes this possible. As a bonus, Apache DolphinScheduler is a big data and AI scheduling tool with over 10,000 stars on GitHub. It is a top-level project under the Apache Software Foundation, meaning you can use it for free and modify the code without worrying about any commercial issues.
Whether you are an industry expert looking to train a model with your own data, or an AI enthusiast wanting to understand and explore the training of deep learning models, our workflow will provide convenient services for you. It solves complex pre-processing, model training, and optimization steps and only requires 1–2 hours of simple operations, plus 20 hours of running time to build a more “understanding” ChatGPT large-scale model.
So, let’s start this magical journey! Let’s bring the future of AI to everyone.
Only Three Steps To Create a ChatGPT That “Understands” You Better
- Rent a GPU card at a low cost equivalent to a 3090 level
- Start DolphinScheduler
- Click on the training workflow and deployment workflow on the DolphinScheduler page and directly experience your ChatGPT
Preparing a Host With a 3090 Graphics Card
First, you need a 3090 graphics card. If you have a desktop computer, you can use it directly. If not, there are many hosts for rent with GPU online. Here we use AutoDL as an example to apply. Open this, register, and log in. After that, you can choose the corresponding server in the computing power market according to steps 1, 2, and 3 shown on the screen.
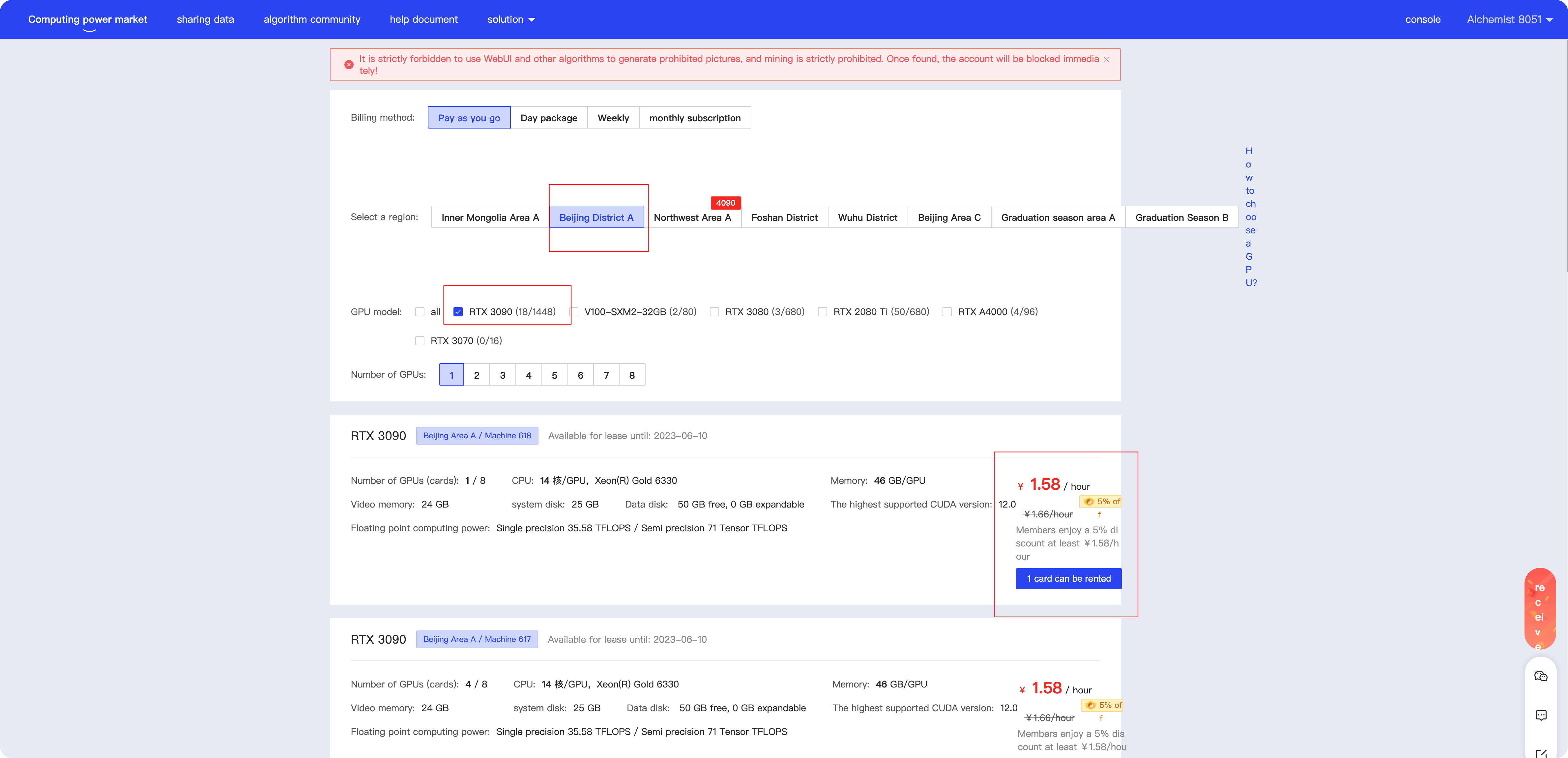
Here, it is recommended to choose the RTX 3090 graphics card, which offers a high cost-performance ratio. After testing, it has been found that one to two people can use the RTX 3090 for online tasks. If you want faster training and response speeds, you can opt for a more powerful graphics card. Training once takes approximately 20 hours, while testing requires around 2–3 hours. With a budget of 40 yuan, you can easily get it done.
