Training ChatGPT on Your Own Data: A Guide for Software Developers
Interactive reading with MEMWALKER enhances AI models for richer, context-aware dialogues, pushing the boundaries of modern AI capabilities.
Join the DZone community and get the full member experience.
Join For FreeThe launch of ChatGPT by OpenAI has been transformative for conversational AI. While impressive out-of-the-box, ChatGPT's capabilities are inherently limited by its fixed training data from 2021. For software developers and tech companies, training ChatGPT on custom datasets is key to creating tailored AI assistants that evolve with your business.
In this comprehensive guide, we'll explore best practices for software teams to train customized ChatGPT models using techniques like fine-tuning and MEMWALKER interactive reading.
Overcoming the Limits of ChatGPT's Default Training

As a brief background, ChatGPT was pre-trained by OpenAI on a massive general knowledge dataset, including Wikipedia, books, websites, and more. However, since this training data was frozen in 2021, ChatGPT has some natural weaknesses:
- No awareness of recent events or emerging topics after 2021.
- Narrow expertise outside of common domains like history and literature.
- No personal memory capabilities based on conversations.
- Difficulty maintaining context in long dialogues.
These limitations arise directly from ChatGPT's fixed dataset that lacks up-to-date, specialized knowledge. By training ChatGPT on your own curated data, you can create a version tailored to your industry, subject matter, and business needs.
Key Approaches to Training ChatGPT Models

There are a few core techniques software teams can use to customize ChatGPT:
Fine-Tuning on Curated Datasets
One straightforward approach is gathering relevant texts like documents, emails, manuals, etc., to fine-tune a ChatGPT model. The process includes:
- Compiling a custom dataset: Gather texts covering the topics and knowledge you want ChatGPT to learn.
- Cleaning and preprocessing: Get the data into a standard format. Anonymize any sensitive info.
- Fine-tuning the model: Use an API like Anthropic's to upload your dataset and further train ChatGPT through backpropagation.
Fine-tuning directly instills your niche knowledge into ChatGPT.
Interactive Reading With MEMWALKER
For long-form text, advanced techniques like MEMWALKER enable more efficient context handling during training. MEMWALKER has two phases:
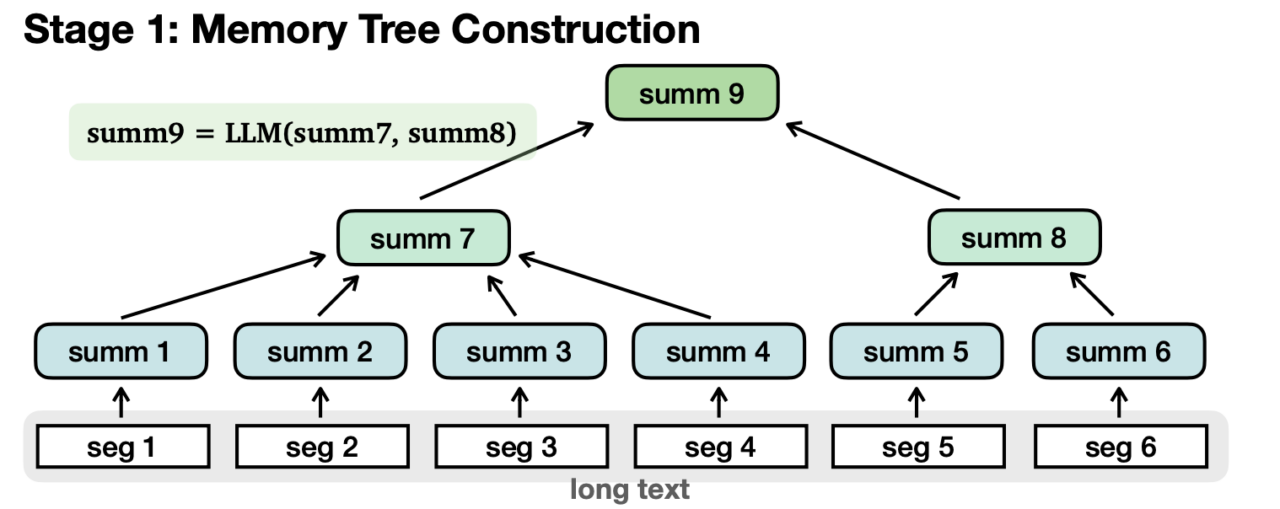
- Building a memory tree: Long texts get split into segments. Each segment is summarized into nodes forming a tree structure.
