Transforming Generative Tasks to Classification Tasks
The cost of large general purpose language models can be alleviated by training smaller task specific classification models which can be more efficient.
Join the DZone community and get the full member experience.
Join For FreeML systems are becoming increasingly powerful, with applications in a wide range of fields. Additionally, ML and NLP systems are being used to improve the quality of information retrieval systems, making it easier for users to find the information they need. This makes it much easier for us to access and understand information from a variety of sources. For example,
- Conversational AI can be used to create chatbots that can hold natural conversations with humans.
- Recommender systems can use NLP to recommend products relevant to a user’s interest.
- Sentiment analysis can be used to identify the emotional tone of text.
The training of many deep learning models requires a vast amount of computational resources, such as GPUs and TPUs. The cost of inference can also be prohibitive for the application of these models in high-performance situations.
Ways To Improve Performance
There are three primary ways to scale the performance of ML models.
- We can simplify the task itself in creative ways.
- Next, we can consider simpler, smaller models when possible.
- Finally, we can use innovative techniques to reduce computational complexity for some decrease in precision.
Of these, the largest gains are often found by creatively redefining the task at hand. For example, if the task is well-defined and not generative, we can design smaller, more efficient models to achieve similar performance.
While larger models help with generative tasks and also with generalization across tasks (aka transfer learning), many times, generative problems can be cast into classification problems that BERT-style models can handle. In other words, if we can narrow the scope of what we want the model to do, we don't need a large model to do it. A smaller model can be just as accurate, and it will be much faster and cheaper to train and run. However, if we want the model to perform a variety of different tasks, then we may need a larger model. This is because larger models may be able to generalize better (aka transfer learning). In some cases, we can even cast a generative problem into a retrieval problem.
Case Study: Customer Support Templates
For example, in the case of support chat interactions, several interactions can be answered from the customer playbook. In this case, it is easier and cheaper to cast the problem as a retrieval problem of finding the template that best satisfies the user.
Collecting Training Data
The first step is to split the customer service log by turning it into a list of questions and responses. This means that each turn in the conversation is broken down into its individual parts, such as the customer's question and the agent's response. Once this is done, the next step is to match the questions and responses against an existing playbook repository. A playbook repository is a collection of pre-written responses that can be used to answer common customer questions. By matching the questions and responses from the customer service log against the playbook repository, the system can identify which pre-written responses are the most likely to be helpful in resolving the customer's issue. This process can help to save time and improve the efficiency of customer service.
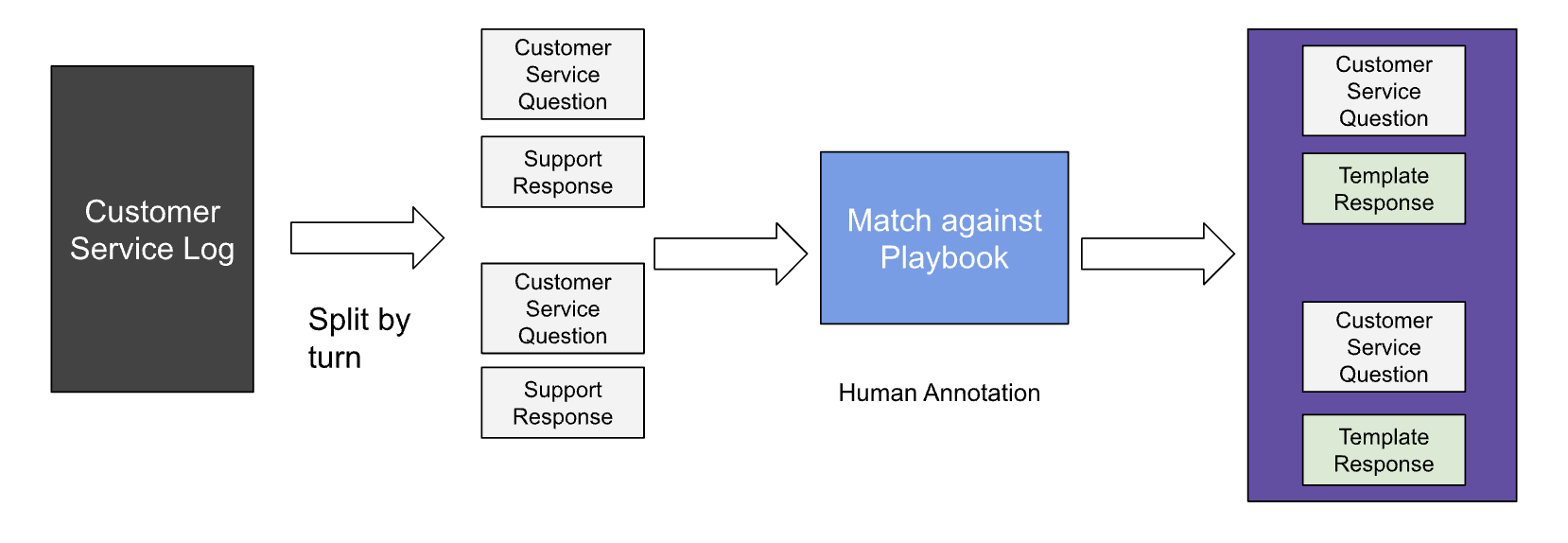
Stage 1: Collecting Training Data Set
Alternatively, one can use LLMs to make this step easier. Using few-shot prompts, one can match against the correct template response for each customer service interaction. LLMs can be used to match customer service interactions to the correct template response by providing the LLM with a few examples of customer service interactions and the corresponding template responses. The LLM will then be able to learn to match new customer service interactions to the correct template responses. This can save customer service representatives a lot of time and effort, as they will no longer have to manually search for the correct template response for each interaction.