Mirror
Click on the community mirror, and then enter WhaleOps/dolphinscheduler-llm/dolphinscheduler-llm-0521 the red box below. You can select the image as shown below. Currently, only the V1 version is available. In the future, as new versions are released, you can choose the latest one.
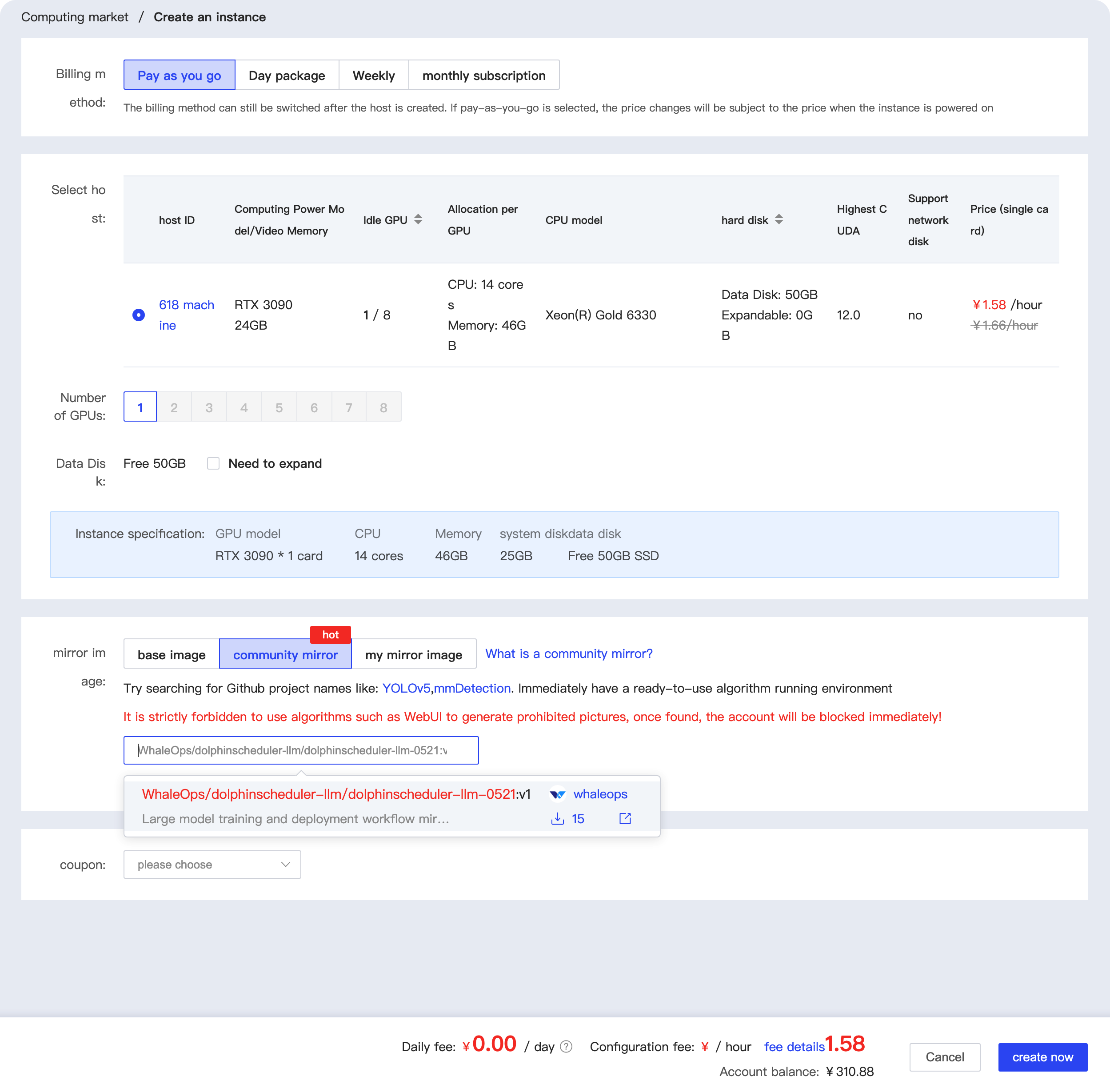
If you need to train the model multiple times, it is recommended to expand the hard disk capacity to around 100GB.
After creating it, wait for the progress bar shown in the following image to complete.
Start DolphinScheduler
In order to deploy and debug your own open-source large-scale model on the interface, you need to start the DolphinScheduler software, and we need to do the following configuration work:
To Access the Server
There are two methods available. You can choose the one that suits your preference:
- Login via JupyterLab (for non-coders):
Click on the JupyterLab button shown below.