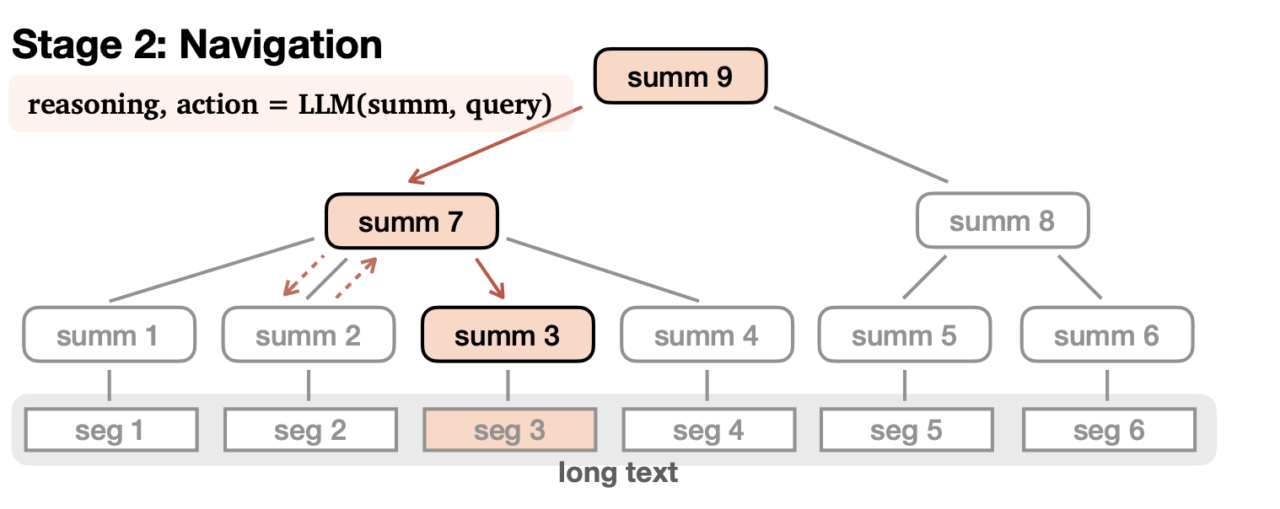
- Navigating the tree: When answering a question, the AI traverses the tree to gather relevant details from nodes.
This approach allows for maintaining context across lengthy examples.
Retrieval Augmentation
You can also use retrieval augmentation by indexing your dataset and combining search with ChatGPT. This allows tapping into large volumes of niche data at inference time.
- Build vector index: Index your custom text collection for semantic search.
- Integrate retrieval: When querying ChatGPT, first surface relevant texts from the index.
- Generate responses: Have ChatGPT consume those texts to inform its answers.
Together, these techniques empower significant customization of ChatGPT's knowledge. Next, we'll walk through the steps to train your own model.
Putting It All Together: How To Train Your ChatGPT
Let's go through a practical guide to training your own ChatGPT model tailored to your use case:
1. Gather and Prepare Your Training Data
- Compile a diverse dataset of text content related to your industry or topics. Scrape relevant websites, collect product docs, create custom articles, etc.
- Clean the data by de-duplicating texts, fixing formatting issues, and anonymizing any private info.
- Split your dataset into training, validation, and test subsets.
2. Upload Your Data to an AI Platform
- Use a platform like Anthropic or Cohere to upload your datasets. Make sure to properly label the data splits.
- Select a ChatGPT model architecture like Claude or a GPT-3 model as the base.
3. Perform Additional Training
- Fine-tune the base model on your training split via gradient descent training. Validate on your dev set.
- Consider using techniques like MEMWALKER for long texts.
- For retrieval aug, index texts and integrate semantic search.
4. Evaluate Your Custom Chatbot
- Test your specially trained model on your holdout test set and real-world conversations.
- Analyze the model's recall of key concepts, relevance, and conversational coherence.
- Iteratively improve by gathering more data on weaknesses and retraining.
5. Deploy Your Model
- When satisfied, deploy your custom ChatGPT through APIs offered by AI platforms.
- Set up production instances and integrate them into your apps and business workflows.
- Monitor and maintain the model, retraining as needed on new data.
Real-World Applications of Custom Chatbots
There are endless possibilities for specially trained ChatGPT models in business:
- Customer support bots: Train on your product docs, manuals, and common questions.
- Industry analysis bots: Ingest earnings reports, press releases, and articles to answer financial questions.
- Subject matter expert bots: Teach medicine, law, engineering, etc., by training on textbooks and research papers.
- Company culture bots: Help onboard new hires by training them on internal wikis, handbooks, and messaging history.
As you can see, virtually any industry or niche domain can benefit from a tailored, knowledgeable ChatGPT assistant. The customization unlocks far more relevant conversational abilities aligned with your use cases.
The realm of interactive reading offers a plethora of practical applications. Take, for instance, the Retrieval-Augmented Generation (RAG), which fuses retrieval with text generation. Such models can significantly benefit from MEMWALKER, allowing them to efficiently extract relevant insights from vast collections of documents.
Furthermore, businesses can harness the power of custom AI chatbots integrated with MEMWALKER. This ensures that their chatbots can hold broader, more natural conversations, all while retaining the necessary context.
With the ongoing progression of Large Language Models (LLMs), the potential of interactive reading is only expanding. It paves the way for AI to adeptly manage tasks that demand a rich understanding of context, memory, and logical reasoning.
The Future of Training Large AI Models
Methods like interactive reading point toward more human-like context handling in large language models. As LLMs grow ever bigger, reducing their hunger for data will be critical. Efficient encoding of information also allows tapping into more specialized niche knowledge.
For software teams, learning to effectively train and customize models like ChatGPT unlocks immense opportunities. In combination with techniques like retrieval augmentation, we are steadily moving towards AI assistants that can have meaningful, in-depth conversations spanning a breadth of topics. Exciting times are ahead as models continue getting smarter!
Hopefully, this guide has shed light on productive techniques to train your own ChatGPT bot. With the right data and efficient training approaches, you can create conversational agents specialized for your software business and developers.
Opinions expressed by DZone contributors are their own.
Comments