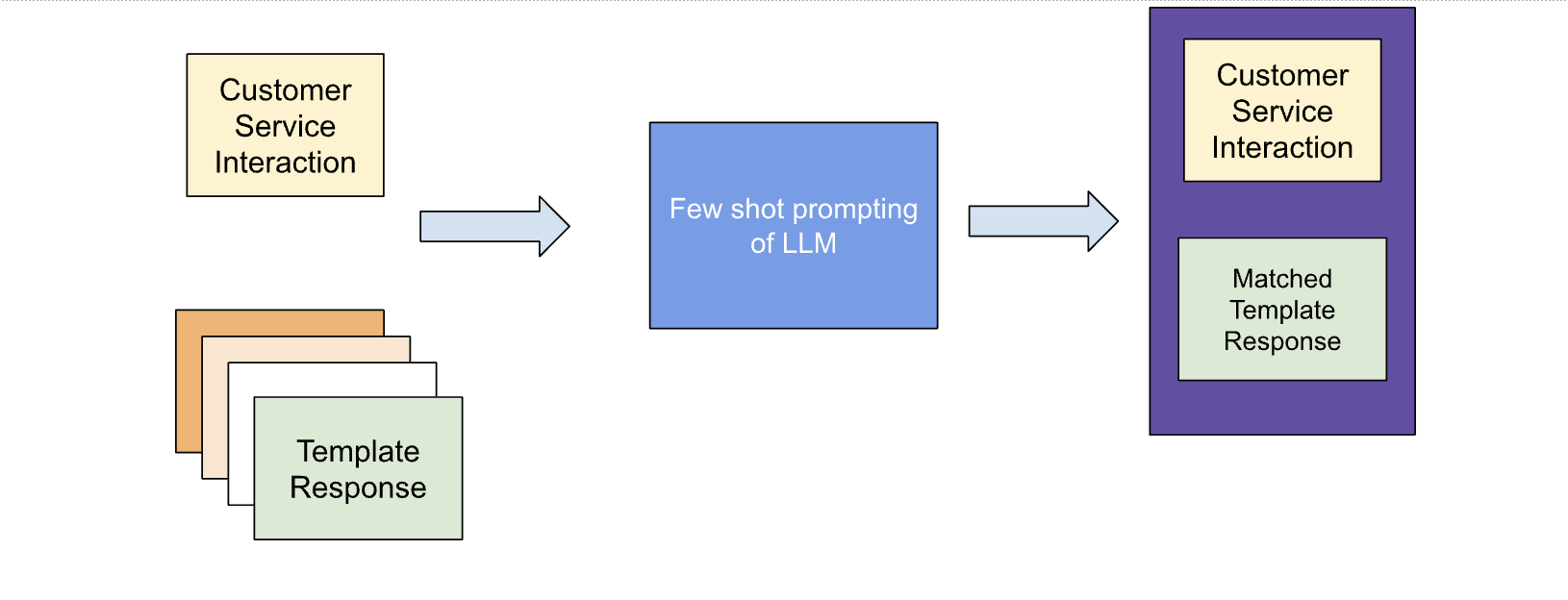
Collected training data in this manner has several advantages:
- It is offline, meaning that it can be done at training time without any access to user requests.
- It is small in size, which means that it can be stored and processed easily. This is important for training machine learning models on devices with limited storage or processing power.
- It can be used for classification tasks with high accuracy. This is because the data is collected in a controlled environment, which reduces the amount of noise and error in the data.
Training Classification Models
We can train a classification model in three steps:
- Set up tasks by exploding retrieved template responses. This means breaking down the template responses into their individual components, such as words, phrases, and entities. When exploding retrieved template responses, you need to be careful to avoid choosing irrelevant templates.