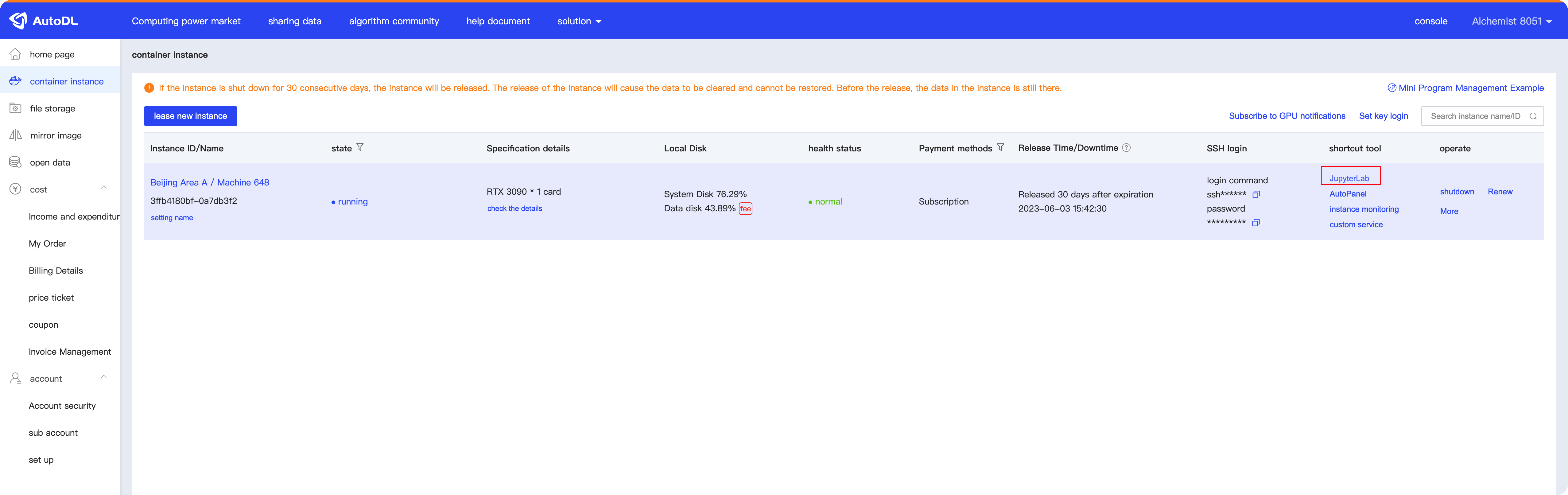
The page will redirect to JupyterLab; from there, you can click “Terminal” to enter.
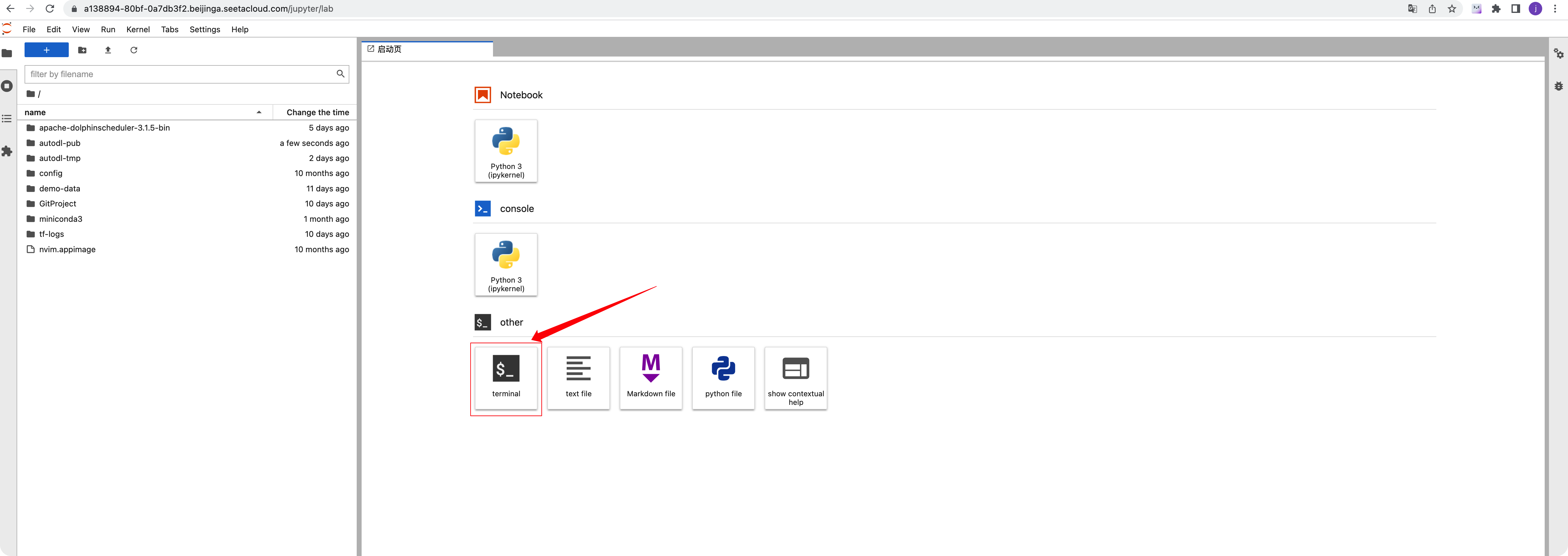
2. Login via Terminal (for coders):
We can obtain the SSH connection command from the button shown in the following image.
