Transfer Learning in NLP: Leveraging Pre-Trained Models for Text Classification
In this article, we will discuss the concept of transfer learning, explore some popular pre-trained models, and demonstrate how to use them for text classification.
Join the DZone community and get the full member experience.
Join For FreeTransfer learning has revolutionized the field of Natural Language Processing (NLP) by allowing practitioners to leverage pre-trained models for their own tasks, thus significantly reducing training time and computational resources. In this article, we will discuss the concept of transfer learning, explore some popular pre-trained models, and demonstrate how to use these models for text classification with a real-world example. We'll be using the Hugging Face Transformers library for our implementation.
The Emergence of Transfer Learning in NLP
In the early days of NLP, traditional machine learning models such as Naive Bayes, logistic regression, and support vector machines were popular for solving text-related tasks. However, these models typically required large amounts of labeled data and carefully engineered features to achieve good performance.
With the advent of deep learning, models like LSTMs and CNNs started to become popular for NLP tasks due to their ability to automatically learn features from raw text. However, these models still required large amounts of labeled data to achieve good performance and suffered from the issue of vanishing gradients when trained on long sequences.
The introduction of the Transformer architecture by Vaswani et al. (2017) marked a turning point in NLP research. Transformers introduced a novel self-attention mechanism, which allowed models to process long sequences more efficiently and learn contextual representations of words. This led to the development of pre-trained language models, which were trained on massive corpora of text using unsupervised learning objectives like masked language modeling and next-sentence prediction.
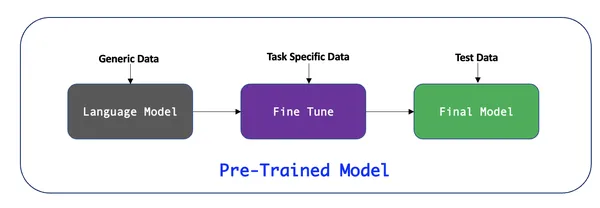
Transfer learning emerged as a popular technique for leveraging these pre-trained models to solve specific NLP tasks with relatively little additional training. By fine-tuning the pre-trained models on smaller, task-specific datasets, practitioners could achieve state-of-the-art results while reducing training time and computational resources.
Popular Pre-Trained Models
Some popular pre-trained models for NLP tasks include:
- BERT (Bidirectional Encoder Representations from Transformers): Developed by Google, BERT is a transformer-based model that has been pre-trained on a large corpus of text using masked language modeling and next-sentence prediction tasks.
- GPT (Generative Pre-Trained Transformer): Developed by OpenAI, GPT is another transformer-based model that focuses on the generative aspect of language modeling.
- RoBERTa (Robustly Optimized BERT Approach): A variant of BERT developed by Facebook AI, RoBERTa improves upon BERT by using dynamic masking and training on more data.
There are also other notable pre-trained models, such as XLNet, ALBERT, and T5, which have their own unique characteristics and are suited for different NLP tasks.
Advantages of Transfer Learning in NLP
Transfer learning provides several advantages over traditional NLP techniques:
- Improved performance: Pre-trained models have been shown to achieve state-of-the-art results on a wide range of NLP tasks, often outperforming traditional machine learning and deep learning models.
- Reduced training time: Fine-tuning pre-trained models on smaller, task-specific datasets can significantly reduce training time compared to training models from scratch.
- Lower computational resources: By leveraging the knowledge learned from pre-trained models, transfer learning reduces the need for large amounts of labeled data and computational resources.
- Broad applicability: Transfer learning can be applied to various NLP tasks, such as text classification, sentiment analysis, named entity recognition, question-answering, and more, making it a versatile technique for practitioners.
Using Hugging Face Transformers for Text Classification
Hugging Face Transformers is an open-source library that provides easy access to pre-trained models and simplifies their fine-tuning for specific tasks. In this example, we'll use BERT for text classification.