- Encode interactions and templates using SentenceBERT, Word2Vec, etc. This means representing the interactions and templates as vectors of numbers. When encoding interactions and templates, you need to select an encoding technique that preserves the semantic meaning.
- Use a simple, cheap ML model to predict the best template. The model can even be a simple DNN. When using a simple, cheap DNN to predict the best template, you need to choose a DNN that is appropriate. For example, for complex classification, you might want to use a DNN that has been trained on a large corpus of text.
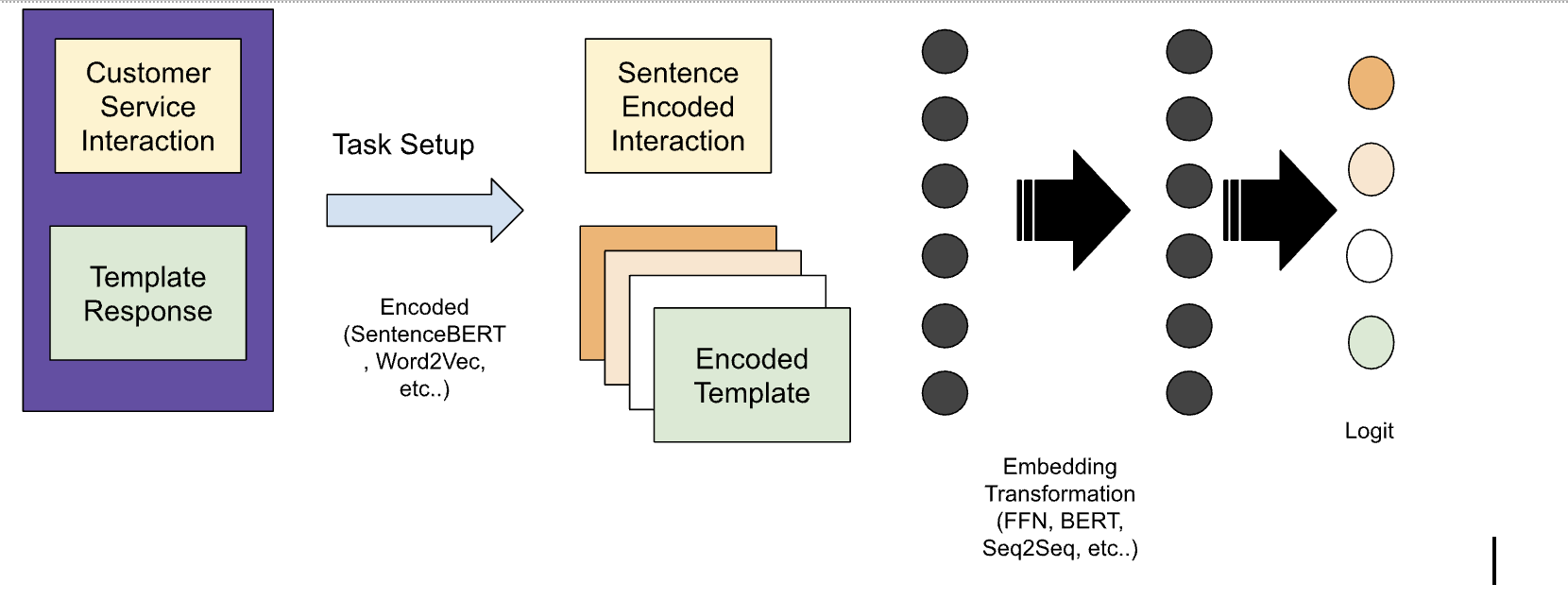
The advantages of this classification model are that it has low training costs and is cheap to serve. It is also very easy to re-train the model and even more explainable than using deeper, larger models.
In fact, the learned model need not be DNN. It can also be a random forest (XGBoost-based classifier) that has even more advantages in execution speed and training ease. The advantages of this classification model are:
- Low training cost: This model is relatively inexpensive to train compared to other models, such as deep neural networks.
- Cheap to serve: This model is also relatively inexpensive to serve once it has been trained.
- Easy to retrain: This model is easy to retrain if new data becomes available.
More explainable than deeper larger models: This model is easier to explain than deeper larger models, which can be helpful for understanding how the model works and why it makes the predictions that it does.
In fact, the learned model need not be a DNN. It can also be a random forest (XGBoost-based classifier that is known for its speed and accuracy) that has even more advantages in execution speed and training ease. Each decision tree is trained on a different subset of the data, and the predictions from the individual trees are then combined to make a final prediction. This approach can be very effective for classification tasks, and it can also be very fast to train and serve.
Overall, the advantages of this classification model make it a good choice for a variety of applications. It is relatively inexpensive to train and serve, it is easy to retrain, and it is more explainable than deeper, larger models.
Opinions expressed by DZone contributors are their own.
Comments