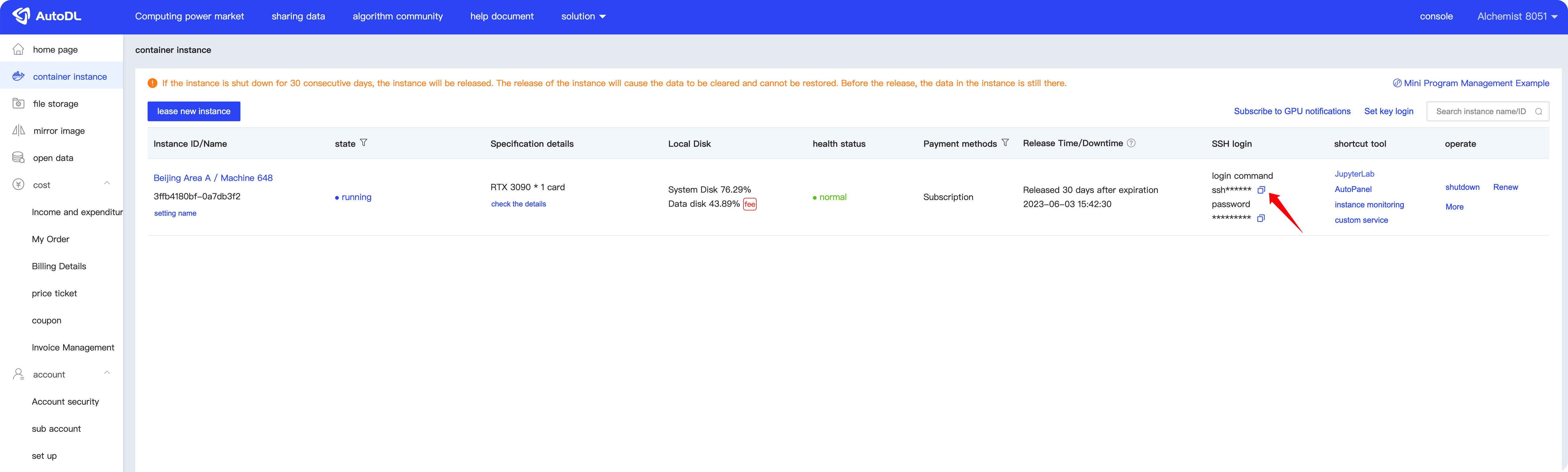
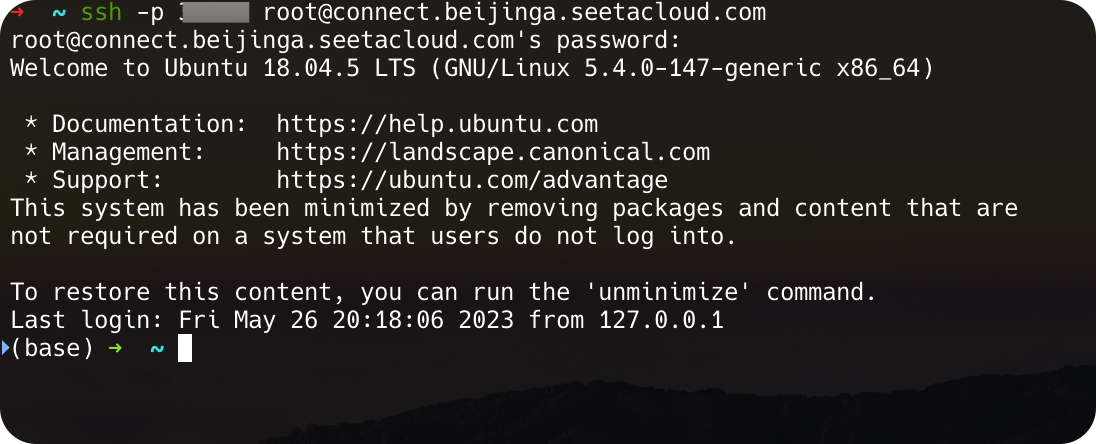
Then, establish the connection through the terminal.
Import the Metadata of DolphinScheduler
In DolphinScheduler, all metadata is stored in the database, including workflow definitions, environment configurations, tenant information, etc. To make it convenient for users to see these workflows when DolphinScheduler is launched, we can directly import pre-defined workflow metadata by copying it from the screen.
Modify the script for importing data into MySQL:
Using the terminal, navigate to the following directory:
cd apache-dolphinscheduler-3.1.5-bin
Execute the command: vim import_ds_metadata.sh to open the import_ds_metadata.sh file.