First, install the necessary libraries:
pip install transformers
pip install torchNext, let's import the required libraries and download the pre-trained BERT model and tokenizer:
from transformers import BertTokenizer, BertForSequenceClassification
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
Now, let's prepare our dataset for training. For this example, we'll use the IMDB movie review dataset for sentiment analysis. The dataset can be downloaded from here. We will tokenize the input text using the BERT tokenizer.
from transformers import TextDataset
def tokenize(batch):
return tokenizer(batch['text'], padding=True, truncation=True)
train_dataset = TextDataset("path/to/train_data", tokenize)
val_dataset = TextDataset("path/to/val_data", tokenize)Next, we'll set up the training parameters and train the model.
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir='./results',
num_train_epochs=3,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=val_dataset,
)
trainer.train()
#import csvAfter training, we can evaluate the model on the validation dataset and save the fine-tuned model for future use
trainer.evaluate()
trainer.save_model("fine-tuned-bert")
Using the Fine-Tuned Model for Text Classification
Now that we have a fine-tuned BERT model for sentiment analysis, we can use it to classify new text samples:
def classify_sentiment(text):
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
probabilities = torch.softmax(logits, dim=1).tolist()[0]
sentiment = "positive" if probabilities[1] > probabilities[0] else "negative"
return sentiment, probabilities
text = "I loved the movie! The acting was superb and the plot was engaging."
sentiment, probabilities = classify_sentiment(text)
print(f"Sentiment: {sentiment}, Probabilities: {probabilities}")This function tokenizes the input text, feeds it into the fine-tuned BERT model, and returns the predicted sentiment along with the probabilities for each class.
Real-World Applications of Transfer Learning in NLP
Transfer learning has found widespread application in various industries and domains, such as:
- Customer support: Automating the classification of customer complaints or inquiries to route them to the appropriate departments.
- Social media monitoring: Analyzing social media posts to detect trends, sentiments, or brand mentions.
- Healthcare: Classifying medical records and clinical notes to identify potential diagnoses, risks, or treatment options.
- Finance: Analyzing news articles, financial reports, or earnings calls to predict stock market trends and make informed investment decisions.
- Legal: Automating the classification of legal documents for improved organization and information retrieval.
By leveraging transfer learning, organizations can develop sophisticated NLP systems that provide valuable insights and streamline various tasks across these industries.
Conclusion and Key Takeaways
In this article, we explored the concept of transfer learning in NLP, discussed popular pre-trained models like BERT, GPT, and RoBERTa, and demonstrated how to leverage these models for text classification using Hugging Face Transformers. By fine-tuning pre-trained models on task-specific datasets, we can significantly reduce training time and computational resources while achieving state-of-the-art results.
Key Takeaways From This Article Include:
- Transfer learning is a powerful technique in NLP that allows practitioners to leverage pre-trained models, which have already learned useful features from large datasets, to solve specific tasks with relatively little additional training.
- Popular pre-trained models like BERT, GPT, and RoBERTa have greatly contributed to the success of transfer learning in NLP, achieving state-of-the-art results across various tasks.
- Hugging Face Transformers is an open-source library that simplifies the use of pre-trained models and fine-tuning them for specific tasks, such as text classification.
- Fine-tuning pre-trained models on task-specific datasets can significantly reduce training time and computational resources while maintaining high performance.
- Transfer learning has become an essential technique for NLP practitioners, enabling them to tackle a variety of tasks with greater ease and efficiency.
- The versatility of transfer learning allows it to be applied to a wide range of NLP tasks, making it a valuable skill for practitioners to master.
As transfer learning continues to evolve, we can expect more advanced pre-trained models and techniques to emerge, further enhancing the capabilities of NLP systems. By staying up-to-date with these developments and mastering the use of transfer learning, practitioners can ensure that they remain at the forefront of NLP research and applications.
Opinions expressed by DZone contributors are their own.
Comments