The content of the file is as follows:
Set variables
Hostname
HOST="xxx.xxx.xxx.x"
Username USERNAME="root"Password PASSWORD="xxxx"Port PORT=3306Database to import into DATABASE="ds315_llm_test"SQL filename SQL_FILE="ds315_llm.sql"mysql -h $HOST -P $PORT -u $USERNAME -p$PASSWORD -e "CREATE DATABASE $DATABASE;"mysql -h $HOST -P $PORT -u $USERNAME -p$PASSWORD $DATABASE < $SQL_FILE
Replacexxx.xxx.xxx.x and xxxx with the relevant configuration values of a MySQL database on your public network (you can apply for one on Alibaba Cloud, Tencent Cloud or install one yourself). Then execute:
bash import_ds_metadata.sh
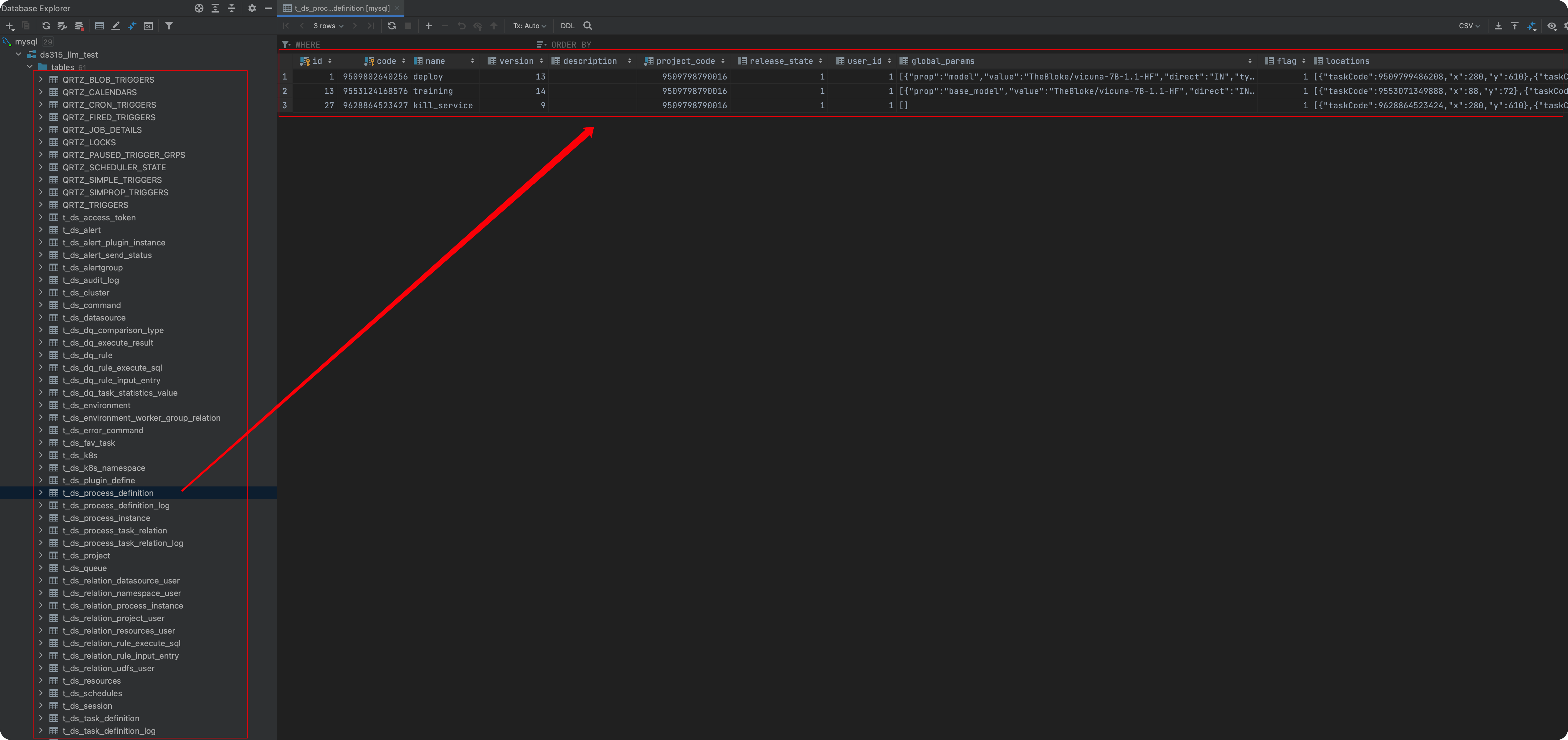
After execution, if interested, you can check the corresponding metadata in the database (connect to MySQL and view, skipping this step if you are not familiar with the code).
Start DolphinScheduler
In the server command line, open the following file and modify the configuration to connect DolphinScheduler with the previously imported database:
/root/apache-dolphinscheduler-3.1.5-bin/bin/env/dolphinscheduler_env.sh
Modify the relevant configuration in the database section, and leave other sections unchanged. Change the values of HOST and PASSWORD to the configuration values of the imported database, i.e., xxx.xxx.xxx.x and xxxx:
export DATABASE=mysql
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://HOST:3306/ds315_llm_test?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME="root"
export SPRING_DATASOURCE_PASSWORD="xxxxxx"
......
After configuring, execute (also in this directory /root/apache-dolphinscheduler-3.1.5-bin):
bash ./bin/dolphinscheduler-daemon.sh start standalone-server
Once executed, we can check the logs by using tail -200f standalone-server/logs/dolphinscheduler-standalone.log. At this point, DolphinScheduler is officially launched!
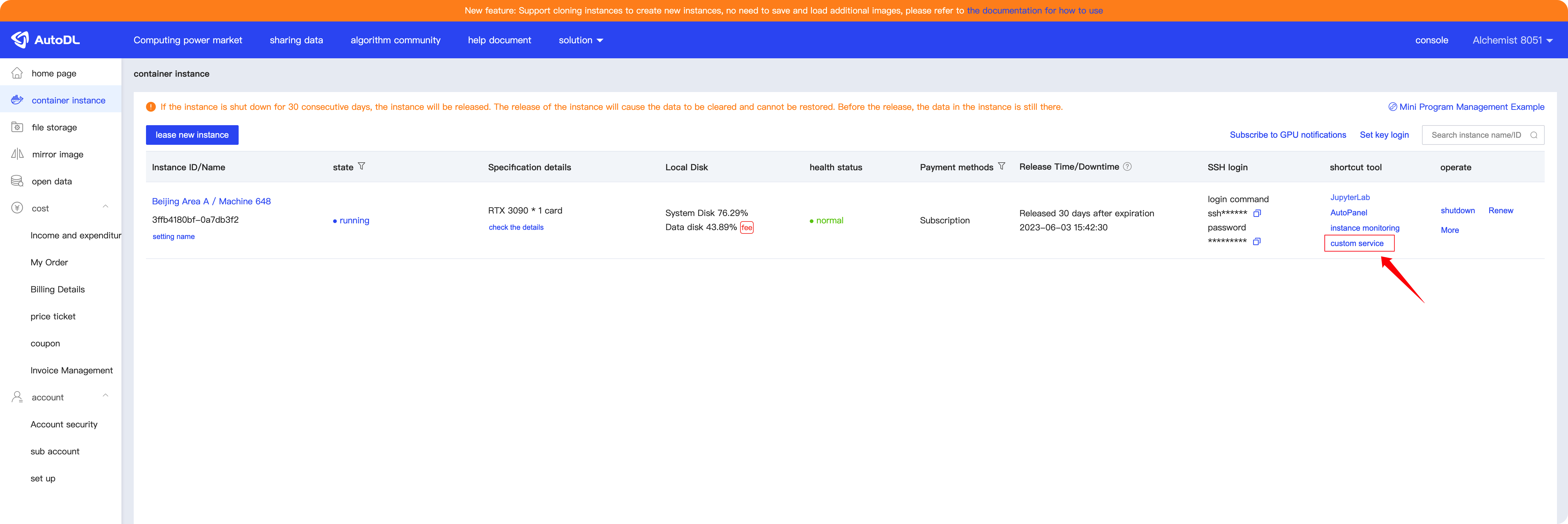
After starting the service, we can click on “Custom Services” in the AutoDL console (highlighted in red) to be redirected to a URL:
Upon opening the URL, if it shows a 404 error, don’t worry. Just append the suffix /dolphinscheduler/ui to the URL:

The AutoDL module opens port 6006. After configuring DolphinScheduler’s port to 6006, you can access it through the provided entry point. However, due to the URL redirection, you may encounter a 404 error. In such cases, you need to complete the URL manually.
Login credentials:
Username: admin
Password: dolphinscheduler123
After logging in, click on “Project Management” to see the predefined project named “vicuna”. Click on “vicuna” to enter the project.
Open Source Large Model Training and Deployment
Workflow Definition
Upon entering the Vicuna project, you will see three workflows: Training, Deploy, and Kill_Service. Let’s explore their uses and how to configure large models and train your data.
You can click the run button below to execute corresponding workflows.
Training
By clicking on the training workflow, you will see two definitions. One is for fine-tuning the model through Lora (mainly using alpaca-lora), and the other is to merge the trained model with the base model to get the final model.
The workflow has the following parameters (pops up after clicking run):
- base_model: The base model, which can be chosen and downloaded according to your needs. The large open-source models are only for learning and experiential purposes. The current default is TheBloke/vicuna-7B-1.1-HF.
- data_path: The path of your personalized training data and domain-specific data defaults to /root/demo-data/llama_data.json.
- lora_path: The path to save the trained Lora weights, /root/autodl-tmp/vicuna-7b-lora-weight.
- output_path: The save path of the final model after merging the base model and Lora weights. Note it down as it will be needed for deployment.
- num_epochs: Training parameter, the number of training epochs. It can be set to 1 for testing, usually set to 3~10.
- cutoff_len: Maximum text length, defaults to 1024.
- micro_batch_size: Batch size.
Deploy
The workflow for deploying large models (mainly using FastChat). It will first invoke kill_service to kill the deployed model, then sequentially start the controller, add the model, and then open the Gradio web service.
The start parameters are as follows:
- model: The model path can be a Huggingface model ID or the model path trained by us, i.e., the output_path of the training workflow above. The default is TheBloke/vicuna-7B-1.1-HF. If the default is used, it will directly deploy the vicuna-7b model.
Kill_service
This workflow is used to kill the deployed model and release GPU memory. This workflow has no parameters, and you can run it directly. If you need to stop the deployed service (such as when you need to retrain the model or when there is insufficient GPU memory), you can directly execute the kill_service workflow to kill the deployed service.
After going through a few examples, your deployment will be complete. Now let’s take a look at the practical operation:
Large Model Operation Example
Training a Large Model
Start the workflow directly by executing the training workflow and select the default parameters.
Right-click on the corresponding task to view the logs.
You can also view the task status and logs in the task instance panel at the bottom left of the sidebar. During the training process, you can monitor the progress by checking the logs, including the current training steps, loss metrics, remaining time, etc. There is a progress bar indicating the current step, where step = (data size * epoch) / batch size.

After training is complete, the logs will look like the following:

Updating Your Personalized Training Data
Our default data is in /root/demo-data/llama_data.json. The current data source is Huatuo, a medical model fine-tuned using Chinese medical data. Yes, our example is training a family doctor:

If you have data in a specific field, you can point to your own data. The data format is as follows: one JSON per line, and the field meaning is:
- instruction ****: Instruction to give to the model.
- input: Input.
- output: Expected model output.
For example:
{"instruction": "calculation", "input": "1+1 equals?", "output": "2"}
Please note that you can merge the instruction and input fields into a single instruction field. The input field can also be left empty.
When training, modify the data_path parameter to execute your own data.
Note:
During the first training execution, the base model will be fetched from the specified location, such as TheBloke/vicuna-7B-1.1-HF. There will be a downloading process, so please wait for the download to complete. The choice of this model is determined by the user, and you can also choose to download other open-source large models (please follow the relevant licenses when using them).
Due to network issues, the base model download may fail halfway through the first training execution. In such cases, you can click on the failed task and choose to rerun it to continue the training. The operation is shown below:

To stop the training, you can click the stop button, which will release the GPU memory used for training.
Deployment Workflow
On the workflow definition page, click on the deploy workflow to run it and deploy the model.
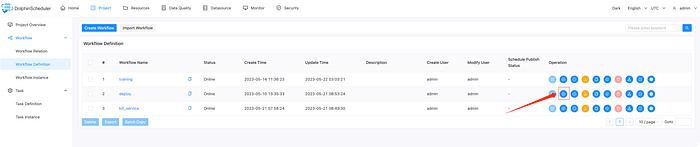
If you haven’t trained your own model, you can execute the deploy workflow with the default parameters TheBloke/vicuna-7B-1.1-HF to deploy the vicuna-7b model, as shown in the image below:
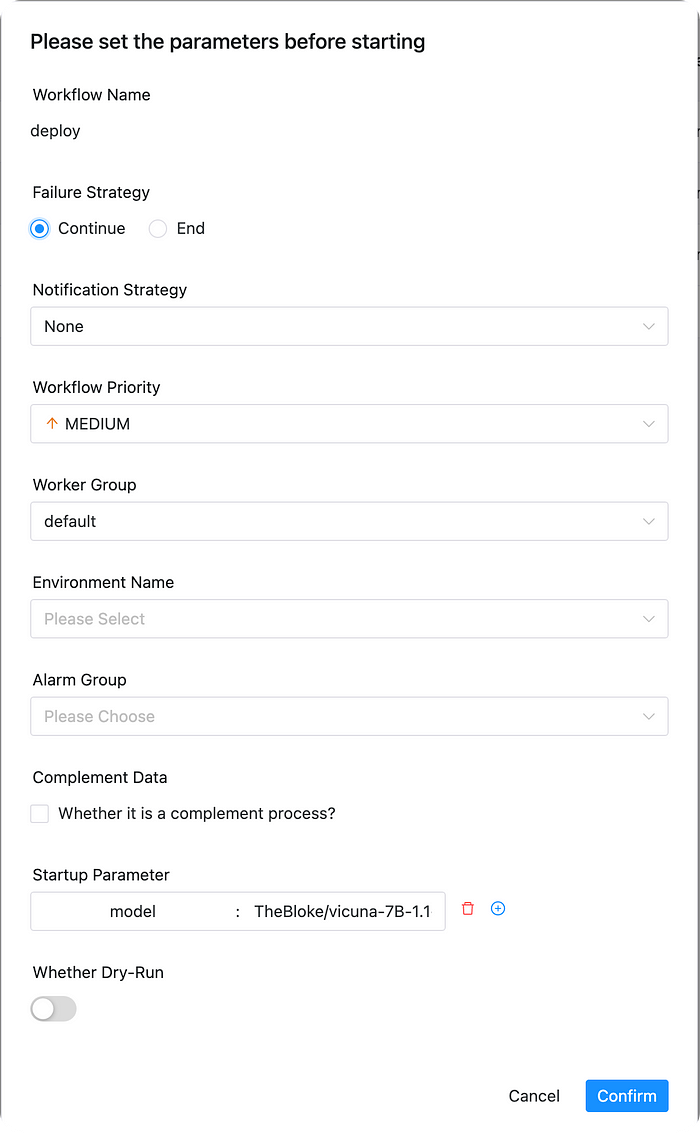
If you have trained a model in the previous step, you can now deploy your model. After deployment, you can experience your own large model. The startup parameters are as follows, where you need to fill in the output_path of the model from the previous step:

Next, let’s enter the deployed workflow instance. Click on the workflow instance, and then click on the workflow instance with the “deploy” prefix.

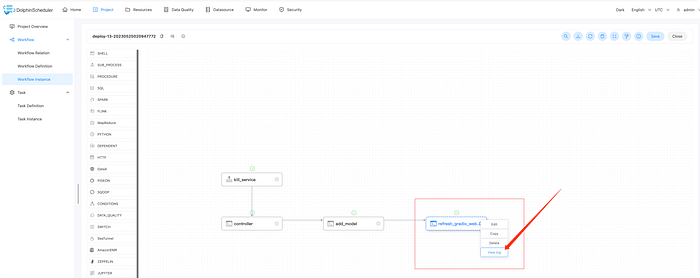
Right-click and select “refresh_gradio_web_service” to view the task logs and find the location of our large model link. The operation is shown below:
In the logs, you will find a link that can be accessed publicly, such as:
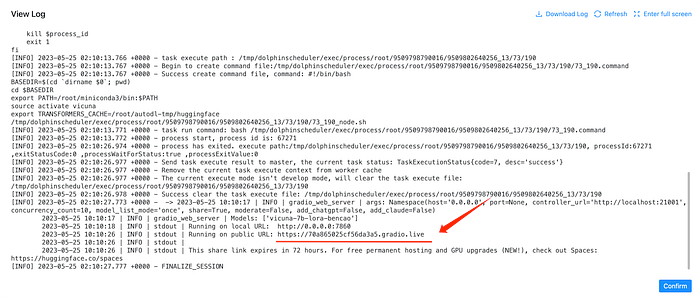
Here are two links. The link 0.0.0.0:7860 cannot be accessed because AutoDL only opens port 6006, which is already used for dolphinscheduler. You can directly access the link below it, such as https://81c9f6ce11eb3c37a4.gradio.live.
Please note that this link may change each time you deploy, so you need to find it again from the logs.
Once you enter the link, you will see the conversation page of your own ChatGPT!
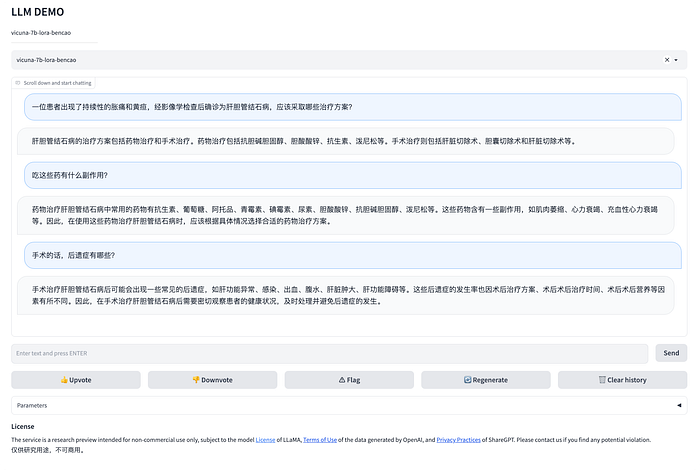
Yes! Now you have your own ChatGPT, and its data only serves you! And you only spent less than the cost of a cup of coffee~~
Go ahead and experience your own private ChatGPT!
Summary
In this data-driven and technology-oriented world, having a dedicated ChatGPT model has immeasurable value. With the advancement of artificial intelligence and deep learning, we are in an era where personalized AI assistants can be shaped. Training and deploying your own ChatGPT model can help us better understand AI and how it is transforming our world.
In summary, training and deploying a ChatGPT model on your own can help you protect data security and privacy, meet specific business requirements, save on technology costs, and automate the training process using workflow tools like DolphinScheduler. It also allows you to comply with local laws and regulations. Therefore, training and deploying a ChatGPT model on your own is a worthwhile option to consider.
Important Notes:
- Data Security and Privacy:
When using ChatGPT through public API services, you may have concerns about data security and privacy. This is a valid concern as your data may be transmitted over the network. By training and deploying the model on your own, you can ensure that your data is stored and processed only on your own device or rented server, ensuring data security and privacy. - Domain-Specific Knowledge:
For organizations or individuals with specific business requirements, training your own ChatGPT model ensures that the model has the latest and most relevant knowledge related to your business. Regardless of your business domain, a model specifically trained for your business needs will be more valuable than a generic model. - Investment Cost:
Using OpenAI’s ChatGPT model may incur certain costs. Similarly, if you want to train and deploy the model on your own, you also need to invest resources and incur technology costs. For example, you can experience debugging large models for as low as 40 yuan, but if you plan to run it long-term, it is recommended to purchase an Nvidia RTX 3090 graphics card or rent cloud servers. Therefore, you need to weigh the pros and cons and choose the solution that best suits your specific circumstances. - DolphinScheduler:
By using Apache DolphinScheduler’s workflow, you can automate the entire training process, greatly reducing the technical barrier. Even if you don’t have extensive knowledge of algorithms, you can successfully train your own model with the help of such tools. In addition to supporting large model training, DolphinScheduler also supports big data scheduling and machine learning scheduling, helping you and your non-technical staff to easily handle big data processing, data preparation, model training, and model deployment. Moreover, it is open-source and free to use. - Legal and Regulatory Constraints on Open Source Large Models:
DolphinScheduler is just a visual AI workflow tool and does not provide any open-source large models. When using and downloading open source large models, you must be aware of the different usage constraints associated with each model and comply with the respective open-source licenses. The examples given in this article are only for personal learning and experience purposes. When using large models, it is important to ensure compliance with open-source model licensing. Additionally, different countries have different strict regulations regarding data storage and processing. When using large models, you must customize and adjust the model to comply with the specific legal regulations and policies of your location. This may include specific filtering of model outputs to comply with local privacy and sensitive information handling regulations.
Published at DZone with permission of Jieguang Zhou. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments